Hierarchical data
Pentaho supports a hierarchical data type (HDT) by means of the Pentaho EE Marketplace hierarchical data type plugin that adds the data type and creates five steps. These steps are designed to simplify string manipulation, with the ability to convert between HDT fields and formatted strings.
These steps improve performance on the steps that that treat hierarchical representations in string fields and enable you to address or modify nested array indices and keys. This data type can hold nested or complex data that is built by using objects and arrays and can also hold single elements. It can be used with any PDI step that uses hierarchical data.
The steps are:
- Modify values from a single row
- Modify values from grouped rows
- Extract to Rows
- Hierarchical JSON Input
- Hierarchical JSON Output
Of the five steps, the first three steps have been created to manipulate generic hierarchical data and the last two steps work with data in the JSON format. The first two steps are used to create or modify hierarchical data, and the third step is used to deserialize the data. A common use for these steps is described in the following table:
| Step | Usage |
| Modify values from a single row | You can take one row of data from an incoming step and then use that to either create a new hierarchical data type or modify a hierarchical data type that's on that incoming data stream. |
| Modify values from grouped rows | You can take multiple rows of data, group them based on a common field or set of fields, and then create a new hierarchical data type or modify and existing data type. |
| Extract to Rows | You can take data out of the hierarchical data type and place it onto the PDI data stream and use the data with other steps. |
The last two steps are specifically for working with JSON and JSON Lines (JSONL) files. Differences between the Hierarchical JSON input step and the JSON Input step are:
- The JSON input step uses the JSONPath path specification, the Hierarchical JSON input step uses an HDT path specification.
- The JSON input step reads the entire JSON file into memory, the Hierarchical JSON input step processes the JSON as an input stream and loads only the specified content . You can load filtered subsets of large JSON files, or separate lines from a JSONL directly into a HDT field for extraction or modification by other steps.
- The JSON input step loads content onto multiple fields of a stream, the Hierarchical JSON input step has filters you can apply to fetch the subset of a JSON file.
| Step | Usage |
| Hierarchical JSON input | You can read an entire JSON file into memory and send it to a single HDT field on the steps output field. You can use the Split rows across path option on the Output tab to extract each JSON parent to a row, allowing you to process the data in blocks and reduce the amount of memory needed for processing the data. |
| Hierarchical JSON Output | You can convert hierarchical data to a JSON file and write it to an output field or pass the output to a PDI servlet. |
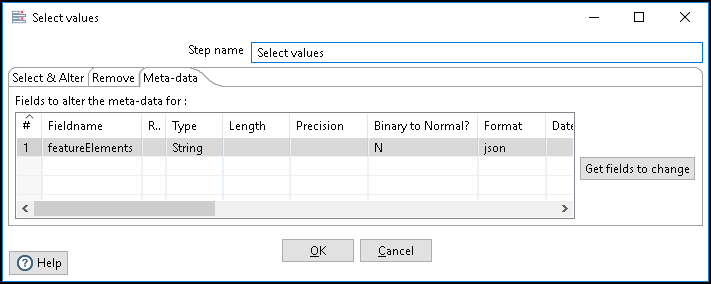
You can convert data between JSON and HDT types with the Type and Format field options in steps that support HDT. In the following example, the Select values step is set to convert hierarchical data to JSON:
Hierarchical data path specifications
The Hierarchical data path (HDT) path specification for extractions is different than the specification for modifications. Each specification is described below.
The HDT path specifications for extractions are:
- You must always start with the dollar sign (
$) for the root. - Simple alphanumeric key values are separated by periods (
.). - Numeric indices are designated like arrays with square brackets
[ n ]. - Complex string identifiers are designated with single quotation marks in square brackets
[‘Complex string identifier’]. - If your identifier has a special characters like a single quote mark, you must escape that character with a backslash (
\). For example['\‘Complex string identifier\’']. - You can use the asterisk (*) wildcard for string or numeric keys.
For example: $['l am a perfectly'].normal[0].example
The HDT path specifications for modifications are:
- There is an additional array push operator of square brackets
[ ]when added to the end of an array that will create an index. - There are four special reference quote marks that you can use:
$[?string_field?]- Takes the string value of a field from an incoming PDI row and uses that value as the map key fragment.$[#numeric_field#]- Takes the numeric value of an incoming PDI field and uses the value for array or list access with a resolved numeric index.$[$string_backreference$]– Matches the string key fragment from a previous paths segment.$[@numeric_backreference@]- Matches the numeric array or list index from a previous paths segment.
$.first[ 4 ][‘hello’], the $1$ = ‘first’, @2@ = 4, $3$ =
‘hello’. The backreference is a 1-based index, and the surrounding $ or @ specifies if a string or numeric value was used.