Field browsing

In Lumada Data Catalog, view the field details to see the resource field-level metadata along with Data Catalog's data analysis, discovered and seeded or accepted field tags, cardinality for fields, and sample values. To show metadata in the resource field, you need native access to the resource or metadata level as governed by the RBAC settings for your user role.
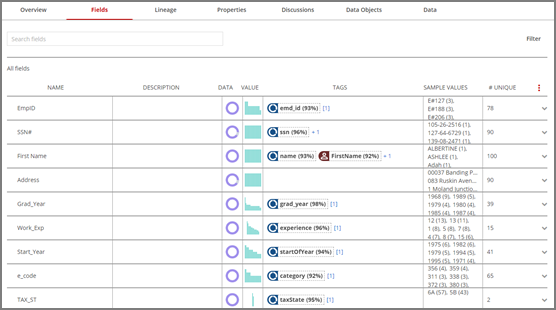
You can use the Search feature to browse the fields list for a field name. Click the Filter button to narrow the search by field tag, cardinality, selectivity, density, data type, or field tag sensitivity.
Data Catalog offers rich fields metadata in graphical formats like donut charts, value histograms, and unique value counts to help you to quickly analyze data. Data Catalog also provides quality metrics and sample values in addition to profiled samples. You can view both the specific data values Data Catalog shows for only the 20 most frequent values from each field and the quality metrics such as maximum, minimum, and standard deviation calculated on all field values during profiling.
Field data types
When fields in your HDFS files are not strongly typed, as in the values in JSON or CSV files, you need to review the data to determine the data type. Lumada Data Catalog completes this step for you. The Data column for each field shows a graph indicating the determined data type and frequency. Clicking the graphs in the Data or Value columns reveals more information about the metrics.
In the Data column, data statistics are shown in a donut chart.
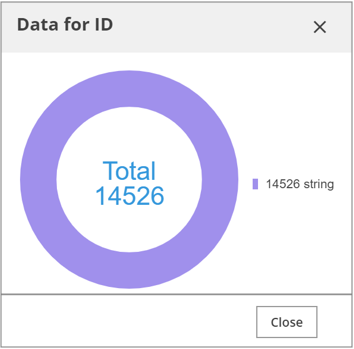
The donut chart specifies how much of the data are null values and shows the data type. The data types are color-coded according to type as shown in the table below:
| Data Type | Color Code |
| Integer Data |  (blue) (blue) |
| String Data |  (violet) (violet) |
| Date/Timestamp Data |  (orange) (orange) |
| Binary/Boolean Data |  (green) (green) |
The Value column indicates the value distribution in each field with a frequency graph.
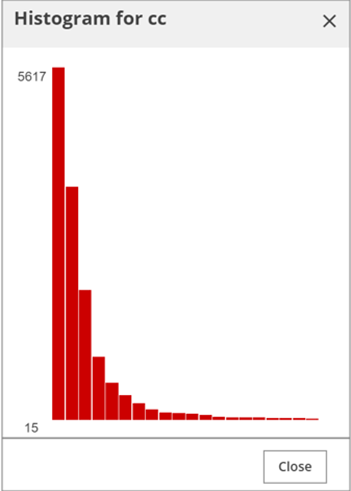
The frequency graph indicates the number of times a given value appears in a data sample. The Value field in Field View shows the 20 most frequent values for that entity.
Mixed data types
Lumada Data Catalog assigns the mixed data type to a given field after examining the data in that field. This feature is controlled by a flag in profiling for number and date formats and is described in Managing configurations in the Administration Guide.
The following donut chart shows the mixed data types.
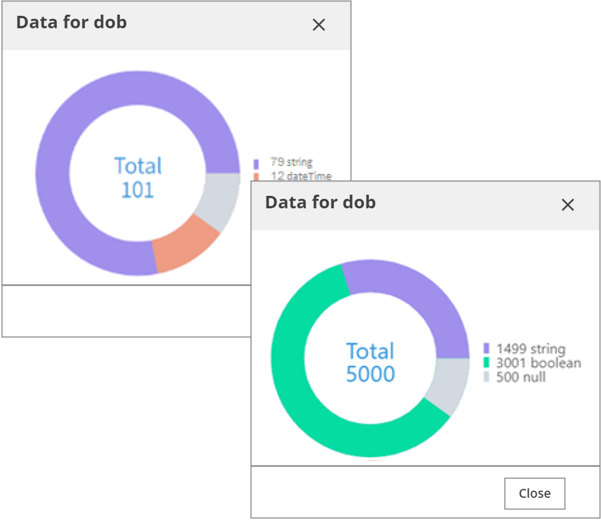
For example, you may have a dob data chart. One of the discovered data type resources in the Data field is string, but the donut chart displays two
different inferred data types: string and Boolean. In the dob field for another resource, the discovered data type is string and the donut chart displays that Data Catalog infers both string and dateTime data types. Examining the corresponding sample values reveals that all values have some
sort of date format.
Data Catalog relies on the Spark engine to interpret the dateTime data type defined by the locale, so only those that satisfy the locale definition get identified as dateTime, while the rest are considered string data types.
Data type profiles
Lumada Data Catalog collects data type information for each field. Since many HDFS files store data as strings, Data Catalog also reviews the data values to discover a more accurate description of the data type.
To open a data type profile, do the following:
- On the Fields tab of the profile, navigate to the field you want to profile, and click the down arrow at the end of the row to display a drop-down of the data profile for that entry.
Patterns tab
Displays the common data patterns as profiled by Data Catalog, and frequency in the form
NN-AN-AAAA. Special separator characters are also included, such asNfor a numeric character andAfor alphanumeric.You can configure the length of the pattern. For example, you can truncate any pattern greater than the value set by this property by adding ‘…’. Contact your Data Catalog system administrator for details.
Sample Values tab
Shows the top 20 most frequently occurring values for that field along with the frequency.
Text names and values are truncated after 256 characters. If your data includes strings that have only numbers, such as zip codes, Data Catalog displays the values as numbers without leading zeros.
If your user role has administrative privileges, you can configure these values. If not, contact your administrator for details.
Both the Patterns tab and the Sample Values tab are divided visually to display the most frequent top and bottom frequency distributions. By default, these frequency distributions are limited to six, three top and three bottom values, but you can configure the distributions using ldc.web.pattern_top_and_bottom_k.count. To view more patterns and values, click the scroll feature to open a pop-up screen that displays all patterns and values with the number of occurrences. Click the column headers Values or Occurs to sort for frequency.
Data Profile column
Shows data profile attributes for the selected data set:
Feature Description Type String, Integer, Timestamp, Date, Boolean, or Binary. NoteDate and Boolean profiles appear when original or discovered data types are displayed.Min The least frequently occurring value. Max The most frequently occurring value. # Unique Number of unique values of that data set. Selectivity Ratio of cardinality to the total number of values in the field, that is, the percentage of unique values. Cardinality is calculated as the number of unique values in this field. Low cardinality and selectivity values indicate that there are many repeated values in the field, such as state fields in data with addresses. A key in a table would have high cardinality. These field characteristics are important when selecting a good seed for tagging. For more information about cardinality, see Cardinality and selectivity calculations. Values Total number of records in that file. Nulls Number of entries that are null. Density Number of values in the field relative to the number of rows. Low density indicates that many rows are missing data for this field. Field Properties column
Shows field property attributes for the selected data set:
Feature Description Name This column shows the following: - Name and number of current field you are exploring: _c0 is the second field in the file.
- Label: Click the Label link to customize the field label.
- Tag counts tells you the number of identified tags: either suggested or accepted/tagged.
Label This custom label is used to rename the field. It is especially useful with files or tables that lack headers or have different names for the same functionality. Note that the field name immediately assumed the set custom label. The Name field will show the original field name that was retrieved from the resource metadata. To rename the label:
- Click the Label to change the field name link.
Field number Sequential field numbering. Tag count Number of tags associated with the field. Tags Lists associated tags. Description (custom comments) You can use custom comments to add annotations about the field, such as acceptable usage guidelines or definitions. Once defined, these custom labels and comments are searchable.
You can only edit or update custom labels and comments if you have administrative or steward privileges.
Comments These comments are displayed under the Description field in the field details pane and also in the Field Properties column. Imported comments differ from custom comments in that you cannot edit imported comments in the window. They are either imported from Hive/JDBC comments when processing these resources or via API calls for non-Hive/JDBC resources.
Cardinality and selectivity calculations
Lumada Data Catalog calculates cardinality based on a data subset in the field. The result is an approximate value that is less accurate if the number of unique values in the field is more than 2000. This "tipping point" of 2000 values can be configured by your Data Catalog administrator.
When fields include more than one type of value (all numbers or a combination of numbers and letters), the data profiles apply from the perspective of one data type. For example, the text profile shows statistics calculated with only the text values and indicates the non-text and null values.
Cardinality and selectivity for a certain data type show what part of the total field values are of that type.
The sum of cardinality across all data types is the number of values in the field.
The sum of selectivity across all data types is 1.