Single resource view details

Lumada Data Catalog applies AI holistically across the product to uncover a range of embedded, contextual information about the resource, which can now empower the business data analyst to make educated decisions. In Lumada Data Catalog, the single resource view (SRV) offers detailed insights into resource metadata and a glimpse into resource data. Data analysts and data stewards can add business tags and labels on resource data at the SRV level.
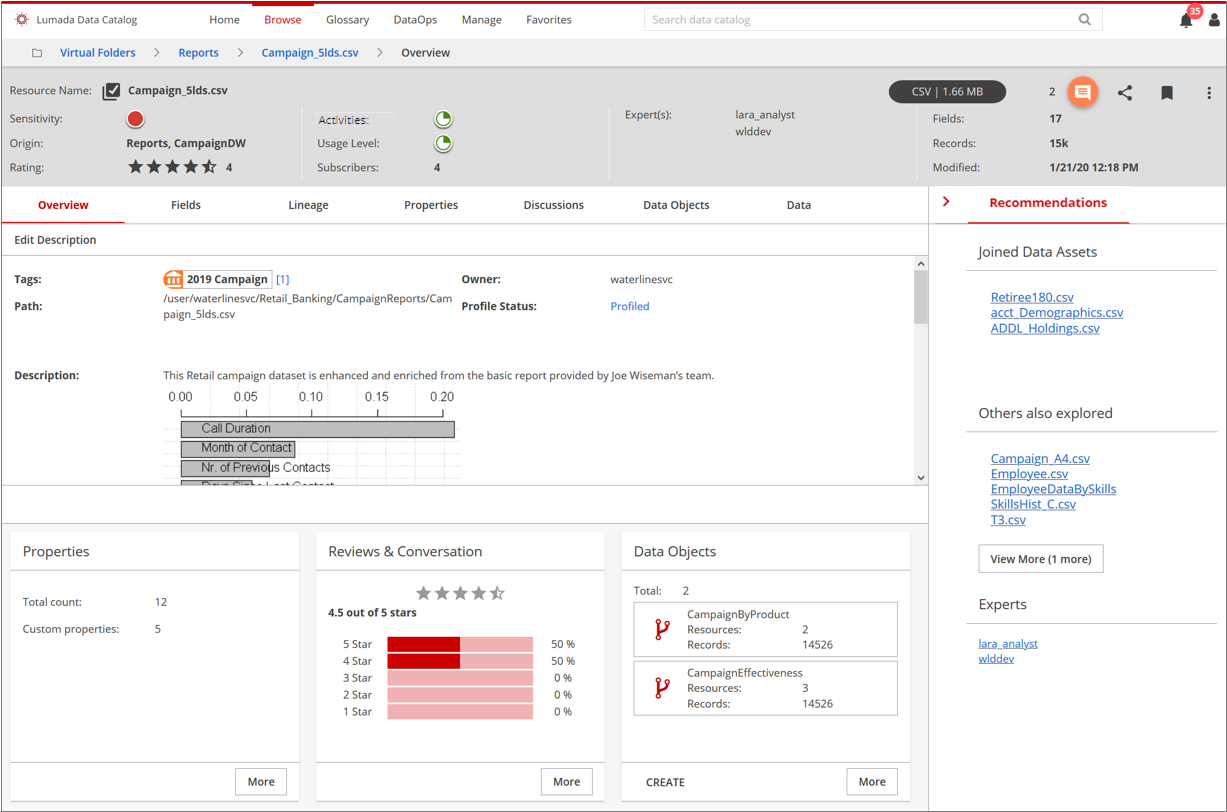
The following sections provide details on the SRV experience.
SRV key metrics
When you view a single resource, a banner displays the key metrics and resource metadata. The banner is intended as a single place where you can gain enough insight into the resource to make quick decisions. The processing engine discovers the resource metadata and the AI engine calculates other data.

For example, when you request access to a resource, a high-sensitivity level will promptly warrant a thorough check of the permission and access levels of your user role.
The resource contains the metadata information from the discovered data source, such as the resource name, size, fields, records, modified timestamp, and origin.
In addition, Data Catalog contains a few additional metadata attributes on a resource. The new attributes are Sensitivity, Usage Level, Activities, Subscribers, and Experts. The AI engine uses these attributes to provide a deeper insight into the resource. Each of these discovered and calculated attributes are described below.

Resource Name
Discovered attribute uniquely identifying the resource in a data source.
Sensitivity
Computed metadata attribute that identifies the sensitivity of the resource. The sensitivity is based on the highest sensitivity level of any tag (field or resource) associated or suggested on the resource. If the AI engine identifies a single tag with high sensitivity, the resource sensitivity is automatically set to high (High Sensitivity icon).
Five sensitivity levels are defined for tags as follows:
Level Icon Description High 
Identifies highly-sensitive data for personally identifying information (such as bank account numbers, SSN, PAN, credit card numbers, and employee IDs.) Medium 
Information with medium sensitivity like names, addresses, and marital status. Low 
Information that may be personally identifiable but with lower sensitivity. Unknown 
A resource that Data Catalog needs to process to determine sensitivity. Non Sensitive 
A resource the AI determines is not sensitive because there is no sensitivity label associated with that resource after processing and tag curation. Origin
Identifies the sources of the data for the resource. It is possible for a resource to have multiple origins. Origin is a discovered attribute from the discovery jobs of Lineage Discovery and Origin Propagation.
Rating
Highlights the popularity of the resource based on the overall user ratings. It is a computed property averaging all the ratings.

Activities
A computed attribute measuring how well this resource is curated in terms of content updates performed on the resource like description, lineage, tags, reviews, and discussions. The amount of the Activities icon that is filled indicates the level of curation, as follows:
- Empty: No curation
- Quarter (¼): Curation level is less than 10.
- Half (½): Curation level is between 10 and 30.
- Full: Curation level is more than 30 and is considered high.
Usage Level
Indicates the number of times the resource was provisioned by Hive view generation or was opened in a third-party plugin using the Open With option on the single resource view (SRV). It is a computed property. The amount of the Usage Level icon that is filled in indicates usage level, as follows:
- Empty: No usage
- Quarter (¼): Usage level is less than 2.
- Half (½): Usage level is between 2 and 5.
- Full: Usage level more than 5 and is considered high.
Subscribers
A computed attribute that indicates the total numbers of users who have this resource bookmarked as a favorite.
Expert(s)
Users designated by an admin as an expert for the resource. Experts are expected to know the resource data details, its application, and the implication of any changes being done on the resource. The list of experts is a computed list.

File Type and Size (capsule)
Discovered metadata indicating the volume in bytes occupied by the resource on the data source.
Fields
Discovered metadata indicating the total number of fields and columns in the resource.
Records
Discovered metadata that includes the total number of records and rows in the resource. For datasets and data objects, it reflects the sum of the records of the member resources.
Modified
Discovered metadata indicating a timestamp of the last modification performed on the resource.
New Post (icon)
You can post comments or queries about the resource to collaborate with other users by clicking the New Post icon. This is a shortcut to the Reviews sub-menu. The count to the left of the icon indicates the number of existing posts for the resource.
Share Resource (icon)
By clicking the Share icon you can share a link to the current resource with other users in the Data Catalog for collaboration. The Share dialog box includes a link to the resource that you can share independently through other means of communication such as text, chat, and email. You can enter user names or emails with whom to share the resource, along with a message to accompany the share request.
The users with whom the resource is shared receive a notification to access the resource.
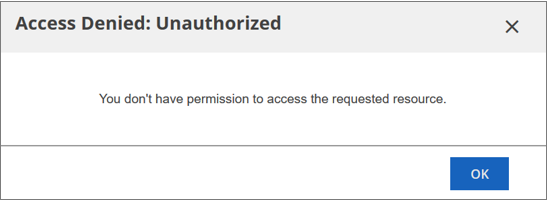
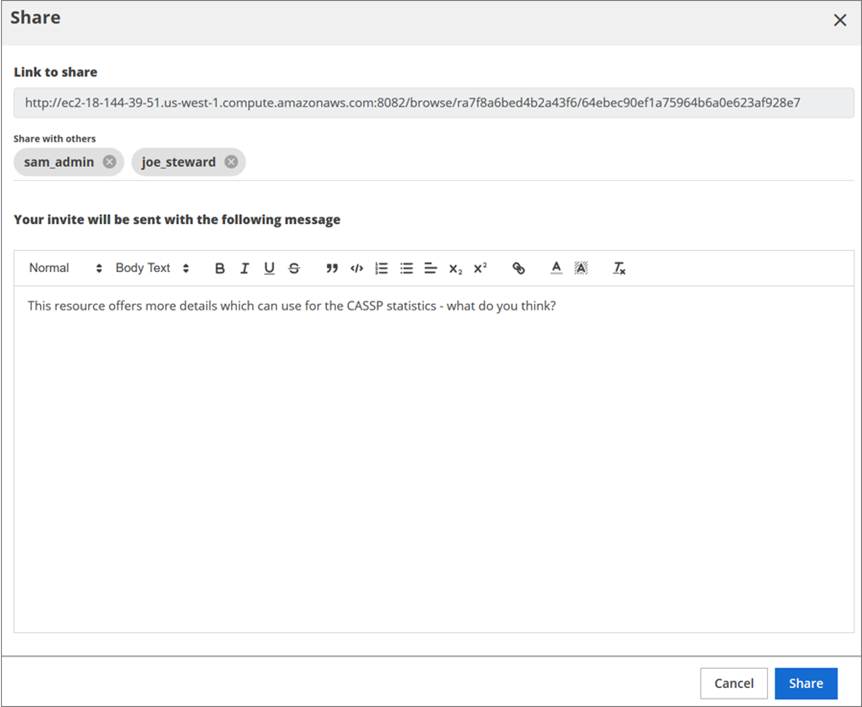 NoteIf you do not have permissions for the resource that is shared with you, you cannot access that resource.
NoteIf you do not have permissions for the resource that is shared with you, you cannot access that resource.In our example, the user cannot access the resource that is shared with them, so they receive the following message when accessing the shared resource.
Add to favorites (icon)
You can mark a resource as a favorite by clicking the Add to favorites icon for a quicker future reference.
More actions (icon)
This menu lists the actions that can be performed on the resource. The actions in the More actions menu vary depending on the asset type. The following actions are offered for resources:
- Add tag: Add resource tag.
- Run job now: Opens the Run Job menu that further can trigger Template jobs or Sequence jobs. See Managing jobs for more information.
- Export to CSV: Exports the resource metadata, including the description and field metadata to a CSV file stored locally in your machine.
- Generate Hive table: Will generate a Hive table for a CSV file. This action is computed towards the curation level calculation. To be able to generate a Hive table for a resource, you must have access to a Hive database in the Hive data source added in the Data Catalog.
SRV overview tab
The Overview tab on the single resource view (SRV) offers detailed information about the resource, like the path details, associated and suggested resource tags, profiling status, resource owner, and description of the resource. In addition to these details, the Overview tab also may include basic information from other tabs on the screen, including Fields, Lineage, Properties, Discussions, Data Objects, and Data.
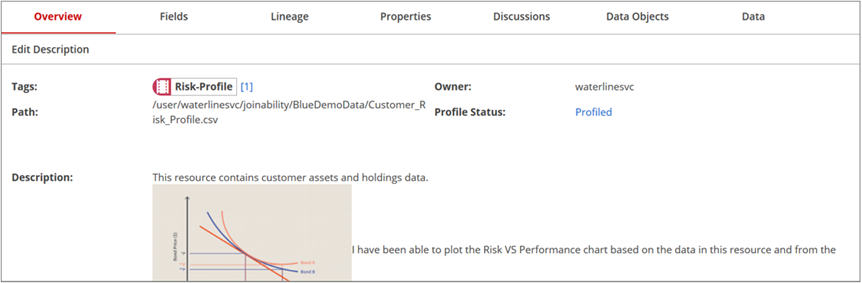
Resource metrics
The Overview tab of the single resource view (SRV) provides the following resource metrics:
Tags
If no tags are associated with a resource, the + Add Tag Association link opens an Add a Tag dialog box so you can add tags on the resource. Both associated and suggested tags are listed with any "overflow" tags indicated by an overflow number link. Click this link to display all the tags in a separate dialog box.
Path
Shows the path of the resource relative to the data source to which it belongs. The path corresponds to the navigation breadcrumbs shown above the Key Metrics banner. You can navigate to any level of the hierarchy simply by clicking that level in the navigation breadcrumbs.
Type
Identifies the type of the resource, such as CSV, JSON, AVRO, XML, ORC, PDF, or TXT.
Owner
The owner of the resource as identified in the native system.
NoteS3 resources do not have Owners as S3 does not support "Owner" concepts.Profile Status
Lists the resource profile status of jobs that run on the resource and the timestamp of the last run. If you click the status, more information displays in a Job Status dialog box:
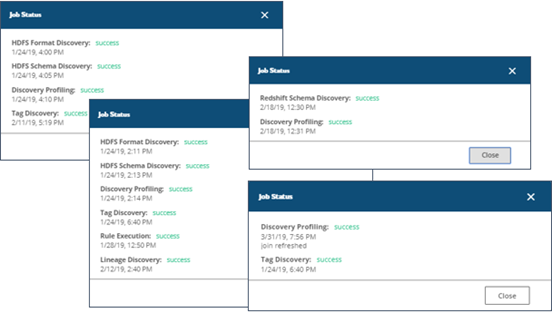
Statuses include:
Profiled
The discovery job(s) ran successfully.
Failed
The discovery job failed due to several possible reasons, including because you did not have access to that resource or the Spark job failed. Data Catalog lists the best possible reason for failure in the Job Status dialog box. If it is not clear as to why a particular job failed, contact the administrator. The administrator can access the job logs file maintained by Data Catalog to determine the reason for failure.
Skipped
The discovery job was skipped because the collection was discovered, Data Catalog could not determine the resource type, or it is not supported by Data Catalog.
Issues
When a Spark job cannot complete the job due to known or unknown reasons, which are listed in the Job Status dialog box.
Unprocessed
When no Data Catalog job has processed the file yet.
Sample-profiled resources
In Lumada Data Catalog's browser, you can identify resources that have been sample-profiled and other resource-level information.
If a large resource is profiled with the -sample parameter, the Overview tab identifies it as sampled. The Profile Status details also identify this resource as sample-profiled and lists the number of rows that were used for sampling.
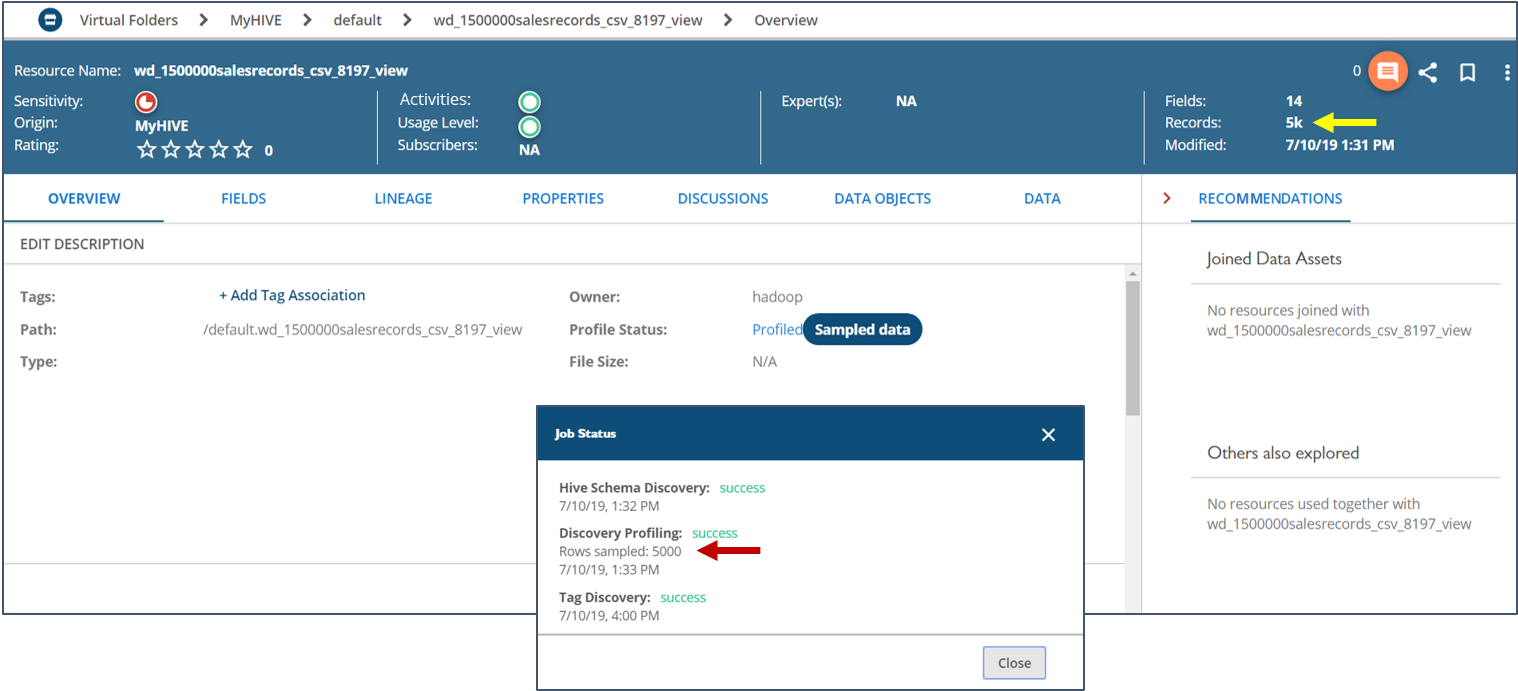
When you drill down to the resource view, you see the sample notification next to the name of the resource. Hovering your cursor over the notification displays the message that the data asset was sampled to determine the footprint due to the large data size. For example, the Records field which normally identifies the number of records in that resource, will instead reflect the sampled number of records. This value also displays as Rows sampled in the Job Status dialog box.
Description
You can use the Overview tab to contribute resource information to the knowledge base, to write content using rich text formatting, and to include links to other articles in Lumada Data Catalog. You can also access and communicate the usage history of the resource.
To edit a description, click the Edit Description panel label (which is also a link) on the Overview tab.

You can use rich text formatting in the Edit Description dialog box for content with formatted text (with font style, size, color, bold, and italic), mathematical formulas, code blocks, highlighting, quote blocks, links, and inline images. You can also use the description text in a search string to search Data Catalog for resources containing similar strings.
Properties pane
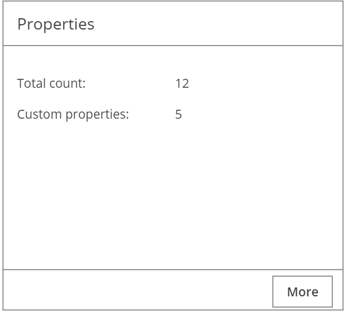
Lumada Data Catalog discovers seven resource properties by default. The number of custom properties defined is listed separately and included in the Total count. The Properties pane summarizes the Properties tab by listing the total properties, including the total number of default and custom properties.
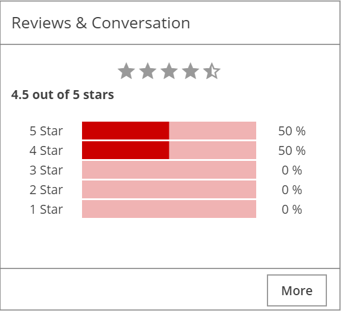
Reviews and Conversation pane
The Reviews & Conversation pane summarizes the Discussions tab. It also displays the average rating of the resource and is a fair indication of the popularity of the resource, regardless of a low or high rating. A low rating highlights an issue with the resource, such as having incomplete data.
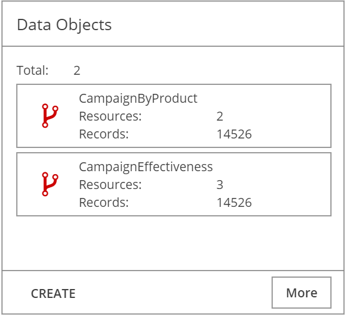
Data Objects pane
If the resource is part of a data object, the data object summary is listed in the Data Objects pane associated or linked to the resource. If you have permission, you can also initiate data object creation by clicking CREATE.
Recommendations
Lumada Data Catalog uses the collected metadata and data knowledge of the data lake by harnessing recommendations with machine learning to provide you with resource context-specific references and suggestions.
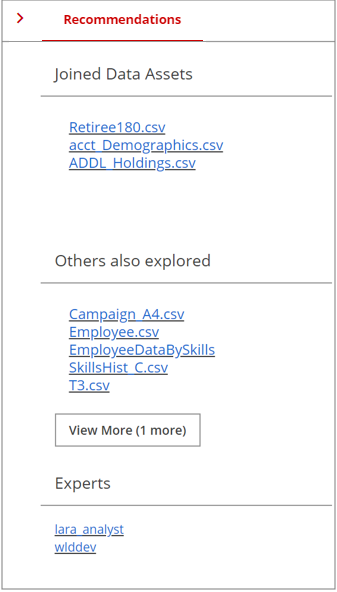
When you use this resource, you also have access to other resources, of which the top five resource suggestions are shown. If the resource is a part of a data object, then other resources are joined to this resource, of which the top five joined resources are shown.
When you work on any resource, the Recommendations feature provides intuitive reference about the community interests associated or relative to that resource. If other users who worked on this resource also worked on another resource, the top five explored resources are listed under the Others also explored section.
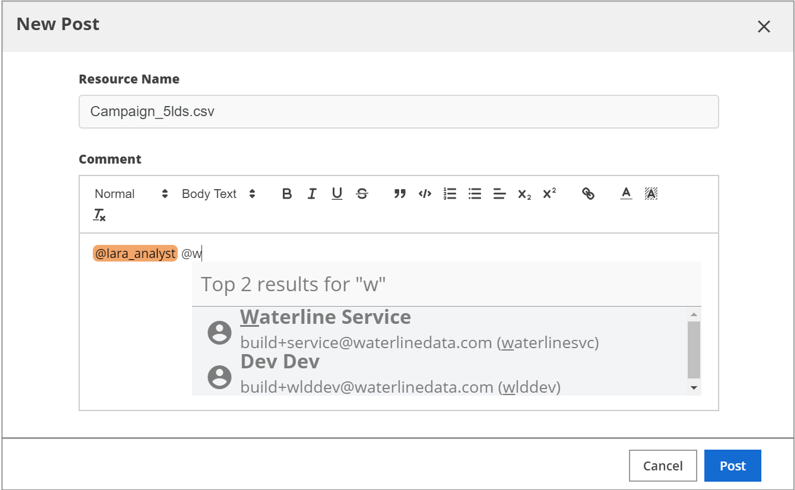
If you want more information about the current resource, you can directly ask the Experts if any are listed for that resource. Just click the expert name and the New Post dialog box opens with an @ mention to the expert. You may add more users using @ mentions to address other users.
The image below shows a new post entry in the discussion and all users listed using @ mentions. All users listed are also sent a notification.
Bookmarking resources
In Lumada Data Catalog, you can add a resource as a Favorite. In the upper-right area of the resource banner, click the Add to Favorites icon for a file, table, database, or folder to include as a resource in your Favorite list. You have easy access to bookmarked resources from the Favorites dashboard menu. Bookmarks are private for each user role and are stored individually.
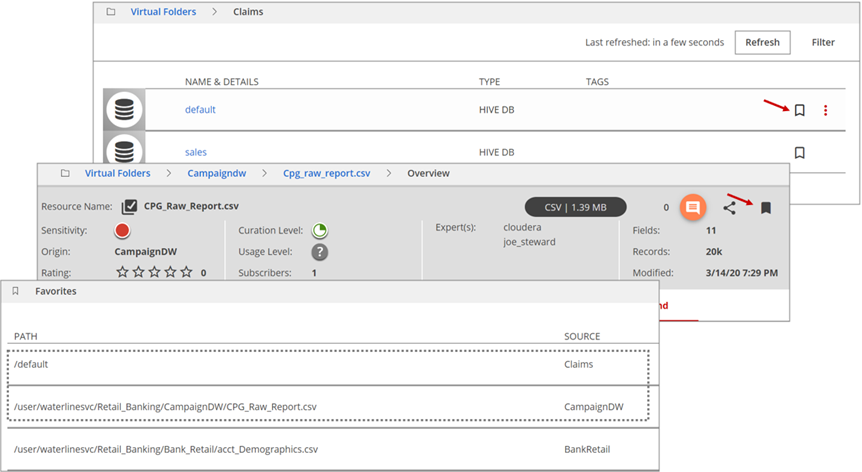
To bookmark a resource for easy reference, click the Add to Favorites icon where it appears in the list view or in the single resource view. You can only bookmark data objects from their Profile View.
To delete a bookmark that is no longer useful, click the bookmark again in the Favorites menu or in the resource or folder list view and click the Remove from favorites icon to remove it from the Favorites menu.
Export your findings to a CSV file
Perform the following steps to export your findings to a CSV file.
Procedure
Click Export as CSV or Export Table as CSV to start generating the export data.
The Export CSV Settings dialog box displays.Select which properties to export for each resource. Click Select All to include all the properties listed.
Click Export to generate the data.
After the CSV data values are successfully generated, a confirmation message appears in the header with an exports link.If you are ready to download the generated information at this point, click exports in the header message.
The Exports page opens. This page provides a summary of your exported reports, including the report name, the report type (from where is was generated), the generation interval, and the report size. Any report listed here is automatically deleted within seven days from the time the report is generated.NoteIf you want to wait until later to download the generated CSV data, you can access the Exports page through the Exports option in your User Profile menu.From the reports table, click More actions, and then select Download report.
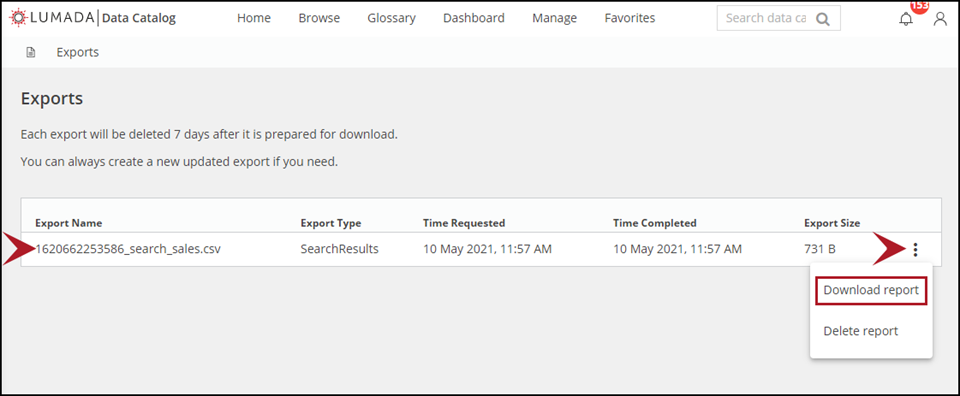 The generated CSV file is downloaded to the location specified for the
Path to exports configuration property during your
installation of Data Catalog. See Managing configurations if you need to reconfigure the Path
to exports property to a different location.
The generated CSV file is downloaded to the location specified for the
Path to exports configuration property during your
installation of Data Catalog. See Managing configurations if you need to reconfigure the Path
to exports property to a different location.(Optional) To delete a report, click More actions, and then select Delete report.
Results
Generating Hive tables
You can use the Hive table generation feature in Lumada Data Catalog to generate Hive tables from other resource types. The supported file formats for generating Hive tables include the following types:
- AVRO
- CSV
- ORC
To create Hive tables from Data Catalog, verify the following conditions:
- The Hive server is updated with Data Catalog JAR files.
- Your active user role has authorization for at least one available Hive database in Data Catalog.
- Your user role generating the Hive table has system-level WRITE access to the folder or directory containing the resource for the Hive table being generated.
Generate a HIVE table
Procedure
Navigate to the detailed resource view.
Click More actions in the upper-right banner and select Generate Hive table from the drop-down menu that displays.
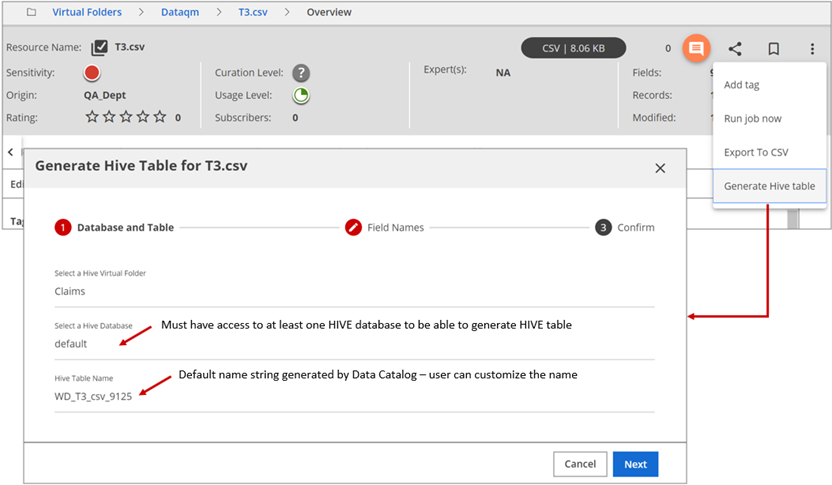 Data Catalog picks a default name for the Hive table to be
generated. You can customize this field with a name of your choice.
Data Catalog picks a default name for the Hive table to be
generated. You can customize this field with a name of your choice.Select a Hive database to save the new table. Start typing the name of the database in the field and select the best match from the list that displays. Only databases accessible to your role will be listed. Click Next.
In the Field names dialog box, you may choose to keep the suggested tags for field names if the resource has been processed in the tag propagation, enter your own custom names, or use the field names from the resource itself. Click Next.
On the Confirm page, verify your selections. Click Generate Hive Table.
Results