Manage Datasets

In Lumada Data Catalog, you can create datasets from groups of resources which have the same schema and span different folders of your data lake into a single virtual unit for easier management. Datasets are user-defined virtual collections that have matching schema, but may have different path specifications and hierarchies for physical locations in your data lake, regardless of their data source type.
Data Catalog identifies datasets based on the following attributes:
Dataset Name
The name of the dataset, specified at the time of its creation.
Dataset ID
A unique string identifier associated with the dataset.
Schema Version Number
An integer that identifies the version of the reported schema.
To manage datasets, navigate to Manage, then click Datasets.
Data Catalog provides a rich set of REST APIs for you to include datasets in your automation environment. See the REST API documentation for REST API syntax and usage samples.
Create a dataset
Perform the following steps to create a dataset:
Procedure
Navigate to Manage, then click Datasets.
Click Create a Dataset.
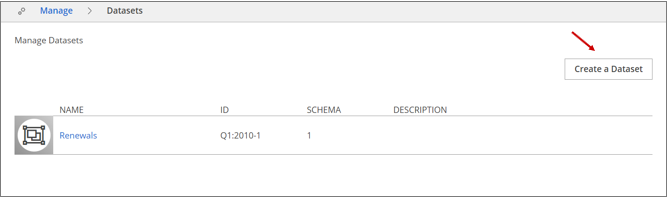 The Create Dataset dialog box displays.
The Create Dataset dialog box displays.Enter the following details:
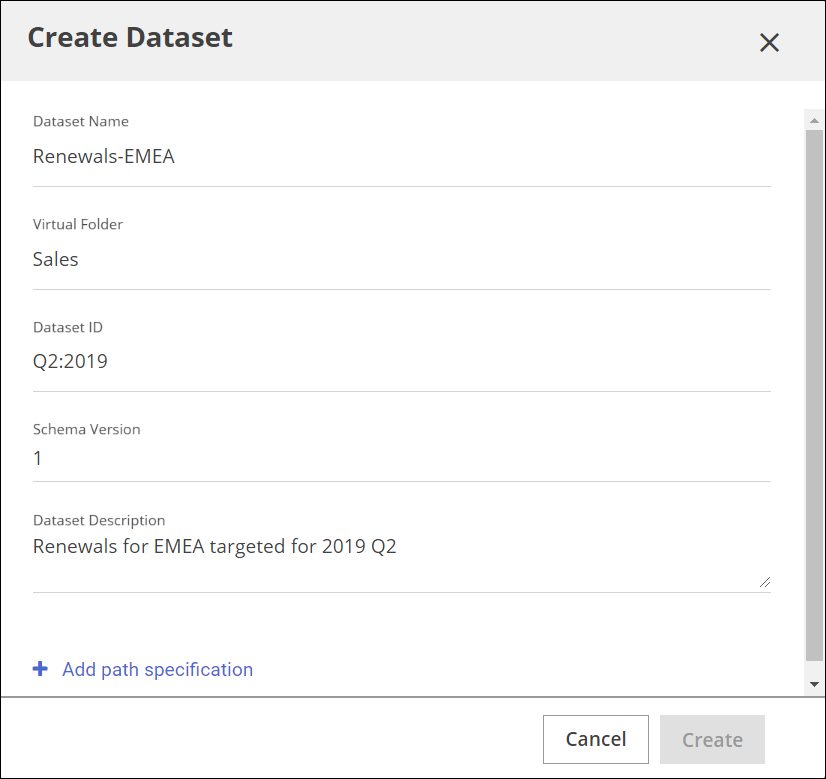
Field Description Dataset Name Lumada Data Catalog identifies any dataset by a unique name. The name must begin with a letter and can only contain alpha-numeric characters, hyphens, and underscores. This field is required.
Virtual Folder Name of the virtual folder source from which the include and exclude path specifications are defined. Note that Data Catalog supports only one source folder of the S3/HDFS type.
This field is required.
Dataset ID A string value that uniquely identifies the dataset along with the Dataset Name and Schema Version fields. This field is required.
Schema Version An integer field and identifies the schema for the newly created dataset. Dataset Description Enter a brief description of the dataset. This value is not considered when profiling the dataset. This field is optional.
Click Add path specification.
A new pane opens.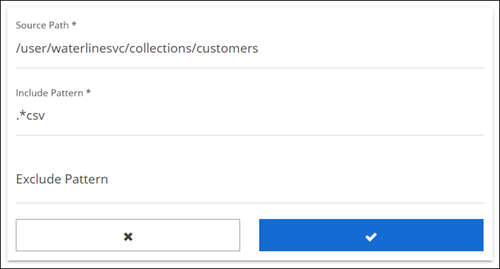
Enter information for the following fields and then click the checkmark button.
Field Description Source Path Enter the absolute path of the virtual folder resource to be a part of this Dataset. This path becomes the template against which all the resources added to the dataset are compared. The resources added to this Dataset must belong to this path or a subset of it. Include Pattern Specify the regular expression pattern for a list of resources that you want to include in this Dataset from the virtual folder mentioned above. Exclude Pattern Specify the regular expression pattern for a list of resources from the Source Path specification that you may want to exclude from this Dataset. This is an optional field. The Source Path, Include Pattern, and optional Exclude Pattern form the qualifying template for the dataset. You can use different Include Pattern and Exclude Pattern combinations to include or exclude specific types of resources.
Click Create to create your dataset.
You can click Create with a single path specification defined. However, a dataset can have more than one path specification, as long as the paths belong to the same virtual folder specified in the Virtual Folder field. By creating multiple path specifications, resources across the virtual folder source are added to the dataset.The dataset is created. You can now define a schema for your dataset or start adding resources to the dataset.
Define Reported Schema
Perform the following steps to define a reported schema:
Procedure
Navigate to Manage, then click Datasets.
Select the dataset for which you want to define a reported schema, and click the Reported Schema tab.

Click Add a new schema field.
The Create Schema Field dialog box opens.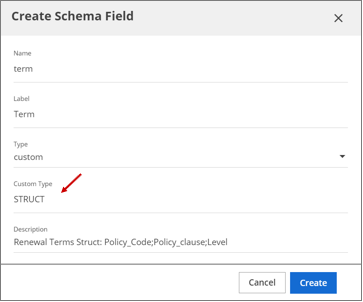
In the Create Schema Field dialog box, enter the applicable information in the fields, and select the expected data type in the Type field.
(Optional) If your Type is custom and it requires a specific application, enter that data type in the Custom Type field.
Results
To delete a schema field, select Delete from the More actions icon drop-down menu.
Add member resources to a dataset
When adding the resource, Lumada Data Catalog does not check for the existence of the resource in the data lake, although it will display an error when adding resources that do not satisfy the path specification template. For example, you can add a resource that does not yet exist as long as it satisfies the path specification template. This feature is useful in applications that expect a repetitive resource name from different source paths.
However, when profiling the dataset, Data Catalog checks for the existence of the resource, and if there is an error, it is logged in the log file (/var/log/ldc/ldc-ui.log).Perform the following steps to add a resource to a dataset:
Procedure
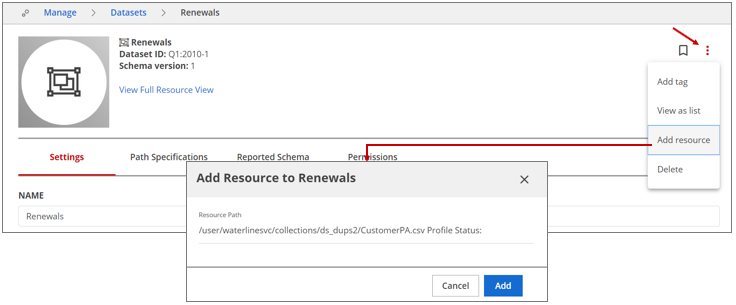
Navigate to Manage, then click Datasets.
Select the dataset to which you want to add a resource.
Locate the More actions icon and select the Add resource option from the drop-down menu.
Enter the absolute path of the resource and click Add.
Results
View member resources of a dataset
- The Manage Datasets page that displays the dataset details.
- The Browse Datasets list.
- The single resource view (SRV) for the dataset.
Perform the following steps to view a dataset's member resources:
Procedure
Navigate to Manage, then click Datasets.
On the row for the dataset you want to view, click More actions and then select View as list from the menu that displays.
The list of the member resources for that dataset appears.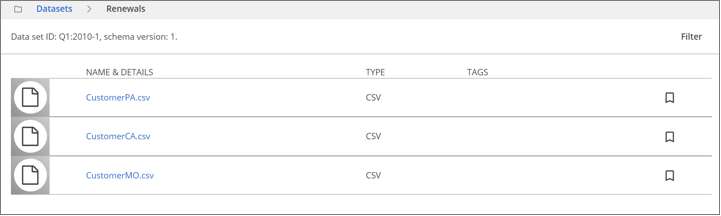
Click the Filter button.
A Browse Filters dialog box opens.Select the facets you want to view and click Apply Filters.
Remove a member resource from a dataset
Perform the following steps to remove a member resource from a dataset.
Procedure
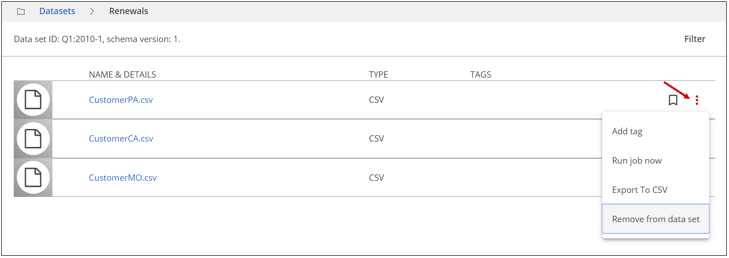
Navigate to Manage, then click Datasets.
On the row of the dataset from which you want to remove a resource, click the More actions icon and select the View as list option.
On the row of the resource you want to remove, click the More actions icon, and select the Remove from data set option.
Results
Profile a dataset
The reported schema is used for display purposes and user convenience only and does not play a part in the dataset processing. The fields discovered may be more than the reported schema for the dataset and may not always match the actual fields discovered.
Perform the following steps to profile a dataset:
Procedure
Navigate to Manage, then click Datasets.
Click the dataset you want to profile.
The single resource view of the dataset displays.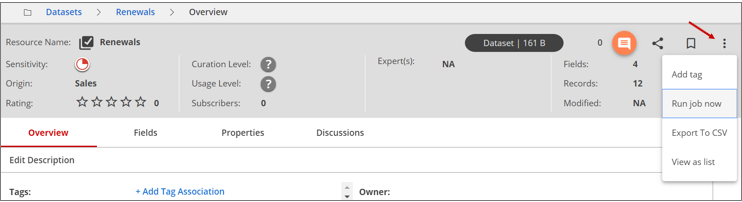
Click the More actions icon and select the Run job now option.
Select Sequence and click Next.
Select Profile and click Next.
You can also select either Fast profiling mode or Incremental profiling or both.Review the summary of your selection and click Submit Job.
The job execution starts. A profiled dataset single resource view looks like the following screen: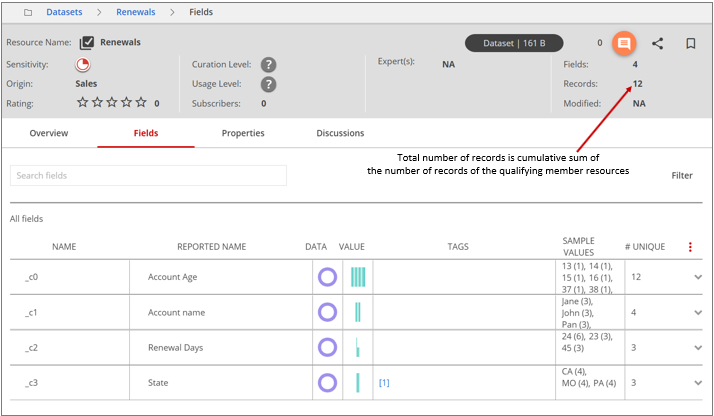 The total number of records is the cumulative sum of the number of records of the
qualifying member resources.
The total number of records is the cumulative sum of the number of records of the
qualifying member resources.
Tagging datasets and member resources
Like any other resource or entity in Lumada Data Catalog, you can tag non-collection member resources of a dataset with field or resource tag associations at the dataset level.
For more information, see Tagging a resource.
Updating datasets
You can update the name, description, or path specification of an existing dataset, along with include or exclude parameters. Although the name and description updates do not alter the profiling information of the dataset, any changes to the path specification and include or exclude parameters alter the dataset metadata. Such an update affects only the resources added after the update, and there is no effect on the existing resources of the dataset. The path validation takes place only for resources added after the update.
Keep the following points in mind when updating a dataset:
- If you do not manually remove existing resources from the dataset, the resources are skipped during future profiling on the dataset.
- As with any Lumada Data Catalog resource, updates that alter the dataset metadata also require that you reprofile the dataset for the changes to be reflected by the Data Catalog metadata storage.
- You need to manually remove from the dataset any existing dataset resource member that does not satisfy an updated path specification for the dataset. You need to then reprofile the dataset for the record count to reflect the changes in total number of records of the dataset. If you do not remove such resources from the dataset, reprofiling the dataset does not update the record counts for the dataset.
- You can also update the reported schema, which has no particular effect on the dataset profiling. The reported schema is only used for display purposes and your convenience.
Set dataset access permissions
Perform the following steps to set permissions for a dataset.
Procedure
Navigate to Manage, then click Dataset.
Select the dataset for which you want to manage permissions.
Click the Permissions tab.
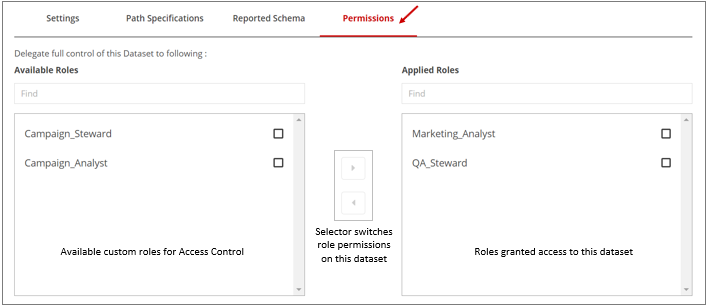 The Available Roles list shows all the custom roles in the system and the roles that get management permissions for the dataset will be shown in the Applied Roles list.
The Available Roles list shows all the custom roles in the system and the roles that get management permissions for the dataset will be shown in the Applied Roles list.To give a role access to the dataset, select the role in the Available Roles list and use the right arrow button to move it to the Available Roles list.
You can use the arrow buttons to move roles between the Applied Roles and the Available Roles list.The Available Roles list shows all the custom roles in the system and the roles that get management permissions for the dataset are shown in the Applied Roles list.
Results
 A non-admin user with custom role can now manage the following dataset properties:
A non-admin user with custom role can now manage the following dataset properties:- Name
- Description
- Path specification
- Reported schema
The non-admin user can also perform functions like:
- Adding a resource
- Adding a tag
- Viewing dataset resources as a list
- Running profiling and discovery jobs
Delete a dataset
Perform the following steps to delete a dataset:
Procedure
Navigate to Manage, then click Datasets.
On the row of the dataset to delete, click the More actions icon and select Delete.
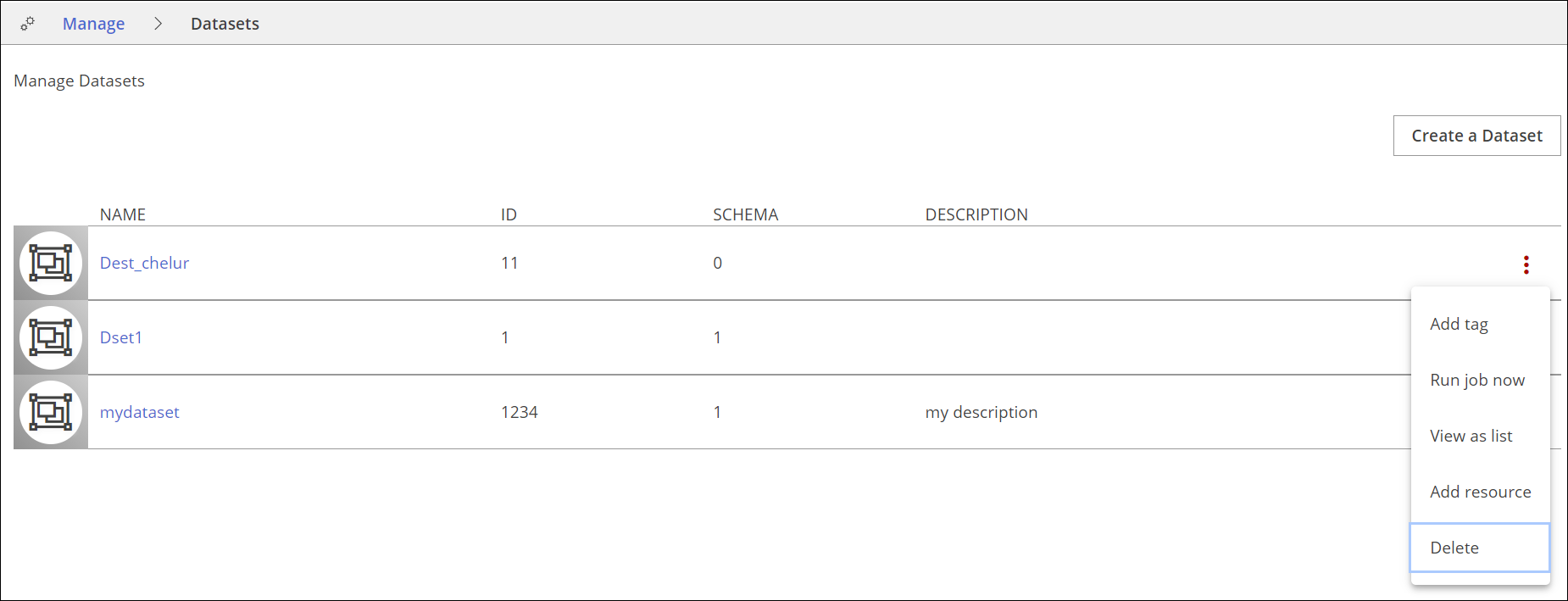
You can also delete the dataset from the dataset single resource view.
Data Catalog prompts you for confirmation before deleting the dataset.
Dataset restrictions
By design, Lumada Data Catalog puts the following restrictions on datasets:
Resources
You can only create datasets for S3/HDFS data sources, and a resource cannot be a member of more than one dataset at a time. Data Catalog uses the schema of the member resource with the oldest timestamp in its metadata directory as a reference schema, based on which of the other dataset members are profiled. Those added resources whose schema does not match the reference schema are not profiled as dataset members, and an applicable log message displays.
Virtual folders
A dataset can have only one source virtual folder. By design, Data Catalog upholds the uniqueness of the dataset across the catalog, not just across source virtual folders. No two datasets with same name, ID, and schema version can exist even when their source virtual folders are different. Datasets can have only files or tables as member resources. Data Catalog does not allow folders, databases, or collections to be a part of the dataset.
Security
Only a user with Administrator privilege is able to create and delete datasets. If their role permits it, non-admin users can manage dataset properties like changing the dataset name, description, path specification, reported schema, and operations like adding a resource, adding resource and field tags, and running jobs.
Tagging
If a resource that is a part of a collection becomes a dataset member, you cannot tag this resource at the resource level.