Lineage and origins

With resources in a data lake constantly changing and updating, and data frequently being merged or duplicated, it becomes important to keep track of the relationships between these data resources. Lumada Data Catalog uses resource metadata and resource data to identify cluster resources that are related to each other. It identifies copies of the same data and merges between resources and the horizontal and vertical subsets of these resources. These relationships are the lineages of the resources.
The places where data comes into the cluster is called the Origin(s) of that data. Typically, the origin is the data source belonging to or coming from the resource. Data Catalog propagates the origin information across the lineage relationships to show the origin of the data.
Lineage discovery
With resources in a data lake constantly changing and updating, and data frequently being merged or duplicated, it becomes important to keep track of the relationships between these changing data resources. Data Catalog inventory uses resource metadata and data to identify cluster resources that are related to each other. It identifies copies of the same data, merges between resources, and the horizontal and vertical subsets of these resources. These relationships are the lineages of the resources.
Useful terminology
Here are the common terms used in lineage and origins.
Upstream vs Downstream
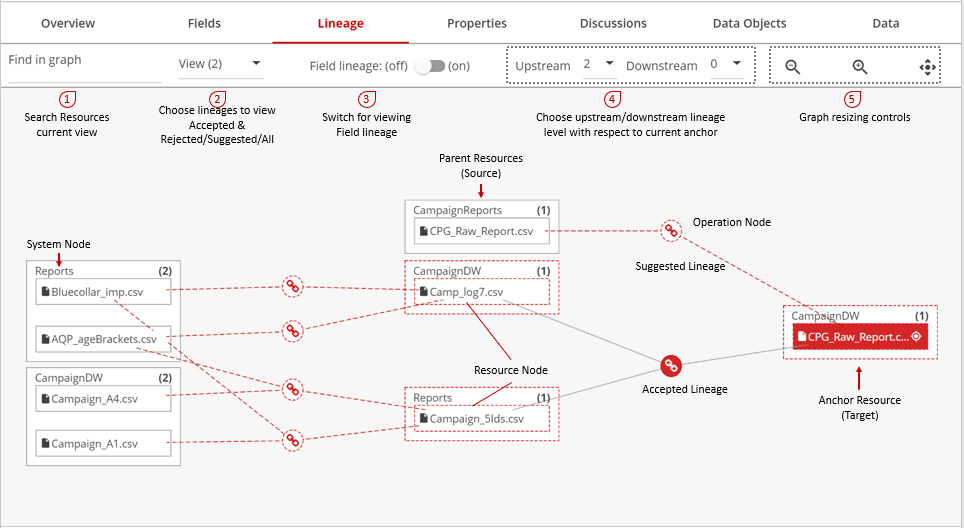
Data lineage represents the flow of a data. Therefore, data comes from a source upstream and flows into a target downstream. Using the anchor resource as a vantage point, we express flow in the graph from the left to right of the map.
Target vs Source
A target is any resource that is pulling data from another data source. A source is any resource that feeds data out into a target. For single hop instances immediate upstream and downstream are also known as parent and child of the target.
Inferred lineage
This lineage is suggested by Data Catalog and is inferred or derived based on the metadata and data for data resources across the platform.
Factual lineage
All non-suggested lineage is considered to be factual lineage and is derived from user curations or third party tools (like Atlas or Navigator).
Multi-hop lineage
Data Catalog can trace lineage up to 5 levels upstream (to source) and 5 levels downstream (to targets).
Resource-level lineage
This type of lineage traces the relationship between the upstream to downstream resources in a data lake.
Field-level lineage
For an established resource lineage, field-level lineage traces the field relationships between the source and target resources. The field-level mapping details the relationships.
Systems
The system is the outermost boundary containing a resource. Every resource sits within a system. A system corresponds to a business analyst's concept of an application, library, or logical repository, such as "Sales Production" or "Corporate Warehouse". The system proves invaluable for lineage users to understand the flow of data across the firm.
Suppose a business analyst is looking at the "Sales Team Compensation" file. Upstream they see a file with sales figures. If it is in the sales production system, the sales figures are probably authoritative. If they are in training services system, they are much less so.
As lineages become longer chains, the farther away a file is in the lineage, the user is less likely to know of the specifics of folders and such, but the system names are more likely to be informative.
NotePoints to remember about systems:- System is defined in Data Catalog as a property on a virtual folder. Refer to Managing Virtual Folders for details.
- If the System property is not set, it defaults to the Data Source name.
- A system may contain multiple resources.
Lineage discovery helps with:
Lineage tracing
Upstream data origination or which source resources this data is coming from.
Impact assessment
Downstream data impact or which target resources this data is going to affect.
Types of lineages
Data Catalog can import the factual lineage collected by external tools or discover inferred lineage relationships, as described in the following topics:
Imported or factual lineage
Data Catalog provides functionality in its WebUI browser to import the factual lineage gathered by Atlas or Navigator tools. Please refer to Lineage and origins in the User Guide for more details.
Inferred lineage discovery
Data Catalog's Lineage Discovery job discovers inferred lineage relationships among all profiled files and tables and calculates file and table origins. Inferred lineage discovery is the backend process that is looking for the potential parent-child relationships between data resources across data sources.
Lineage is inferred in contrast with Atlas and Navigator factual lineage which is based on audit logs. This means that Data Catalog uses heuristic data centric approach to find the similar data in an enterprise. When audit logs or other historic metadata are unavailable, this is the only way how to guess the lineage relationships. Because discovered knowledge based on heuristics cannot be precise, the lineage is inferred, not factual.
Inferred lineage is discovered across platform, between different data source types.
The following specific parent-child relationships are targeted:
- Copy
- Partial copy (vertical copy)
- Subset (horizontal and vertical copy)
- Superset (horizontal and vertical copy)
- Union - generally would have 2 or more parents, and the child resource is the union of the identified parents
- Partial union
- Join
Other types of lineage (for instance, the join/merge relationship) could be discovered accidentally and this is quite possible for many cases because we do not require all fields to match.
Inferred lineage discovery is based on the following fundamental assumptions:
- Ability to match resource data for individual fields - Information is available as a result of the profiling.
- Ability to arrange resources based on creation date with assumption that parent is created before child.
- Hint for the parent and child data sources is important to scale down computation. Realistically enterprise is moving data from one location (data source) to another.
- Lineage is done on regular resources and collection roots. Collection members are excluded from the lineage discovery.
- Because of assumptions (1) and (4), we require that profiling be completed for all data resources before lineage discovery.
- Assumption (2) translates for different processing details and data source compatibility and other restriction based on current implementation details.
- Assumption (3) translates to the mandatory hints as target virtual folders and optional list of parent virtual folders.
Spark execution parameters
Inferred lineage discovery is very resource consuming Spark application that performs across the product between different data source fingerprints. It is necessary to start with large number of executors with large amount of memory allocated for each executor.
Important notes on lineage
- The lineage command operates on data in the Data Catalog HDFS metadata store; if new files are added to the cluster, you must run a profile command to collect profiling data before you are able to see information for the new files reflected in lineage relationships.
- For performance reasons, consider profiling all data on the cluster before running lineage discovery; during regular maintenance, run lineage discovery after significant numbers of files are added rather than running it for each incremental change.
- Consider limiting lineage discovery to a specific parent or child directory
when your data lake is organized in ways that allow you to isolate lineage to specific
areas.
To run lineage against a set of test files, do not provide the
-parentVirtualFolderListparameter in which case both parent and children resources are picked from the-virtualFolderparameter listed, like this:<AGENT-HOME>$ bin/ldc lineage -virtualFolder Fin_Asia -path /data/FinanceThe Lineage command triggers lineage discovery across the entire Fin_Asia folder, re-evaluating any existing suggested lineage relationships.
The progress of the job is indicated by messages on the console and logged in the ldc‑jobs.log found by default in /var/log/waterlinedata.
NoteThis shortcut for discovering lineages within the same folder will not work for JDBC resources. - Lineage discovery is a memory-intensive process; initial lineage discovery runs can take a long time.
Data source specific parent-child relationship
The following table lists specific parent-child relationships.
| Parent data set type | Child data set type | Parent-child validation rules (ordering) |
| HDFS | HDFS | Parent is older than child. Ordered by last modified date. Other configured time sensitive restrictions (see configuration.json). |
| HDFS | HIVE | Factual lineage only. Will create the lineage during HIVE schema discovery. Format discovery or UI browsing is required. |
| HDFS | JDBC | Do not use creation dates. |
| HIVE | HDFS | N/A. HDFS tables are not created from HIVE. |
| HIVE | HIVE | Parent is older than child. Ordered by creation date. |
| HIVE | DB | Do not use creation dates. |
| DB | HDFS | Do not use creation dates. |
| DB | HIVE | Do not use creation dates. |
| DB | DB | Do not use creation dates. Do not allow for the same virtual folder as a parent and as a child. |
Inferred lineage configuration parameters
| Parameter | Label | Description | Default | Resource specific |
| batch_window_hours | Max access time window | Greatest interval (in hours) between parent access time and child modification date for discovery to consider the two resources to be candidates for a lineage relationships. Time checking is ignored if this value is set to 0. | 24 | HDFS |
| cardinality_difference | Cardinality difference | Child field cardinality can be up to this value times larger than cardinality of matching parent field to consider for lineage relationships. Disabled if 0.0. | 0.0 | All |
| diff_same_directory_sec | Same directory modified time difference | Smallest interval between last modified dates for files in the same directory to be considered for lineage relationships. If you have a transformation process that runs on files to create similar or 'refined' copies of data in the same directory, consider reducing this limit to ensure that Data Catalog Inventory finds lineage relationships between the original file and the modified file. | 30 | HDFS |
| min_lineage_field_count | Min matching fields | Minimum number of matching fields required to consider two resources as candidates for a lineage relationship. | 2 | -- |
| min_lineage_percent_field_count | Min rate of matching fields | Minimum rate of matching fields count required to consider two resources as candidates for a lineage relationship. Larger of this or field count is used. | 0.1 | -- |
| min_max_cardinality | Max cardinality | Maximum cardinality value for all matched distinct fields for lineage discovery to consider. Should be greater or equal of this value to be considered as a valid lineage. | 3 | -- |
| overlap | Min overlap values | Portion of overlapped values to cardinality of the child field for filter (copy, partial copy) lineage or parent filed for union lineage. Portion must be greater than or equal to this value to consider parent-child field as a valid candidate for a lineage relationship. This value is not recommended to change. Values lower that 0.8 may lead to significant number of false positive matches. | 0.8 | -- |
| filter.min_fields2infer | Minimum number for mapped child fields to infer the filter lineage | Will infer filter lineage (copy or partial copy) if the portion of mapped child fields is greater of equal of this value. | 0.6 | -- |
| union.min_fields2infer | Minimum number for mapped child fields to infer the lineage | Will infer union lineage if the portion of mapped child fields is greater of equal of this value. | 0.8 | -- |
| filter.max_alternatives | Maximum number of alternative filter lineages | Maximum number of alternative filter lineages (copy and partial copy) to infer. | 2 | -- |
| union.max_alternatives | Maximum number of alternative union lineages | Maximum number of alternative union lineages to infer. | 2 | -- |
| selectivity_difference | Selectivity difference | Child field selectivity should be more than this value times the differences from selectivity of matching parent field to consider resources for a lineage relationship. Disabled if cardinality difference is set to 0.0. | 0.2 | -- |
| use_access_time_filter | Use access time filter | Use last-access time checking for lineage discovery. Actionable only if HDFS
settings for last access date is enabled in the property
dfs.namenode.accesstime.precision of
hdfs-site.xml. Currently this optimization is not
recommended. | false | HDFS |
| same_schema | Percent of fields with the same name to be considered as the same schema | Percent of fields with the same name to be considered as the same schema. For the same schema, lineage discovery will match the same name fields. | 0.8 | -- |
| same_schema.non_matching | Percent of non-matching fields of same name to be excluded from the lineage consideration | If more then this percentage of the child fields does not match for the same schema, the parent-child is not considered for the lineage discovery. | 0.3 | -- |
| same_schema.min2check | Minimum same schema fields to match | Minimum same schema fields to match. Otherwise, cannot use same schema optimization. | 5 | -- |
| lpupdate.batchsize | Batch size for discovery cache objects | Use this batch size to save discovery cache objects. One batch
normally is saved in one HDFS MapFile in location configure using
ldc.metadata.hdfs.large_properties.uri and
ldc.metadata.hdfs.large_properties.path | 200 | -- |
| discovery.framework.right.batchsize | Batch size for left entity caching for discovery framework | Use this batch size to retrieve left entity - first entity type defined for the discovery cross product. For tag propagation, it is tag. For lineage discovery, it is a parent data resource. | 500 | -- |
| discovery.framework.right.batchsize | Batch size for right entity caching for discovery framework | Use this batch size to retrieve the right entities - second entity type defined for the discovery cross product. Currently, it is always a data resource. | 400 | -- |
Origins
The places where data comes into the cluster is called Origin(s) of that data. Typically, this is the data source or the virtual folder that the resource comes from or belongs to. Data Catalog Inventory propagates the Origin information across the lineage relationships to show the origin of the data.
Origins of any resource are data sources related to this data resource directly (belongs to) or indirectly, through imported, inferred or manually created (factual) lineages.
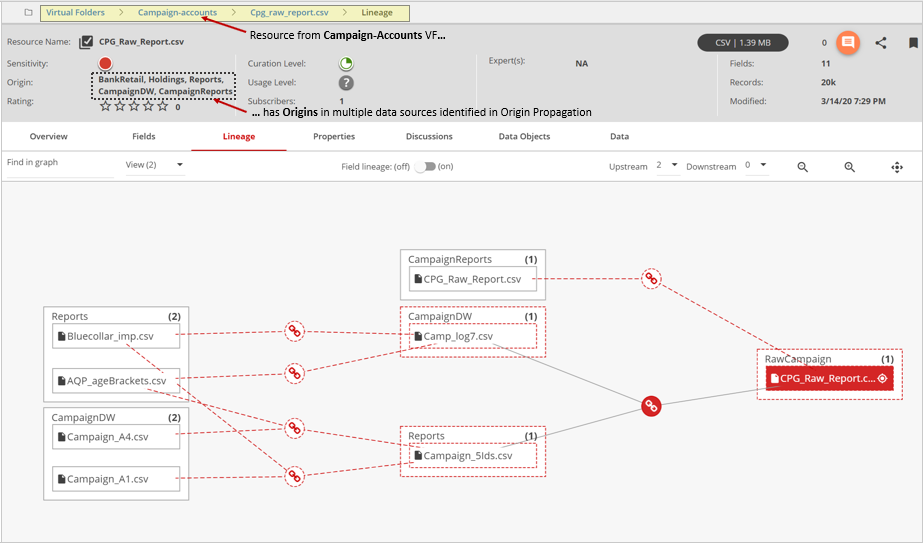
To see origins in the single resource view, run
OriginPropagation from .
The com.hitachivantara.origin.OriginPropagation has the
following parameters:
-mode is the type of origin with value being one of
all/inferred/imported.
-
inferredpropagates origins only through inferred lineages, accepted and suggested. -
importedpropagates origins only through factual imported lineages. - all (default) propagates origins through inferred and imported lineages.