Getting started with tags and tag propagation

Tags are business labels that are attached to Lumada Data Catalog data units (virtual folders and datasets) and resources (tables, files, and fields).
Tags identify datasets so you can use the tag names as search terms. Data Catalog can assist you in tagging the data in your catalog. When you tag a field in a data resource, Data Catalog automatically propagates that tag through your data lake and identifies associations with similar fields in other files and tables that match the data you tagged. This process, called tag discovery, uses data and metadata about the fields you tag to identify matching fields. Note that tags on resources (files and tables) are not propagated, whereas tags on fields are propagated.
Tags can also be created with regular expression rules to match data without requiring an initial tag association.
Tag domain
A single resource or field can be tagged by multiple tags associated with different business units. Data Catalog provides a way to organize and separate the tags grouped by business units in the form of tag domains. Tag domains also enforce role-based access control to tags and tag domains. The administrator can limit the visibility of tags within a domain to a specified set of users, depending on those user Data Catalog roles.
While only admins can create a tag domain and assign them to roles, a steward role can create tags and tag associations. The analyst role can only associate existing tags in the tag domain assigned to their role. Learn more about roles and tags in Managing tag domains.
Tags
In Data Catalog, you can put tags on any kind of data asset or resource, or any field inside a resource. The level (resource-level or field-level) that you associate with a tag determines how that tag behaves.
Resource-level tags
Tags associated with a resource are often isolated labels for the resource. Use these tags as search terms to find files, tables, or directories that have been individually tagged. These tags are part of the metadata for the resource. They can be used to enrich the metadata for the resource, such as identifying or categorizing file contents, or to drive other types of processing, such as access control or processing stages.
For information on managing resource tags, see Tagging resources and fields.
Field-level tags
Tags associated with fields in a given resource are referred to as field-level tags. These tags can be propagated across the catalog.
The field-level tag types include:
Built-in tags
Data Catalog provides pre-built tags for common data patterns, such as credit card numbers and address components.
Custom tags or User-created tags
You can create field-level tags to identify data patterns across your catalog. There are two ways to create your own field-level tags:
Value tags
When you manually tag a field, the data and metadata for the field contribute to a rule for Data Catalog to suggest similar data to mark with the same tag.
Regular expression (Regex) tags
You can specify or define a tag with a regular expression that describes the data you want Data Catalog to mark with the tag.
Reference tags
You can use the data from built-in tags or other custom-created tags as seeds for new tags. Such built-in tags and custom tags become reference tags. For more information, see Reference tags.
Business entity
A business entity is a group of tags with context and has its own specifications for using. For mor information, see Business entities for details.
To learn more about managing field-level tags, see Tagging resources and fields.
Built-in tags
In addition to tags you add, Data Catalog has a set of predefined tags that it propagates throughout the cluster. These tags fall into two categories:
Regular expressions
Data, such as United States phone numbers and ZIP Codes, are tagged by matching data with regular expressions that describe data typical for these values.
Reference data
Field data, such as countries, states of the United States, and first and last names, are tagged by matching the signature of known data. The reference data is static: you cannot include data from seed fields to alter the tag algorithm of the built-in tags.
The built-in tags cannot be changed. If you don't want to use the provided built-in tags for tagging your data, you can turn off automatic tag propagation for these tags.
Built-in tags are propagated when you run a tag job after collecting discovery metadata for catalog resources. See Managing jobs to manage value tags.
Reference tags
Reference tags are tags that act as reference for referring tags that use the seed data or regular expression definition of the reference tag for seeding their tag discovery. Reference tags are indicated in Data Catalog by an arrow. Only tags with seeds or regular expression definitions are considered reference tags.
There are a few points to remember when managing reference tags. They can be from the same domain or can be from different tag domains, such as built-in tag domains. Additionally, they can have a many-to-one relationship where one reference tag is used by many referring tags. Lastly, as a best practice, you should avoid cyclic tag references because Data Catalog does not check for them.
Reference tags are used in Business entities, but are not limited to just business entities. Non-business entity member tags can assign other qualifying tags as reference. Suggestions for tag associations vary:
- If reference tags are defined for business entity members and a successful tag discovery is performed, then only the associations for the business entity member (referred) tag are suggested for fields. The original reference tag suggestions are removed for such fields.
- Reference tags that are part of a business entity have an increased confidence percentage if Data Catalog has discovered the context of the business entity.
- When reference tags are defined for tags that do not belong to a business entity, both tag associations (one for the referring tag and one for the original reference tag) are shown.
Value tags and seed data
When you tag a field in a file or table, Data Catalog adds the same tag to other fields in files and tables that match the data you tagged. It uses the first tag association created to seed the tag discovery process. It uses data and metadata about the field you tag to identify matching fields, then suggests the same tag for those fields.
The suggested tag appears as a dot-outlined button which you can click to accept or reject.

The score, shown as a percentage, that appears with the suggested tag indicates how closely this field matches the data and metadata of the original field.
Data Catalog compares the seed field's metadata and sample data with the metadata and sample data for all other fields included in the catalog. When it finds other fields with similar metadata or data, it calculates a score to represent how closely a new field matches the tagged field. For example, a field with the same name and data type might score 90%, while a field with the same data type and overlapping values, but a different field name might score only 75%. A field that is a complete copy would score 100%. Data Catalog shows only suggested tags for fields that match over a calculated threshold or a confidence cutoff.
Value tag scoring components
Tag association scoring includes weighted contributions of major and minor scoring dimensions. For a suggested field to appear, the fields must match on one or more of the following major criteria:
- Overlapping values.
- Overlapping tokens from the values, which are individual words in the field values that may match, even if the complete strings do not match.
- Overlapping patterns, such as most of the sample values consist of two words as in a person's name, or the sample data includes text formatted as dates.
- Matching field names.
- Standard deviation.
- Regular expression counts.
- Other matching tags.
- Major scoring dimension: Must have at least one match for a field to be suggested.
As a minor scoring dimension, a suggested field may appear if the field match is less than 5% for each matching area. For example, they contain matches on numeric properties such as quantities, cardinality, boundaries, or mean.
There may be cases where you have anonymous values and tag associations. In such cases, Data Catalog looks for overlapping data, overlapping tokens, and data patterns to match fields. However, to gain quality results, Data Catalog filters out common words and numbers that would match too often. For example, words such as "a", "an", and "the" are removed from the list of tokens. Also, individual letters ("a", "b", "c") and integers with 3 or fewer digits are removed.
If the field data in either the seed or the field to be matched includes many or mostly non-distinct values, Data Catalog is unlikely to make correct tag associations.
Value tagging seed fields
Data Catalog uses the sample data values from the fields from specific tag associations to add to the tag discovery process. The data from those fields is used when Data Catalog calculates the tag association scoring. When you use a tag for the first time to mark a field, Data Catalog sets that field to be a seed: the data in this field contributes to tag discovery. You can add additional fields to use in tag discovery. You can also replace the original seed with other tag associations if you find better seed fields.
Tag associations marked for use as seeds in tag discovery are indicated by the dot next to the tag name, as shown in the following image.

As a best practice, choose good seed tags. Make sure the data in the field is comprehensive and representative of the data you want tagged. If needed, replace a seed tag if the field has any of the following conditions:
- Null values.
- Incorrect or non-representative values.
- A subset of the data you would expect to be tagged.
Best practices for value tagging
Field data works well when field values are distinct terms and when sample data is a good representation of the full set of data. Strive for relatively low cardinality lists of repeated values such as product names or marital status values. Similar or overlapping data works well, too.
There are cases where discovery may not work well for tags:
- Numeric codes that are not distinct patterns. For example, 9-digit account numbers may be confused for US Social Security numbers.
- Numeric values such as temperatures, financial values, and counts.
- Cases where the tag name requires contextual information. For example, first and last names may work well for tagging, but tag discovery cannot distinguish between customer names and vendor names.
Curating value tags
Here is a process guideline:
Procedure
Browse to data sets you use.
Add tags to the fields.
Use names that match how you would expect users to identify the data. You might consider whether this particular field is a good representative of the data you want Data Catalog to tag.Run batch tag processing.
This batch job is run by an administrator, typically on a daily schedule. It applies new and updated tags to existing data and applies all tags to new data. During times of high tagging activity, you might want to run this job more frequently.Search on a specific tag to review how it was propagated.
You can use the Advanced Search, Glossary, or Catalog view to see fields tagged with a specific tag.Review the tag associations and use the profile information for the field to validate if the tag is correct.
Accept correct tag associations and reject incorrect tag associations.
Accepting and rejecting tags changes the tag discovery algorithm for the tag. To best train Data Catalog to perform the optimal tag propagation, accept or reject one or two tag associations at a time. Exhaustively removing all incorrect tag associations is not as effective for improving the tag discovery algorithms.NoteTo accept or reject tag associations for most resources, users need to be assigned the Steward role (minimum level).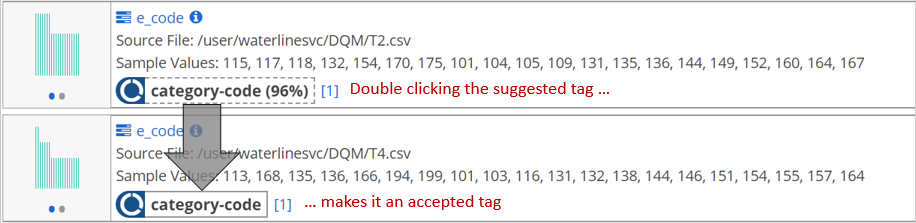
Rerun tag processing.
Next steps
If you tag a field that contains a product code made up of letters, numbers, and punctuation, such as “CSP-2201A,” Data Catalog can precisely identify other fields with similarly constructed data. However, if you tag a field that contains free text, such as a text field in a social media feed, or numeric values, such as rainfall depth values, Data Catalog may find false positives when attempting to match the data. See Tag tuning scenarios for more information about troubleshooting tags.
As a best practice, consider defining a regular expression for a tag when you want to tag data with a specific text pattern.
Tuning your tag associations
In Data Catalog, the method of linking the created seed tags with similar fields in other resources is called tag association. After defining the seed tag and running the tag discovery process, Data Catalog identifies the fields that match the seed tag as tag associations. Tag associations also include a matching score, which determines the percentage match to the seed data. If the value is 90%, then this tag association is a 90% match to the seed tag and indicates a high probability of data similarity between the seed field and the associated field.
You have several methods for tuning the tag process.
Accept or reject tag associations
When a tag association is accepted or rejected, Data Catalog determines which component of the data or metadata matched (or didn't match) and adjusts how that component contributes to the overall score.
Each acceptance of a tag incrementally increases the weight of the score component while each rejection of a tag incrementally lowers the weight of the score component. When there are three more rejections for a tag than there are acceptances, the affected component of the score is removed completely.
Set which fields contribute to data discovery
The first manual tag association is automatically used to seed tag discovery. There may be times when you want to add or change which field is used as the seed.
For example, if a field includes a high volume of null values, the tag discovery process includes the null as part of the expected data. If you don't want to include null values in the data that Data Catalog identifies, then replace the field containing null values with a field that has a cleaner version of the data.
Consider modifying the seed tag association in the following cases:
- Exclude an association when the field includes data that is dirty or unrepresentative. For example, if most data values are null, exclude such fields from seeding the tag discovery.
- Include more associations to include additional values. For example, you may have claim numbers from different zone offices that adhere to different patterns, but still need to be identified as one business tag. This types of field requires tag associations from both resources to be marked as seed data for tag discovery.
Change the confidence cutoff of the tag associations
Each tag has a confidence cutoff. If a field matches with a score below the threshold value or confidence cutoff, then the tag association does not appear in the catalog.
The confidence cutoff is set based on a set of scoring components applicable for seed fields. For example, if the seed data is classified as anonymous, Data Catalog sets the confidence cutoff high. For string values with mostly fixed lengths, such as alpha-numeric codes, the confidence cutoff is set low.
By default, Data Catalog determines the confidence cutoff. The default tag association confidence cutoff is set to 40% for low, 60% for normal, and 80% for high. You can configure these defaults in the conf/configuration.json file.
Tag tuning scenarios
Refer to the following scenarios to troubleshoot issues with tag tuning.
False positive tag associations occur when a tag is applied to fields that do not match the original field.
False positive tag associations occur because Data Catalog is finding connections between the suggested fields and the seed field that are not what was intended when the original field was tagged. The most probable cause is that elements of the fields' data or metadata are matching for criteria that they are not intended to match. Data Catalog needs input from you to determine which data or metadata components correspond to the intended matches between the seed field and the correct field matches.
To resolve false positive tag associations, use the following solutions in the order provided:
- Reject individual tag associations.
Reject one or two of the incorrect tag associations and re-run the tag propagation job. Rejecting tag associations changes the tag algorithm scoring. Data Catalog reviews the matching components identified for the rejected tag association, determines which components scored the highest on this "bad" association, and lowers the weight in the tag discovery algorithm for the high-scoring components.
The next tag job removes all the suggested tags for this tag and reapplies them based on the updated algorithm. As a best practice, iterate through this process more than once: it takes three rejections of the same component before Data Catalog removes this component from the scoring entirely. See Accepting or rejecting suggested tag associations for more information.
- Validate the sample data.
Review the sample data for the field used as a seed field. The sample data may reveal that the tag has null or incorrect values, which can distort the sample data so that it is no longer representative of the "good" data in the field. The distorted data may cause the wrong fields to be suggested.
For example, if your seed data includes customer email addresses and many of the records are empty or have a default value of "not provided", then the sample data set for the field will show "null" or "not provided" as frequent values. Data Catalog tries to match fields that also include these values. If other optional fields such as "age" and "marital status" also use "not provided" when there is no value, Data Catalog may see matches against this other data.
For this issue, identify another field to use as a seed for tag association. For example, find one of the suggested tags that is correct and use it as a second seed or use it to replace the primary seed. The next tag job will remove all the suggested tags for this tag and reapply them based on the updated algorithm that uses the new sample data. See Set which fields contribute to data discovery for more information.
- Adjust the confidence cutoff.
If you find that tag associations with lower scores tend to be incorrect, you can adjust the confidence cutoff for the tag so that tag associations that score less than the threshold value are not added. Data Catalog sets the initial confidence cutoff based on the distribution of tag association scores across the catalog.
NoteIf you set the confidence cutoff above 50%, tag association matches must include more than one "major" component to successfully show up as matched.If you notice that the false positive associations for a given tag often occur for fields that are also correctly tagged with a second tag, consider increasing the tag weight for the correct tag. This adjustment takes advantage of the Data Catalog scoring rule for two tags on the same field. If the scores for the two tags differ by more than 20 points, the lower-scoring tag association is dropped. See Change the confidence cutoff of the tag associations for more information.
False negative tag associations occur when a tag is not applied to fields where the data does match the original field data. The field data or metadata does not reflect the right data or metadata characteristics. Data Catalog does not recognize the correlation that you can see between the seed field and the expected matching fields. For example, you can see that the field data matches, but there's no match based on data values and other major scoring components. This situation is common when fields contain free text values that are mostly unique, such as notes, titles, messages, other free text that are not related by key words.
The problem could be with the seed field itself or with the fields that are not matching properly. Here are the most common reasons why false negatives occur:
No seed is set for tag discovery.
Check to make sure that a seed exists for the tag. If there is no seed tag association, then you won't see any suggested tag associations for the tag.
Incomplete seed data.
Data Catalog collects sample values and compares data from each field in the catalog using algorithms, which analyze whether field data overlaps with the seed data for the tag. If Data Catalog determines that data is not overlapping, this component of the tag score is eliminated. If a field lacks matches on any other of the major components, the tag won't be associated with the field.
To resolve false negative tag associations, accept additional suggested tag associations. Accepting more tag associations reinforces the positive elements of Data Catalog's tag discovery algorithm. For example, if a tag association is accepted for a field with a different field name, Data Catalog adds the additional field name to the list of matching field names to look for on the next tag run.
- Replace the field used as the seed field.
You might review the sample data for the field being used as a seed field. Null or incorrect values can distort the sample data so that it is no longer representative of the "good" data in the field. The distorted data may cause Data Catalog not to match fields based on the sample data or the distribution of values in the sample data. For example, if your seed data includes customer email addresses and many of the records are empty or have a default value of "not provided", then the sample data set for the field will show "null" or "not provided" as frequent values. Data Catalog tries to match fields that also include these values and may fail to match any fields.
- Add additional seed fields.
You can select more than one tag associations to use in tag propagation. Data Catalog builds the sample data for the seed by aggregating the tag signature from each sample, which may help when data is not necessarily unique across fields. Increasing the pool of sample values allows Data Catalog to find matches between the seed and other fields.
- Create your own reference data to use as a seed field.
If you do not have good examples of the data you are trying to find, make a dummy file with data that matches the values, tokens, or pattern of the data you want to match and use that field as the seed for the tag.
By default, Data Catalog determines the confidence cutoff for a tag. If that score is too high, Data Catalog can miss some possible matches.
To resolve high confidence cutoff issues, change the confidence cutoff for the tag. Lowering the confidence cutoff for a tag allows Data Catalog to show additional tag associations. See Change the confidence cutoff of the tag associations for more information.
Regular expression tags
Data Catalog supports automatic tagging using the regular expression to match field values. Tag associations are suggested based on the number of values in the field that match the regular expression.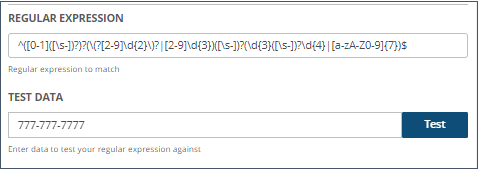
As an example, if your company has a specific code they use to keep track of part, you could create a REGEX tag for the part ID by using a regular expression for the tag association.
Regular expression tagging rules include a threshold value (known as the confidence cutoff) to indicate how many of a field's values need to match to tag the field. By default, the threshold is set for 80%. If you want to consider cases where fewer instances match the regular expression, then lower the confidence cutoff for the tag.
When Data Catalog considers regular expression tags for propagating, it considers tag name matches against the field name as part of the scoring. The field name alone is not enough to associate a regular expression tag with a field, but a matching partial or complete field name can add to the overall score of the tag association.
Some of the built-in tags use regular expressions to identify field data, such as phone number, credit card numbers, email addresses, and IP addresses.
When to use regular expression tags over value tags
When you know all the possible values or value patterns that you want tagged with a selected tag, use a regular expression tag. Although regular expression tags match a specific pattern, you can increase flexibility by lowering the confidence cutoff to match fields that include data that does not match the pattern, such that if your data turns out to be “dirtier” than you expect, consider lowering the confidence cutoff for the tag.
When values are not exact or when many values can be acceptable for a field, use a value tag. Value tagging uses sample data and field metadata to score matches in addition to sample data. The value tagging algorithm can identify matching fields with a broad range of similarities and can evolve as your data changes.
As a best practice, use value tagging first. If a value tag does not perform well after basic tuning, then consider creating a regular expression tag.
Evaluating regular expressions against sample data
When Data Catalog performs the discovery profiling for data, it matches all regular expression tag patterns against all the data in each field. When regular expression tags are added after discovery metadata exists, the tagging job uses 2000 sample values to determine whether regular expression tags match data.
For most cases, using sample data is a useful substitute for the full data set. The sample values represent the most frequent values in the data. If the most frequent values match the regular expression pattern, then it is likely that the full set of data also matches the regular expression pattern.
The sample data may not be an applicable substitute for the full set of data when the data cardinality is very high and there is a lot of variety across the data. These conditions are too difficult for a random sample of data values to produce a representative sample of the entire data set. If you see these conditions, consider re-evaluating the regular expression tags against all the data in the catalog.
Defining regular expressions
If you need to know more about regular expressions, explore an online tutorial such as regexone.com. You can also examine the regular expressions specified for the built-in tags. When putting together your own tagging rules, the built-in tags may provide good examples of what you can do using regular expressions and length limits.
Some basic notations include the following:
- Match the beginning of the data value:
^ - Match the end of a string:
$ - Match any digit: d or
[0-9] - Match any letter:
[a-zA-Z] - Repetition of a pattern
{n}where “n” is the number of repetitions - Indicate what does not match:
(?!<pattern>)
Regex use case to discover national identifiers
Follow the steps below to discover fields using regex tags.
Procedure
Create a tag domain named National_Identifiers.
Create regex tags for the national identifier and or passport ID that needs to be discovered by defining the valid regex.
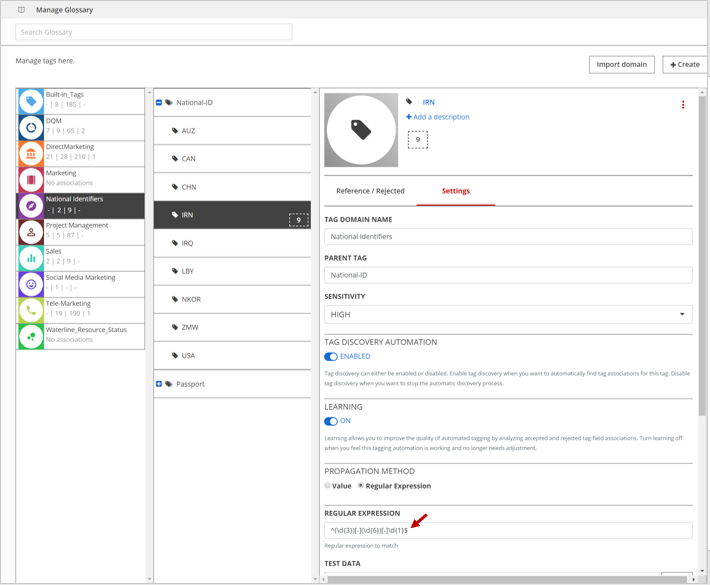
Run tag discovery on the data.
Learn how to run a discovery job in Managing jobs.
Results
Thesaurus
Data Catalog tag discovery jobs use name matching as one of the many criteria for suggesting field-tag associations. Tag discovery compares the name of a candidate field with the field names of already-curated fields, the field names associated with the tag, and with the tag name itself. In addition to direct word matching, special rules are applied from a thesaurus recorded in the file thesaurus.json.
The thesaurus is a collection of rules for synonyms, antonyms, common words, and exceptions. A Data Catalog service user with administrative privileges can customize the thesaurus to fine-tune the data discovery process, by providing words that the discovery process should find and words it should ignore.
The thesaurus file, thesaurus.json, is in the <LDC-HOME>/agent/conf directory, and is organized as a series of JSON entries, using standard JSON syntax.
Each entry has:
- a name
- a list of values
- attributes
- category - type of JSON entry - (synonyms, antonyms, common words, and exceptions)
- visible - not currently used
- enable - not currently used
All thesaurus entries are normalized as follows:
- All separators from the list defined in the
ldc.discovery.tag.name_matching_separatorsconfiguration property (such as"defaultValue": "(){}[]:;_ .,/") are removed. - All entries are treated as lowercase.
- All non-alpha characters from the end of the name are removed.
Normalization rules apply to all thesaurus names and values.
Synonyms
Synonyms are different names that the discovery process will match, including group name and group values.
In the following example, "
firstnames" will match "firstname", "givenname", "forename", and "fname"."firstnames": { "value": "firstname,givenname,forename,fname", "category": "SYNONYMS", "visible": true, "enable": true} ,Antonyms
Antonyms are a collection of opposites. Antonyms are names that will not match even if the learning algorithm determines they are synonyms, or even if you accept tag associations with fields containing those words. In the following example, "
tea" will not match "coffee", "milk", or "soda"."tea": { "value": "coffee,milk,soda", "category": "ANTONYMS", "visible": true, "enable": true } ,Commons
Commons are names without context that can mean anything, for example, "
field", "code", or "number". When matching complex names, Data Catalog cannot match names that are on the Commons list. In the following example, Data Catalog will not match "state", "states", "address", or "location"."common_geo": { "value": "state,states,address,location", "category": "COMMON", "visible": true, "enable": true } ,Exceptions
Exceptions are names that are ignored for tag discovery. In the following example, Data Catalog treats all the names in the
valueentry as exceptions (including "count", "field", "filler", and so on), so they are ignored."exception_common_fields": { "value": "count,field,filler,col,name,status,code,colname,sysname,c, colz,cols,desc,description,num,number, dt,comment,type,owner", "category": "EXCEPTIONS", "visible": true, "enable": true} ,Exceptions normally are ambiguous names that can be used as the name for fields. Not having exceptions for those names may produce a high volume of false positives for attribute analysis. Exceptions are different from Commons in that Data Catalog will never match a name in the Exceptions list, but it will match a name in the Commons list if the name is part of a complex name. For example, if "
id" is on the Exceptions list, Data Catalog will not match it in "customer.id", but it will match if "id" is in the Commons list.For display purposes, the thesaurus can have multiple groups of exceptions, such as
"exception_common_fields" and "exception_ids". Data Catalog treats all exception lists as one list, and they are not used in algorithms. Separation into multiple groups is for user convenience only.