Use PDI outside and inside the Hadoop cluster
PDI is unique in that it can execute both outside of a Hadoop cluster and within the nodes of a Hadoop cluster. From outside a Hadoop cluster, PDI can extract data from or load data into Hadoop HDFS, Hive and HBase. When executed within the Hadoop cluster, PDI transformations can be used as Mapper and/or Reducer tasks, allowing PDI with Pentaho MapReduce to be used as visual programming tool for MapReduce.
Pentaho MapReduce workflow
PDI and Pentaho MapReduce enables you to pull data from a Hadoop cluster, transform it, and pass it back to the cluster. Here is how you would approach doing this.
PDI Transformation
Start by deciding what you want to do with your data, open a PDI transformation, and drag the appropriate steps onto the canvas, configuring the steps to meet your data requirements. Drag the specifically-designed Hadoop MapReduce Input and Hadoop MapReduce Output steps onto the canvas. PDI provides these steps to completely avoid the need to write Java classes for this functionality. Configure both of these steps as needed. Once you have configured all the steps, add hops to sequence the steps as a transformation. Follow the workflow as shown in this sample transformation in order to properly communicate with Hadoop. Name this transformation Mapper.
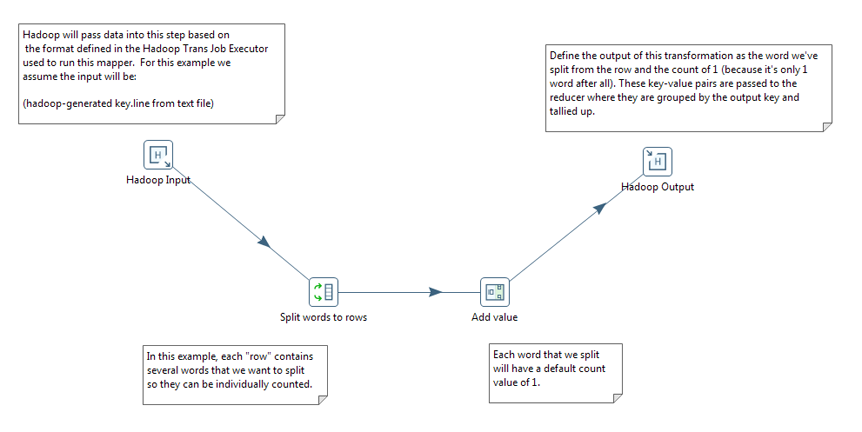
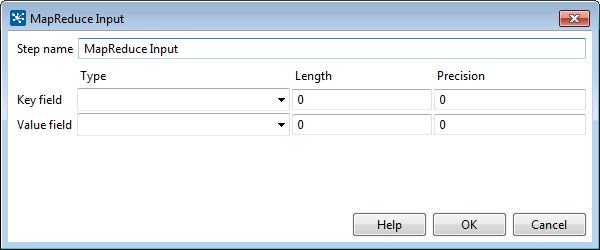
Hadoop communicates in key/value pairs. PDI uses the MapReduce Input step to define how key/value pairs from Hadoop are interpreted by PDI. The MapReduce Input dialog box enables you to configure the MapReduce Input step.
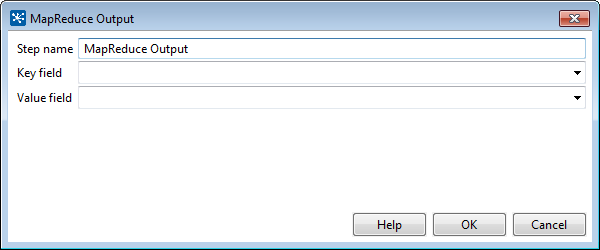
PDI uses a MapReduce Output step to pass the output back to Hadoop. The MapReduce Output dialog box enables you to configure the MapReduce Output step.
What happens in the middle is entirely up to you. Pentaho provides many sample steps you can alter to create the functionality you need.
PDI Job
Once you have created the Mapper transformation, you are ready to include it in a Pentaho MapReduce job entry and build a MapReduce job.
Open a PDI job and drag the specifically-designed Pentaho MapReduce job entry onto the canvas. In addition to ordinary transformation work, this entry is designed to execute mapper/reducer functions within PDI. Again, no need to provide a Java class to achieve this.
Configure the Pentaho MapReduce entry to use the transformation as a mapper. Drag and drop a Start job entry, other job entries as needed, and result job entries to handle the output onto the canvas. Add hops to sequence the entries into a job that you execute in PDI.
The workflow for the job should look something like this.
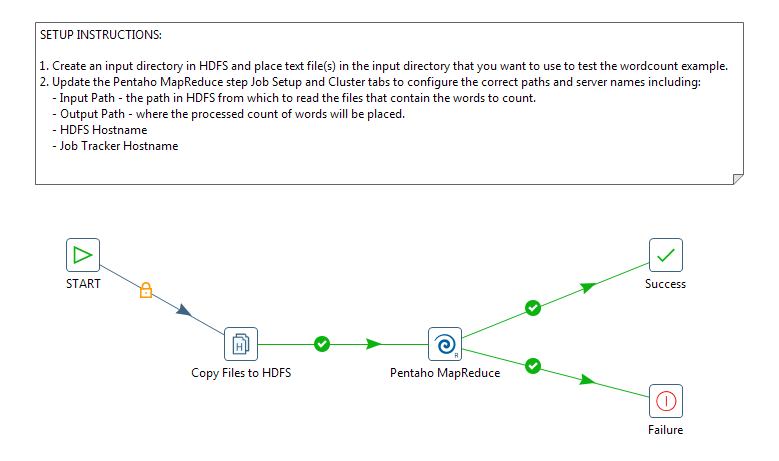
The Pentaho MapReduce dialog box enables you to configure the Pentaho MapReduce entry.
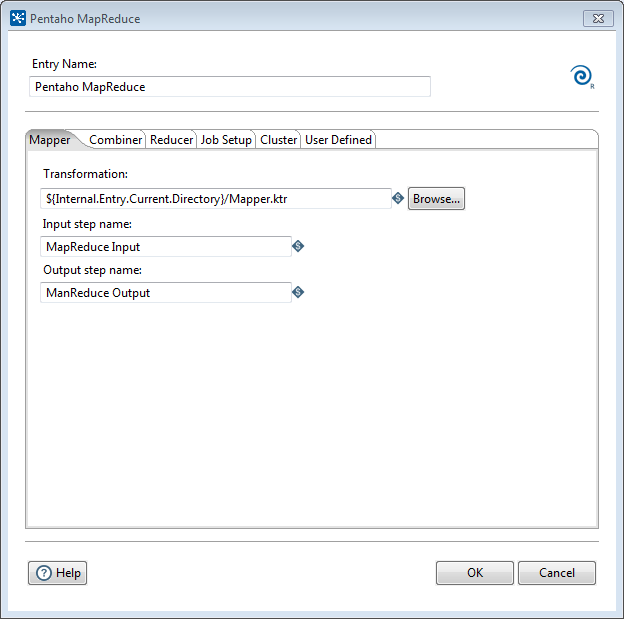
PDI Hadoop job workflow
PDI enables you to execute a Java class from within a PDI client job to perform operations on Hadoop data. The way you approach doing this is similar to the way would for any other PDI job. The specifically-designed job entry that handles the Java class is Hadoop Job Executor. In this illustration it is used in the WordCount - Advanced entry.
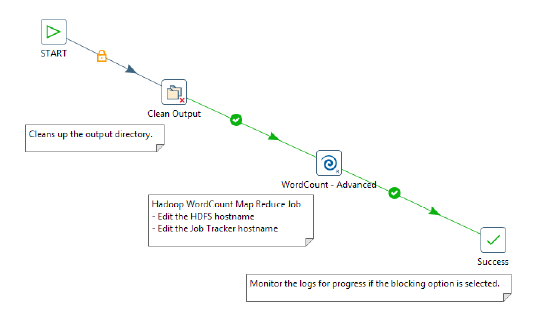
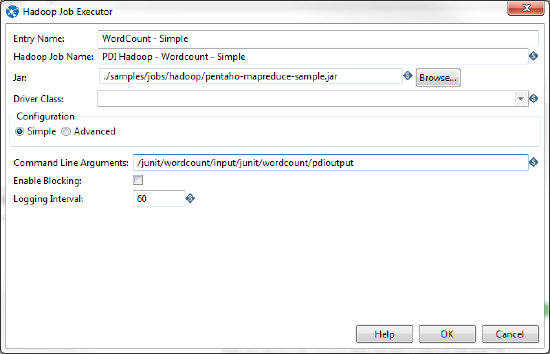
The Hadoop Job Executor dialog box enables you to configure the entry with a .jar file that contains the Java class.
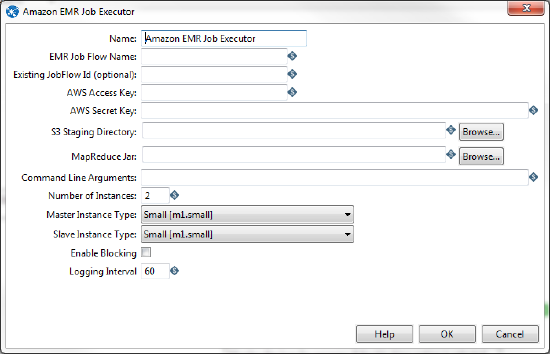
If you are using the Amazon Elastic MapReduce (EMR) service, you can use the Amazon EMR Job Executor job entry to execute the Java class. This differs from the standard Hadoop Job Executor in that it contains connection information for Amazon S3 and configuration options for EMR.
Hadoop to PDI data type conversion
The Hadoop Job Executor and Pentaho MapReduce steps have an advanced configuration mode that enables you to specify data types for the job's input and output. PDI is unable to detect foreign data types on its own; therefore you must specify the input and output data types in the Job Setup tab.
This table explains the relationship between Hadoop data types and their PDI equivalents.
| PDI (Kettle) Data Type | Apache Hadoop Data Type |
java.lang.Integer | org.apache.hadoop.io.IntWritable |
java.lang.Long | org.apache.hadoop.io.IntWritable |
java.lang.Long | org.apache.hadoop.io.LongWritable |
org.apache.hadoop.io.IntWritable | java.lang.Long |
java.lang.String | org.apache.hadoop.io.Text |
java.lang.String | org.apache.hadoop.io.IntWritable |
org.apache.hadoop.io.LongWritable | org.apache.hadoop.io.Text |
org.apache.hadoop.io.LongWritable | java.lang.Long |
For more information on configuring Pentaho MapReduce to convert to additional data types, see Pentaho MapReduce.
Hadoop Hive-specific SQL limitations
There are a few key limitations in Hive that prevent some regular Metadata Editor features from working as intended, and limit the structure of your SQL queries in Report Designer:
- Outer joins are not supported.
- Each column can only be used once in a
SELECTclause. Duplicate columns inSELECTstatements cause errors. - Conditional joins can only use the = conditional unless you use a
WHEREclause. Any non-equal conditional in aFROMstatement forces the Metadata Editor to use a cartesian join and aWHEREclause conditional to limit it. This is not much of a limitation, but it may seem unusual to experienced Metadata Editor users who are accustomed to working with SQL databases. INSERTstatements have a specific syntax and some limitations. Hive 0.14 supports insert statements with a specific syntax:INSERT INTO TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)] VALUES values_row [, values_row ...]. There are also some limitations surrounding use of theINSERTstatement with theSORTEDBY clause, non-support of literals for complex types, and the insertion of values into columns. For more details see:
Big data tutorials
Pentaho big data tutorials provide examples of how you can use Pentaho technology as part of your overall big data strategy. Each section is a series of scenario-based tutorials that demonstrate the integration between Pentaho and Hadoop using a sample data set.
Big data tutorials can be found here:
- Hadoop: http://wiki.pentaho.com/display/BAD/Hadoop
- MongoDB: http://wiki.pentaho.com/display/BAD/MongoDB
- Cassandra: http://wiki.pentaho.com/display/BAD/Cassandra
The following videos also help demonstrate using PDI to work with Hadoop from both inside and outside a Hadoop cluster.
- Loading data into Hadoop from outside the Hadoop cluster is a 5-minute video that demonstrates moving data using a PDI job and transformation: https://www.youtube.com/watch?v=Ylekzmd6TAc
- Use Pentaho MapReduce to interactively design a data flow for a MapReduce job without writing scripts or code. Here is a 12 minute video that provides an overview of the process: https://www.youtube.com/watch?v=KZe1UugxXcs