Sort rows
This step sorts rows based on the fields you specify and on whether they should be sorted in ascending or descending order.
When you use multiple copies of this step in a transformation in parallel, merge together each of the sorted blocks to ensure the proper sort sequence. You can further ensure the proper sequence by adding a Sorted Merge step immediately following the last Sort rows step.
You can create this type of transformation on the local Java Virtual Machine (JVM) with the Change number of copies to start option or in a clustered environment using Carte. The Change Number of copies to Start option is available through the Transformation menu. Right-click any step in the transformation canvas to open the Transformation menu.
General
Enter the following information for the step:
- Step name: Specify the unique name of the transformation on the canvas. You can customize the name or leave it as the default.
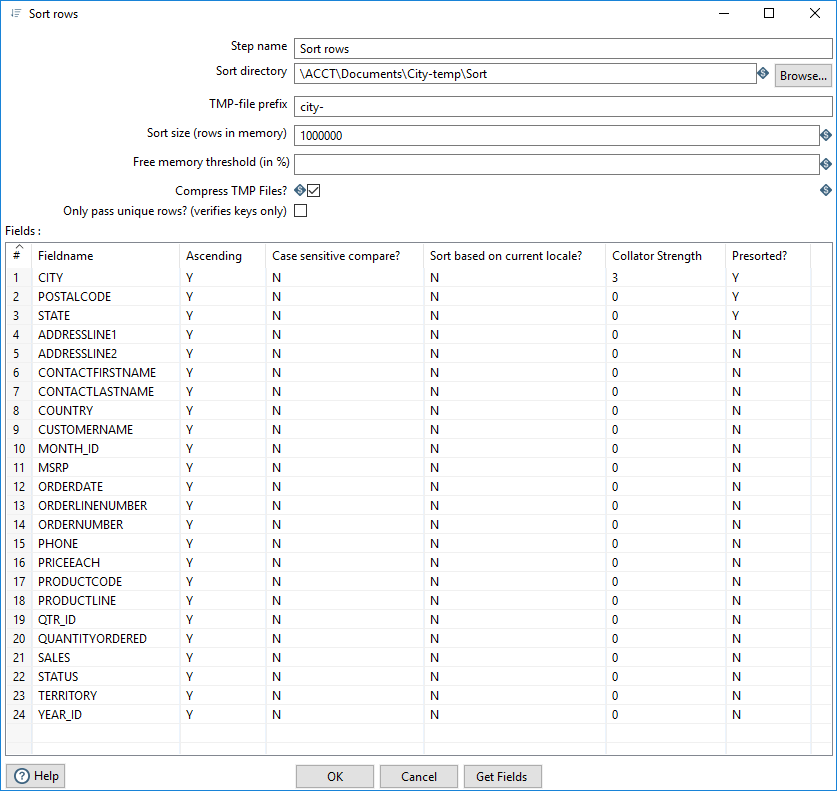
Options
The Sort rows step includes options to define your output and how you want to sort rows.
| Option | Description |
| Sort directory | Select a directory in which temporary files can be stored, if needed. If you leave this blank, the temporary files are stored in the default temporary directory for the system. Click Browse to select a different directory. |
| TMP-file prefix | Specify a prefix for the temporary files. This helps you identify any files generated by the transformation in the temp directory. |
| Sort size (rows in memory) | Specify the number of rows to sort in memory. A larger number improves the sort speed, since fewer temporary files are generated, consuming less input/output processing. Default is: 1000000 rows.
NoteYou may encounter an Out Of Memory Exception (OOME) if the number of rows in memory exceeds the number specified in this option. To resolve the OOME, either lower the sort size specified here or change your available memory. See Increase the PDI client memory limit.
|
| Free memory threshold (in %) | Specify a percentage number as the threshold. If the sort algorithm has less available free memory than the indicated number, it will begin paging data to disk.
This percentage varies per individual production environment because the threshold is re-verified every 1000 rows. The row size, the complexity of the transformation, or other steps in the transformation could still lead to an Out Of Memory Error. In a JVM, the exact amount of free memory varies. As a best practice, use this step in less complex transformations that do not require several steps or several processes that are contending for memory. |
| Compress TMP Files | Select this option to compress any temporary files that are generated to complete the sort. Clear this option to leave temporary files uncompressed. |
| Only pass unique rows? (verifies keys only) | Select this option to pass only unique rows to the output stream(s). Clear this option to pass all rows to the output stream(s). |
| Fields table | Specify the fields and direction, ascending or descending, to sort. You can also specify whether to perform a case-sensitive sort. Click the column titles to sort each column. |
| Get Fields | Click Get fields to retrieve a list of all the incoming fields on the stream(s). |
Fields column settings
The Sort rows step includes options to refine your sort based on settings for the individual fields. Click the column titles to sort each column.
| Setting | Description |
| Field names | Name of the field on the stream. |
| Ascending | Specify Y to sort in ascending order. Specify N to sort in descending order. |
| Case sensitive compare? | Specify Y to sort by case usage. Specify N to ignore case. |
| Sort based on current locale? | Specify Y to sort based on the system's current locale. Specify N to sort based on a standard UTF-8. |
| Collator strength | If you selected Y for Sort based on current locale?, specify an integer between 0 and 3 that defines what type of conditional differences govern or override when performing a sort. Exact definitions of each strength vary by locale.
|
| Presorted? | Select Y if the data in this field is already sorted. Presorting improves sort efficiency. If you select Y, this field must be either the first, or among the first set of fields in the list. Click Presorted? to sort and move all the presorted fields to the top of the table. Select N if the data in this field is not sorted. |
Metadata injection support
All fields of this step support metadata injection. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.