Discover metadata from a text file
Use the Discover metadata from a Text file step to determine the structure and metadata of delimited text files for which you have limited knowledge of the structure. Enter a list of possible delimiters, enclosures, and escape characters to determine the configuration that produces the most consistent match of data in the file. Consistency is determined by the count of fields in the rows. For example, when testing a semi-colon as the delimiter, the count of fields in the first three rows is 3, 8, and 4, which means the field count is inconsistent; therefore, the semi-colon is not the correct delimiter. When testing a comma delimiter on those rows produces a field count of 6, 6, and 6, this is considered a consistent delimiter and is an acceptable candidate for use.
You can use this step to generate data to send to the ETL Metadata Injection step. The ETL Metadata Injection step can then set up the metadata in the Text File Input step for use in your transformations or jobs.
The Discover metadata from a Text file step also determines the field names from the header row and predicts the data types for the list of fields.
General
Enter the following information in the transformation step field.
- Step Name: Specifies the unique name of the Discover metadata from a text file step on the canvas. You can customize the name or leave it as the default.
Options
The Discover metadata from a text file step consists of four tabs: Input, Delimiter candidates, Enclosure candidates, and Escape candidates. Each tab is described below.
Input tab
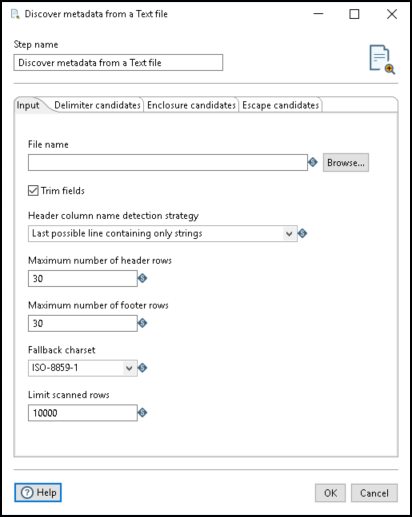
Use the following options in the Input tab to specify details for the input text file:
| Option | Description |
| File name | Select the delimited file you want to evaluate. The file location can be any location supported by a VFS connection. See Connecting to Virtual File Systems |
| Trim fields | Select this option to identify the field as an integer. Clear the option to indicate that the field is a string. |
| Header column name detection strategy | Select the strategy you want to use to determine the column names in the file. Once a header row has been determined, any rows of data above that are ignored, the following rows
are counted as data. The following strategies are available:
|
| Maximum number of header rows | Enter the maximum number of rows that can be a header. If the file does not have a header row, set this to 0. Only one row can be a header. |
| Maximum number of footer rows | Enter the maximum number of rows that can be a footer. If the file does not have a footer row, set this to 0. NoteThe number of footer rows can only be determined if the entire
file is scanned. |
| Fallback charset | Select the character set of the file. If the step is unable to determine a character set for the file, it defaults to the ISO-8859-1 character set. If an x86 platform is used, the file uses an ASCII character set. |
| Limit scanned rows | Enter the number of rows to scan in the file before determining the valid set of delimiters and enclosures used in the file. To scan the entire file, enter 0 (zero). |
Delimiter candidates tab
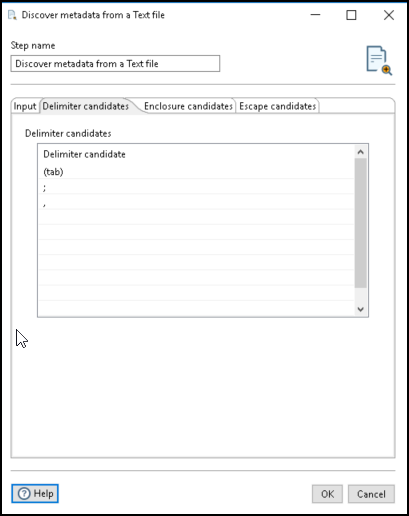
Enter the delimiter candidates you want to use in the file scan in the Delimiter candidates field of the Delimiter candidates tab. The delimiter candidates can be one or more characters. The step tests each candidate and all combinations of the candidates to find the most accurate match. For example, you may receive a file from two sources where the first source uses a comma delimiter and the second source uses a semi-colon delimiter. The step can determine the data structure of both files.
Enclosure candidates tab
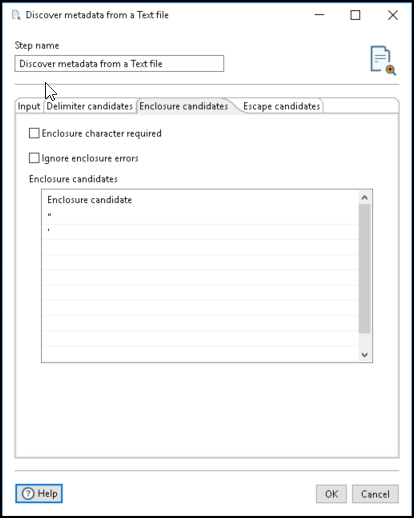
You can enter characters you want to use for enclosures on the Enclosure candidates tab. The available options are listed in the following table:
| Option | Description |
| Enclosure character required | Select to require that all fields must be enclosed with enclosure characters. When this field is not selected, enclosure characters are optional. |
| Ignore enclosure errors | Select to ignore enclosure errors when a row is parsed that contains a different number of fields. Clear the option to generate enclosure errors which stops the step from continuing. |
| Enclosure candidates | Enter the enclosure characters you want to use for the file scanning. Enclosure candidates can be one or more characters. |
Escape candidates tab
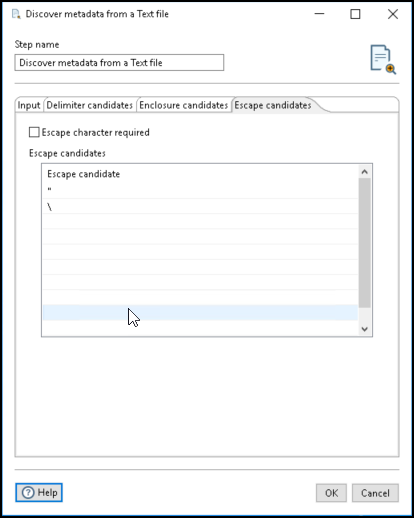
Use the Escape candidates tab to require and define escape characters. The available options are listed in the following table:
| Option | Description |
| Escape character required | Check to require an escape character. When cleared, the step does not consider any characters as an escape character. |
| Escape candidates | Enter a character to use for an escape character. Escape candidates can be one or more characters. |
Delimiter and data type detection rules
Because there are many different variations of delimited files, this step may not be able to detect the structure of every type of delimited file. The following rules are used to evaluate fields:
- The step uses a left outer cartesian join of the delimiter, enclosure, and escape candidate options.
- The step performs inner joins when the Enclosure character required or Escape is required options are enabled. This means that a null enclosure or a null escape is not allowed.
- The delimiter character cannot be the same as the enclosure or escape characters. For example, using double quotes (“) for both your enclosure and escape characters. The step will not fail when this happens, but it will ignore that candidate combination.
- If the enclosure character and escape characters are the same, the delimiter can not be escaped. Only the enclosure character can be escaped.
- If any enclosure errors are found such as an unclosed enclosure or an unescaped enclosure character, the enclosure will not be considered valid. If the enclosure errors are valid, select the Ignore Enclosure errors option.
- A header row is defined as any row within the Maximum number of header rows value with a number of fields consistent with the number of fields in the data. The row
after the last inconsistent row may also be considered a header row if the:
- Header row strategy is first strings and the first row that only contains string values is the next row after the last inconsistent row.
- Header row strategy is first any data type and there are no rows with a consistent number of fields prior to the last inconsistent row.
- Header row strategy is last strings and the next row after the last inconsistent row is all strings.
- Header row strategy is last any data type.
- A footer row is defined as the first row with an inconsistent number of fields and any following rows. When the Limit scanned rows option prevents the entire file from being read, the file is not evaluated for footer rows.
- If multiple delimiters, enclosures, or escape characters appear to match the file, the step is unable to determine the format.
- Multiple character enclosures or escapes may result in incorrect data type results.
- Ignoring enclosure errors may result in incorrect data type results.
- The field length is determined by the length of the longest field detected during the scan. Note that if the Limit scanned rows option is set, then only that many rows of data will be checked.
Examples
Your Pentaho distribution includes several sample transformations and datasets in the design-tools/data-integration/samples/transformations/discover-metadata-from-textfile directory.
The following code is a portion of the Sample1.txt file found in the directory:
policyID,county,eq_site_limit,eq_site_deductible,point_longitude 710400,CLAY COUNTY,0,0,-81.71624 703001,CLAY COUNTY,0,0,-81.706865 352792,CLAY COUNTY,0,0,-81.718452 717603,CLAY COUNTY,0,0,-81.718452 937659,SUWANNEE COUNTY,0,0,-82.926659 294022,SUWANNEE COUNTY,0,0,-82.926659 410500,SUWANNEE COUNTY,0,0,-82.926659 524433,SUWANNEE COUNTY,218475,0,-82.926155 972562,SUWANNEE COUNTY,0,0,-82.933777
When the step is run, the file is scanned to determine a consistent number of fields using the tab character, then the semi-colon, then the comma (default). When the Header column name detection strategy is set to First possible line containing only strings, the step identifies the first row as the header row. The following table shows the column names and data types.
| column name | data type |
| policylD2 | Integer |
| county | String |
| eq_site_limit | BigNumber |
| eq_site_deductible | Integer |
| point_longitude | BigNumber |
Data lineage
This step includes a data lineage analyzer. See Data lineage
Metadata injection support
All fields of this step support metadata injection. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.