Contribute additional step and job entry analyzers to the Pentaho Metaverse
The Pentaho Metaverse provides metadata lineage capabilities for the Pentaho universe. Pentaho Data Integration (PDI) is a major source of lineage information. The metaverse mines metadata and builds a connected relationship model among all the pieces it knows about. The end result is a graph model which allows for lineage (finding where/what contributed to something) and impact analysis (determining what would be affected downstream if something where changed). The metaverse leverages OSGi (blueprints) to allow for modularity and extensibility. Therefore, if something is not supported out-of-the-box by the metaverse, the metaverse can accept components via OSGi bundles which extend its capabilities.
Kettle supports transformations and jobs, each of which is composed of smaller bite-sized operations. A transformation is made up of steps and a job is made up of job entries. Conceptually, these can be thought of as analogs. Kettle provides hundreds of unique steps and job entries which each perform a specific task. As far as the metaverse is concerned, each one of these steps and job entries is a potential source of metadata with respect to lineage.
The metaverse is composed of analyzers which are responsible for mining lineage information from a specific "thing." There are document analyzers which know how to extract the lineage information from documents. PDI produces two document types, transformations (KTR) and jobs (KJB), and for each there is a corresponding document analyzer. Each one analyzes the sub-components, the steps comprising a transformation and the job entries comprising a job, and assigns each subcomponent a specific step analyzer or job entry analyzer if one exists for the implementation of BaseStepMeta.
The out-of-the-box set of analyzers is limited. In the case of a step or job entry not having a corresponding analyzer, there is a generic fallback analyzer. To contribute a new step or job entry analyzer to the system, you can implement the required interface(s) and register a service via OSGI (blueprints) to become available to the system.
Examples
The preferred approach to adding a step analyzer is through OSGi. We realize that there are many legacy PDI plugins which provide steps and job entries. While it is not part of this project to convert these plugins to OSGi for the purpose of contributing analyzers, you can add step analyzers to an existing PDI plugin. Jump down to the section dedicated to this purpose.
This example will outline the steps taken to create the sample-metaverse-bundle. It demonstrates how to create a new step analyzer for the Table Input step.
Create a new Maven project
The easiest way to get started is to use the karaf-bundle-archetype to create a new Maven project, which generates a bundle artifact that works in a Karaf container.
mvn archetype:generate \ -DarchetypeGroupId=org.apache.karaf.archetypes \ -DarchetypeArtifactId=karaf-bundle-archetype \ -DarchetypeVersion=2.2.11 \ -DgroupId=your.company \ -DartifactId=your-artifact-id \ -Dversion=1.0-SNAPSHOT \ -Dpackage=your.company.package \
Add dependencies
Add Maven dependencies to pentaho-metaverse-api and kettle jars in your pom.xml file.
<dependency> <groupId>pentaho</groupId> <artifactId>pentaho-metaverse-api</artifactId> <version>7.1.0.0-12</version> <type>bundle</type> </dependency> <dependency> <groupId>pentaho-kettle</groupId> <artifactId>kettle-core</artifactId> <version>7.1.0.0-12</version> </dependency> <dependency> <groupId>pentaho-kettle</groupId> <artifactId>kettle-engine</artifactId> <version>7.1.0.0-12</version> </dependency>
Create a class which implements IStepAnalyzer
At a minimum, you will need to create a java class which implements the IStepAnalyzer interface (for a job entry analyzer, you would implement IJobEntryAnalyzer). The IStepAnalyzer interface only requires that you implement the analyzer and getSupportedSteps methods. It is fairly black-box and does not do much to make the developer's life much easier. Step analyzers follow a common pattern:
- Model the step itself in the graph as a node.
- Link all stream fields which are inputs into the step to that node, if any.
- Determine the outputs of the step, if any, then create and link those nodes to the step node.
- Add links to the fields which the step actually uses, if any.
- Add links from the input fields to the output fields.
Virtually, all implementations would benefit by extending the common base class StepAnalyzer which provides a common implementation for all of those common tasks. Below, is a simple implementation of a step analyzer for the Dummy step. There is nothing special about this step which warrants a custom step analyzer, but for the purpose of this document we will add a custom property to the step node. This is done in the customAnalyzer method:
public class DummyStepAnalyzer extends StepAnalyzer<DummyTransMeta> {
@Override
protected Set<StepField> getUsedFields( DummyTransMeta meta ) {
// no incoming fields are used by the Dummy step
return null;
}
@Override
protected void customAnalyze( DummyTransMeta meta, IMetaverseNode rootNode ) throws MetaverseAnalyzerException {
// add any custom properties or relationships here
rootNode.setProperty( "do_nothing", true );
}
@Override
public Set<Class<? extends BaseStepMeta>> getSupportedSteps() {
Set<Class<? extends BaseStepMeta>> supportedSteps = new HashSet<>();
supportedSteps.add( DummyTransMeta.class );
return supportedSteps;
}
}
Create the Blueprint configuration
Blueprint provides a dependency injection framework for OSGi. The metaverse has two injection points. It has a reference list of all services registered in the container for both the IStepAnalyzer interfaces and the IJobEntryAnalyzer interfaces. When the container detects a new service which provides an implementation of one of those interfaces, the metaverse sees it and adds it to its set of known analyzers. The next time a step which implements the particular class you care about, such as DummyTransMeta in our example, is analyzed, your new StepAnalyzers will be used and your override methods will be called.
Create a blueprint.xml file in src/main/resources/OSGI-INF/blueprint/ folder. (Create the folders, if needed.)
<?xml version="1.0" encoding="UTF-8"?>
<blueprint xmlns="http://www.osgi.org/xmlns/blueprint/v1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.osgi.org/xmlns/blueprint/v1.0.0 http://www.osgi.org/xmlns/blueprint/v1.0.0/blueprint.xsd
">
<!-- Define a bean for our new step analyzer -->
<bean id="dummyStepAnalyzer"/>
<!--
Define our analyzer as a service. This will allow it to be automatically added to the reference-list ultimately used
by the TransformationAnalyzer to determine if there is a custom analyzer for a particular BaseStepMeta impl
(DummyTransMeta in this case).
-->
<service id="dummyStepAnalyzerService"
interface="org.pentaho.metaverse.api.analyzer.kettle.step.IStepAnalyzer"
ref="dummyStepAnalyzer"/>
</blueprint>
Build and test your bundle
Build your bundle with Maven and have it installed into your local Maven repository. Once there, you can test it out in the Pentaho Server.
mvn install
Start up Pentaho Data Integration in debug mode. Once started, ssh into the running karaf container. The ssh credentials are karaf/karaf.
OPT="$OPT -Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=5005" ./spoon.sh # from another terminal window... ssh -p 8102 karaf@localhost # when prompted, password = karaf
Install your bundle from the Maven repository.
# make sure the pentaho-metaverse feature is installed admin@root> features:list | grep pentaho-metaverse [installed ] [7.1.0.0-12 ] pentaho-metaverse repo-0 # install from local maven repository & start your bundle admin@root> install mvn:pentaho/sample-metaverse-bundle/7.1.0.0-12 Bundle ID: 241 admin@root> start 241 Starting the bundle
See it in action
Procedure
Save a transformation which contains a step you want to explore with the analyzer. (In the sample, use the Table Input step).
Connect a remote debugger to PDI on port 5005. Enter a breakpoint in your step analyzer's implementation.
Execute your transformation from PDI.
You should hit your breakpoint when the step you are exploring is assessed by the transformation analyzer.
Results
Different types of step analyzers
In the process of implementing custom step analyzers, we discovered a few generic patterns based on the type of step.
- First, there are the traditional steps which just take some input fields, manipulate them in some fashion, and then output them.
- The second type are the input and output steps. These steps use an external resource (file, database, web service, etc) to read or write data.
- The last is a more specific type of the second, and one which requires a logical connection to an external resource, typically a database or noSQL data store.
These patterns are the basis for the three main base classes you might consider extending when implementing a custom step analyzer.
Field manipulation
If the step you are writing a custom analyzer for is just a traditional step which manipulates data or fields to produce different outputs than inputs, then you should extend your step analyzer. An example of this kind of step analyzer would be Strings Cut. It is much easier to understand the graph model when looking at it.
Below is the basic graph model for the Strings Cut step:
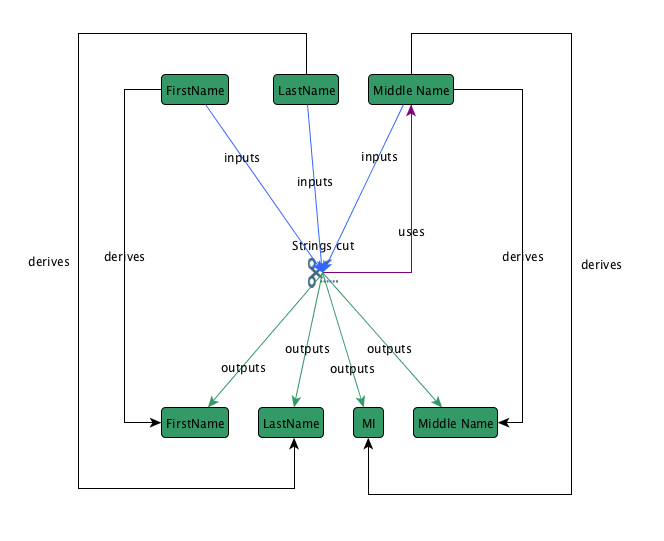
In this example, three fields are inputs into the step: FirstName, LastName, and Middle Name. Four fields are derived as the outputs: FirstName, LastName, MI (middle initial), and Middle Name. In the example below, the Strings Cut step uses just the Middle Name input field to create the MI output field from the first character.
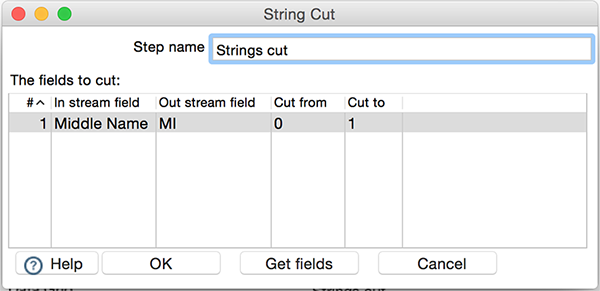
Override the getUsedFields method to supply the fields used by the step. In the example above, the only input field used by the step is Middle Name.
@Override
protected Set<StepField> getUsedFields( StringCutMeta meta ) {
HashSet<StepField> usedFields = new HashSet<>();
for ( String fieldInString : meta.getFieldInStream() ) {
usedFields.addAll( createStepFields( fieldInString, getInputs() ) );
}
return usedFields;
}To supply the non-passthrough derives links and operation information, override the getChangeRecords method. In the above example, the non-passthrough derived link from the Middle Name input field to the MI output field is created from this override method.
@Override
public Set<ComponentDerivationRecord> getChangeRecords( StringCutMeta meta ) throws MetaverseAnalyzerException {
Set<ComponentDerivationRecord> changeRecords = new HashSet<>();
for ( int i = 0; i < meta.getFieldInStream().length; i++ ) {
String fieldInString = meta.getFieldInStream()[i];
String fieldOutString = meta.getFieldOutStream()[i];
if ( fieldOutString == null || fieldOutString.length() < 1 ) {
fieldOutString = fieldInString;
}
ComponentDerivationRecord changeRecord = new ComponentDerivationRecord( fieldInString, fieldOutString, ChangeType.DATA );
String changeOperation = fieldInString + " -> [ substring [ " + meta.getCutFrom()[i] + ", "
+ meta.getCutTo()[i] + " ] ] -> " + fieldOutString;
changeRecord.addOperation( new Operation( Operation.CALC_CATEGORY, ChangeType.DATA,
DictionaryConst.PROPERTY_TRANSFORMS, changeOperation ) );
changeRecords.add( changeRecord );
}
return changeRecords;
}By default, the implementation determines if a field is a passthrough field or not. If this logic isn't sufficient for your step, then override the isPassthrough method like the StringsCutStepAnalyzer does. The default logic assumes that if there is an output field with an identical name as an input field, then it is a passthrough.
/**
* Determines if a field is considered a passthrough field or not. In this case, if we're not using the field, it's
* a passthrough. If we are using the field, then it is only a passthrough if we're renaming the field on which we
* perform the operation(s).
*
* @param originalFieldName The name of the incoming field
* @return true if this field is a passthrough (i.e. no operations are performed on it), false otherwise
*/
@Override
protected boolean isPassthrough( StepField originalFieldName ) {
String[] inFields = baseStepMeta.getFieldInStream();
String origFieldName = originalFieldName.getFieldName();
for ( int i = 0; i < inFields.length; i++ ) {
if ( inFields[i].equals( origFieldName ) && Const.isEmpty( baseStepMeta.getFieldOutStream()[i] ) ) {
return false;
}
}
return true;
}External resource
If you are writing a custom analyzer for a step which reads or writes data from an external source like a file, extend ExternalResourceStepAnalyzer. An example analyzer that extends this is TextFileOutputStepAnalyzer.
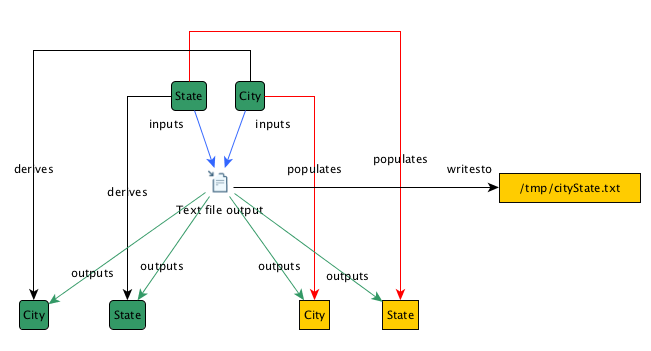
Above is a typical file-based output step graph diagram (CSV would be very similar). This kind of step analyzer is different in that it creates resource nodes for fields and files which it touches (the yellow boxes). To accomplish this in a custom step analyzer, there are a few steps you must take. First, you must implement the abstract methods defined in ExternalResourceStepAnalyzer:
@Override
public String getResourceInputNodeType() {
return null;
}
@Override
public String getResourceOutputNodeType() {
return DictionaryConst.NODE_TYPE_FILE_FIELD;
}
@Override
public boolean isOutput() {
return true;
}
@Override
public boolean isInput() {
return false;
}
@Override
public IMetaverseNode createResourceNode( IExternalResourceInfo resource ) throws MetaverseException {
return createFileNode( resource.getName(), descriptor );
}
Next, you need to create a class which implements IStepExternalResourceConsumer. You will want to extend the base class BaseStepExternalResourceConsumer to help make your job a bit easier. External Resource Consumers are used in two places: once when the execution profiles are generated to determine what resources are read from/written to, and once by the step analyzers. In your blueprint.xml file, you will need to define the bean, publish the service, and inject the bean into your step analyzer:
<!-- Define the bean for the step analyzer, inject the external resource consumer -->
<bean id="TextFileOutputStepAnalyzer"
class="org.pentaho.metaverse.analyzer.kettle.step.textfileoutput.TextFileOutputStepAnalyzer">
<property name="externalResourceConsumer" ref="textFileOutputERC"/>
</bean>
<!--
Define our analyzer as a service. This will allow it to be automatically added to the reference-list ultimately used
by the TransformationAnalyzer to determine if there is a custom analyzer for a particular BaseStepMeta impl
(TableInputMeta in this case).
-->
<service id="textFileOutputStepAnalyzerService"
interface="org.pentaho.metaverse.api.analyzer.kettle.step.IStepAnalyzer"
ref="TextFileOutputStepAnalyzer"/>
<!-- Define the external resource consumer bean -->
<bean id="textFileOutputERC" scope="singleton"
class="org.pentaho.metaverse.analyzer.kettle.step.textfileoutput.TextFileOutputExternalResourceConsumer"/>
<!--
Define the external resource consumer as a service so it will get added to the reference-list of all IStepExternalResourceConsumer's.
-->
<service id="textFileOutputERCService"
interface="org.pentaho.metaverse.api.analyzer.kettle.step.IStepExternalResourceConsumer"
ref="textFileOutputERC"/>
The custom logic portions of the TextFileOutputStepAnalyzer are in the fields it uses, and this logic determines the fields which are actually written to the file.
@Override
protected Set<StepField> getUsedFields( TextFileOutputMeta meta ) {
Set<StepField> usedFields = new HashSet<>();
// we only "use" one field IF we are getting the file to write to from a field in the stream
if ( meta.isFileNameInField() ) {
usedFields.addAll( createStepFields( meta.getFileNameField(), getInputs() ) );
}
return usedFields;
}
@Override
public Set<String> getOutputResourceFields( TextFileOutputMeta meta ) {
// TextFileOutput doesn't force you to write all input fields out to the file, you can pick which ones you want.
// The default impl of this method assumes you want all inputs.
Set<String> fields = new HashSet<>();
TextFileField[] outputFields = meta.getOutputFields();
for ( int i = 0; i < outputFields.length; i++ ) {
TextFileField outputField = outputFields[ i ];
fields.add( outputField.getName() );
}
return fields;
}
Connection-based external resource
If the step you are writing a custom analyzer for is using a connection like a database connection, then you should extend ConnectionExternalResourceStepAnalyzer. An example of this type of analyzer is TableOutputStepAnalyzer. Connection-based analyzers are just a more specific type of step analyzer than the external resource step analyzers. It is an external resource analyzer which also has a connection analyzer and understands the concept of a table.
All IStepAnalyzers can optionally support the notion of a property called connectionAnalyzer. A connection analyzer is a specific type of analyzer. Its job is to build the relationships and nodes for an external connection. Some examples of connection analyzers are for traditional databases, noSQL databases, HDFS, etc. The metaverse exposes two IDatabaseConnection analyzers for reuse in external bundles (like the one outlined here). You can inject either stepDatabaseConnectionAnalyzer or jobEntryConnectionAnalyzer into your analyzer by grabbing hold of a reference to the exposed service (see below). If you need a custom connectionAnalyzer, you can implement your own and use that in your bundle.
<!--
If you are defining your resource in a separate bundle, grab a reference to the IDatabaseConnectionAnalyzer
for steps provided by the core pentaho-metaverse bundle.
This will be injected into analyzer (TableOutputStepAnalyzer)
-->
<reference id="stepDatabaseConnectionAnalyzerRef"
interface="org.pentaho.metaverse.api.analyzer.kettle.IDatabaseConnectionAnalyzer"
component-name="stepDatabaseConnectionAnalyzer"
availability="mandatory"/>
<!--
Declare our sample analyzer(TableOutputStepAnalyzer) bean. Inject the stepDatabaseConnectionAnalyzer so it can
use the same one that the TableOutputStepAnalyzer uses.
-->
<bean id="tableOutputStepAnalyzer" class="org.pentaho.metaverse.analyzer.kettle.step.tableoutput.TableOutputStepAnalyzer">
<property name="connectionAnalyzer" ref="stepDatabaseConnectionAnalyzerRef"/>
<property name="externalResourceConsumer" ref="tableOutputERC"/>
</bean>
<!--
Define our analyzer as a service. This will allow it to be automatically added to the reference-list ultimately used
by the TransformationAnalyzer to determine if there is a custom analyzer for a particular BaseStepMeta impl
(TableOutputMeta in this case).
-->
<service id="tableOutputStepAnalyzerService"
interface="org.pentaho.metaverse.api.analyzer.kettle.step.IStepAnalyzer"
ref="tableOutputStepAnalyzer"/>
<!-- Configure the TableOutputExternalResourceConsumer and service -->
<bean id="tableOutputERC" scope="singleton"
class="org.pentaho.metaverse.analyzer.kettle.step.tableoutput.TableOutputExternalResourceConsumer"/>
<service id="tableOutputERCService"
interface="org.pentaho.metaverse.api.analyzer.kettle.step.IStepExternalResourceConsumer"
ref="tableOutputERC"/>
Adding analyzers from existing PDI plug-ins (non-OSGi)
You can add analyzers from existing PDI non-OSGi plug-ins. For examples of custom analyzers and external resource consumers, see GitHub - pentaho/pentaho-metaverse for details.
When adding analyzers, you still need to add a compile-time dependency to the pentaho-metaverse-api JAR file and you must also create your StepAnalyzer class.
The main difference is how you register your analyzer with the rest of the metaverse analyzers. Since this is not an OSGi bundle, the blueprint configuration is not an option. Instead, you have to create a KettleLifecyclePlugin which instantiates your analyzer class and registers it with PentahoSystem. The following examples illustrate registration to extract the lineage information from documents:
- Analyzer class example for the CSV File Input step: pentaho-metaverse/CsvFileInputStepAnalyzer.java at master · pentaho/pentaho-metaverse
- External resource consumer class example for the CSV File Input step: pentaho-metaverse/CsvFileInputExternalResourceConsumer.java at master · pentaho/pentaho-metaverse
The lifecycle listener is a new plug-in:
import org.pentaho.di.core.annotations.LifecyclePlugin;
import org.pentaho.di.core.lifecycle.LifeEventHandler;
import org.pentaho.di.core.lifecycle.LifecycleListener;
import org.pentaho.platform.engine.core.system.PentahoSystem;
@LifecyclePlugin( id = "CsvFileInputPlugin", name = "CsvFileInputPlugin" )
public class CsvFileInputLifecycleListener implements LifecycleListener {
CsvFileInputStepAnalyzer analyzer;
CsvFileInputExternalResourceConsumer consumer;
@Override public void onStart( LifeEventHandler lifeEventHandler ) {
// instantiate a new analyzer
analyzer = new CsvFileInputStepAnalyzer();
// construct the external resource consumer for the files that it reads from
consumer = new CsvFileInputExternalResourceConsumer();
analyzer.setExternalResourceConsumer( consumer );
// register the analyzer with PentahoSystem. this also adds it to the service reference list that contains ALL IStepAnalyzers registered
PentahoSystem.registerObject( analyzer );
// register the consumer with PentahoSystem. this also adds it to the service reference list that contains ALL IStepExternalResourceConsumers registered
PentahoSystem.registerObject( consumer );
}
@Override public void onExit( LifeEventHandler lifeEventHandler ) {
}
}