Pentaho Aggregation Designer

The Pentaho Aggregation Designer simplifies the creation and deployment of aggregate tables that improve the performance of your Pentaho Analyzer (Mondrian) OLAP cubes.
Pentaho Analyzer is a pure, relational OLAP engine that works solely with the data stored in your relational database rather than providing its own multidimensional data storage model. This simplifies deployment and data management, but places limitations on performance when working with very large data sets (fact tables with more than 10 million records and/or cubes with a high cardinality of levels and members). To improve performance in these scenarios, Pentaho Analyzer supports aggregate tables. Aggregate tables coexist with the base fact table and contain pre-aggregated measures built from the fact table. This improves performance by enabling the Mondrian engine to fulfill certain summary level queries from the smaller aggregate table versus aggregating a large number of individual facts from the base fact table.
Pentaho Aggregation Designer provides you with a simple interface that allows you to create aggregate tables from levels within the dimensions you specify. Based on these selections, the Aggregation Designer generates the Data Definition Language (DDL) for creating the aggregate tables, the Data Manipulation Language (DML) for populating them, and an updated Mondrian schema which references the new aggregate tables. If you are unfamiliar with aggregate table design concepts, the Aggregation Designer also includes an intelligent adviser that evaluates the structure and cardinality of your OLAP cube and recommends some initial aggregate tables to create for improving performance.
Get started with the Pentaho Aggregation Designer
The Pentaho Aggregation Designer workspace is shown below. 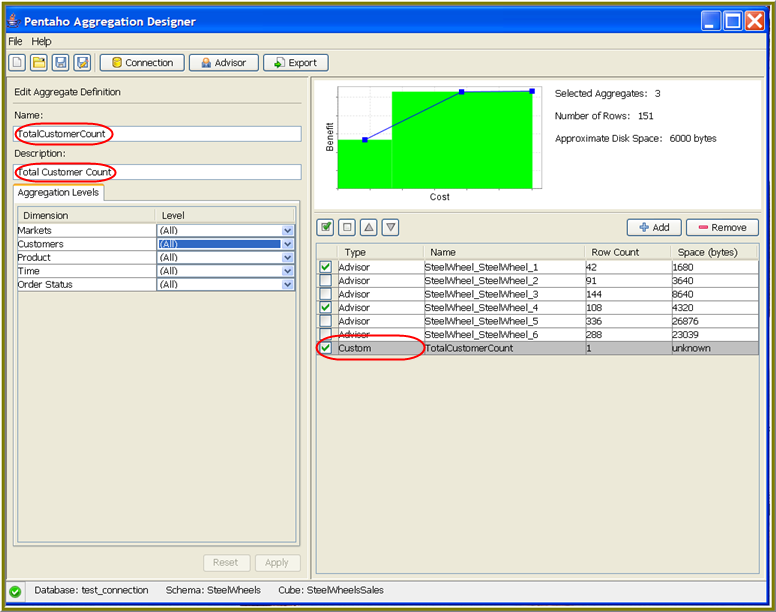
The Aggregation Designer contains the following sections:
-
Impact Summary
The impact summary in the lower right pane provides you with information on the estimated impact for creating all of the currently selected aggregates. This summary includes the number of aggregate tables that will be created, the estimated number of rows contained in those tables, and the estimated amount of space it will occupy on the hard drive. The impact summary is automatically updated as you select and deselect aggregates from the list of proposed aggregates.
-
Cost/Benefit Chart
The Cost/Benefit chart provides a high-level comparison of the benefit of all currently selected aggregates relative to their estimated cost. The benefit scale represents the relative number of queries that can be fulfilled by an aggregate table versus having to be retrieved from the base fact table. The cost scale is an indicator of the impact in terms of number of tables and disk space needed to create the selected aggregate recommendations.
-
File Menu
You can save all aggregate-related data (custom- or advisor-created) in your workspace at any time. Saving ensures that all of the data (your designs) in the workspace is retained; you are saving the state of your workspace as an XML file in a location you specify. To save, go to the File menu and click Save As. To open a saved file, go to the File menu and click Open, then navigate to the design you previously saved.
Define a data source
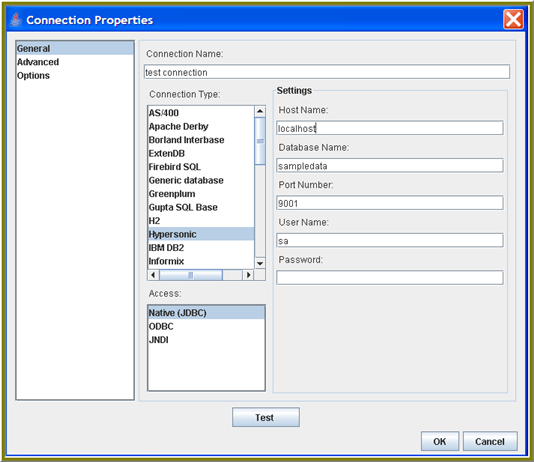
To define a data source connection, perform the following steps:
Procedure
-
In the Pentaho Aggregation Designer toolbar, click Connection to open the Connect to Data Source dialog box.
-
Click Configure.
The Connection Properties dialog box appears. -
In the Connection Name field, enter a name for your connection; this is a free-text field.
A connection name uniquely defines a connection. -
In the Connection Type list, select a database.
-
In the Access list, keep the default choice, which should be Native (JDBC).
-
In the Settings section, enter the following information:
-
Type the host name of the database server into the Host Name field.
-
In the Database Name field, type the name of the database you're connecting to.
-
In the Port Number field, enter the TCP port number.
-
(Optional) In the User Name and Password fields, type the user name and password used to connect to the database.
-
-
Click Test.
If the settings you typed in are correct, a success message appears. -
Click OK.
-
(Optional) If you must define additional parameters for your JDBC driver, or if you want to enter your server settings manually, follow these instructions:
-
Click Options in the left panel.
-
Enter the parameter name and value for the settings you need to specify.
For example, PORT (parameter name), 1025 (parameter value). -
Click Test when your settings are entered.
A success message appears if everything was typed in correctly. -
Click OK.
-
Select a model
To select a model:
Procedure
-
In the Connect to Data Source dialog box, under OLAP Model, select Mondrian Schema File.
-
Click the Ellipsis (...) to display a file dialog box.
-
Browse to locate and select your Mondrian schema file, which would be SteelWheels.mondrian.xml if using sample data, then click OK.
-
Click Apply.
The Cube list is populated with a list of cubes defined in your schema. -
Select the Mondrian cube you want to optimize, then click Connect.
Results
Use Aggregate Advisor
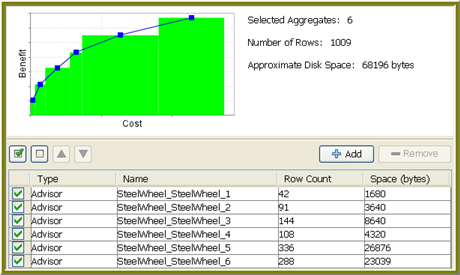
To display recommended aggregates, perform the following steps.
Procedure
-
In the Pentaho Aggregation Designer toolbar, click Advisor.
-
Specify your Advisor Input Parameters.
-
Max Aggregates
Allows you to specify the maximum number of aggregates you want the Advisor to recommend.
-
Max Time to Run
Allows you to specify the maximum amount of time (in seconds) you want the Advisor to run before making recommendations.
NoteAllowing the Advisor to run for longer periods of time allows for more potential recommendations to be evaluated and results in more accurate recommendations.
-
-
Click Recommend.
The Advisor runs for a few seconds before it displays an initial list of recommended aggregates. The Advisor is designed to keep running until it finds an optimal solution. If you stop the Advisor prematurely, the Advisor returns the best set of recommendations it has found up to the point when it was stopped.
Add aggregates
Procedure
-
In the right pane of the Pentaho Aggregation Designer, click Add.
-
In the left pane, enter a Name and Description for your new aggregate.
-
Under Level, click the down arrows to define the hierarchy and levels associated with the aggregate you are creating.
-
Click Apply. Your aggregate is added to the aggregate list.
Customize aggregates
Procedure
-
In the Pentaho Aggregation Designer, click on an aggregate in the proposed aggregate list to select it.
NoteWhen you modify an aggregate created using the Advisor, the aggregate becomes a Custom aggregate as indicated by the Type column in the proposed aggregate list. -
(Optional) In the left pane, you can modify the Name and Description for your custom aggregate.
-
In the Aggregation Levels tab, click the down arrows to make changes to the hierarchy and levels associated with the aggregate definition you are customizing.
-
Click Apply.
The Pentaho Aggregation Designer updates the proposed aggregate list, cost/benefit chart, and impact summary.
Delete aggregates
Procedure
-
Select the aggregate you want to delete from the proposed aggregate list.
-
Click Remove.
Export aggregates
To preview the DDL and DML outputs, perform the following steps:
Procedure
-
Select the aggregates that have DML/DDL output you want to preview.
-
In the Pentaho Aggregation Designer toolbar, click Export.
-
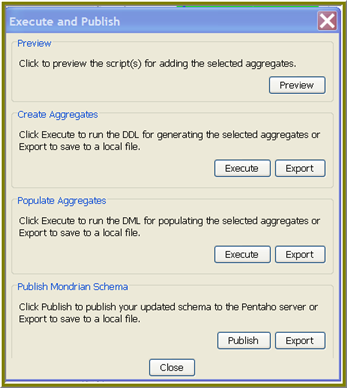
In the Execute and Publish dialog box, click Preview.
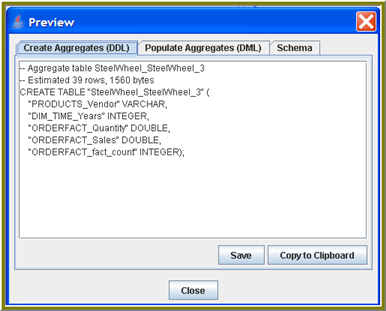
-
Click Copy to Clipboard or Save to retain the output.
-
If you examine the DDL/DML outputs and are satisfied with the results, you can allow the Pentaho Aggregation Designer to build (Execute/Publish) the aggregate tables. Follow the instructions for publishing and exporting included in the Execute and Publish dialog box.
Glossary of Terms
-
Aggregate
Definitions for aggregate tables that help optimize a cube; also, summarized data.
-
Aggregate Tables
Coexists with the base fact table, and contains pre-aggregated measures built from the fact table. It is registered in Mondrian's schema, so that Mondrian can choose whether to use the aggregate table rather than the fact table, if applicable for a particular query. For related information, see Introduction to Aggregate Table.
-
Aggregation
The process of merging multiple data values into one value. For example, sales data collected daily can then be aggregated to the week level, the week data could be aggregated to the month level, and so on. The data can then be referred to as aggregate data. Aggregation and summarization are synonyms, as are aggregate data and summary data.
-
Data Definition Language (DDL)
Originally a subset of SQL, this language defines data structures, including rows, columns, tables, indexes, and database specifics such as file locations. DDL SQL statements are more a part of the database management system, and have large differences between SQL implementations. For related information, see Data Definition Language.
-
Mondrian Schema
Defines a multi-dimensional database. A Mondrian schema contains a logical model, consisting of cubes, hierarchies, and members, and a mapping of this model onto a physical model. The logical model consists of the constructs used to write queries in the MDX language: cubes, dimensions, hierarchies, levels, and members. The physical model is the source of the data presented through the logical model. It is typically a star schema, which is a set of tables in a relational databases. For related information, see How to Design a Mondrian Schema.
-
Relational Online Analytic Processing (ROLAP)
An alternative to MOLAP (Multidimensional OLAP) technology. While both ROLAP and MOLAP analytic tools are designed to allow analysis of data through the use of a multidimensional data model, ROLAP differs significantly in that it does not require the pre-computation and storage of information. Instead, ROLAP tools access the data in a relational database and generate SQL queries to calculate information at the appropriate level when an end user requests it. With ROLAP, it is possible to create additional database tables (summary tables or aggregations) which summarize the data at any desired combination of dimensions. For related information, see ROLAP Overview.
-
Snowflake Schema
A way of arranging tables in a relational database such that the entity relationship diagram resembles a snowflake in shape. At the center of the schema are fact tables which are connected to multiple dimension tables. Thus a snowflake simplifies to a star schema when relatively few dimensions are used. The star and snowflake schemas are most commonly found in data warehouses where the speed of data retrieval is more important than the speed of insertion. As such, these schemas are not normalized much, and are frequently left in third normal form or second normal form. For related information, see Snowflake Schema.