XML Input Stream (StAX)

The XML Input Stream (StAX) step reads data from XML files using the Streaming API for the XML (StAX) parser. This step is optimal for quickly processing large and complex data structures. Unlike the Get Data from XML step which uses in-memory processing and can require the purging of parts of files, the XML Input Stream (StAX) step moves the processing logic into the transformation. The step itself provides the raw XML data stream together with additional processing information.
This streaming step is recommended when you have limitations with other steps or need to parse XML when:
- You need fast data loads which are independent of the memory regardless of the file size
- You need flexibility in reading various parts of the XML file in different ways, and do not want to repeatedly parse the file.
Because the processing logic of some XML files can be complex, you should have a good knowledge of the existing Kettle steps when using this step.
Samples
Sample transformations demonstrating the capabilities of this step are available in the
distribution package in the
design-tools/data-integration/samples/transformations folder.
- XML Input Stream (StAX) Test 1 - Basic Tests.ktr
- XML Input Stream (StAX) Test 2 - Element Blocks.ktr
- XML Input Stream (StAX) Test 3 - Attribute Groups.ktr
- XML Input Stream (StAX) Test 4 - Hierarchies.ktr
- XML Input Stream (StAX) Test 5 - Performance Test Data for Element Blocks.ktr
- XML Input Stream (StAX) Test 6 - Namespaces.ktr
Options
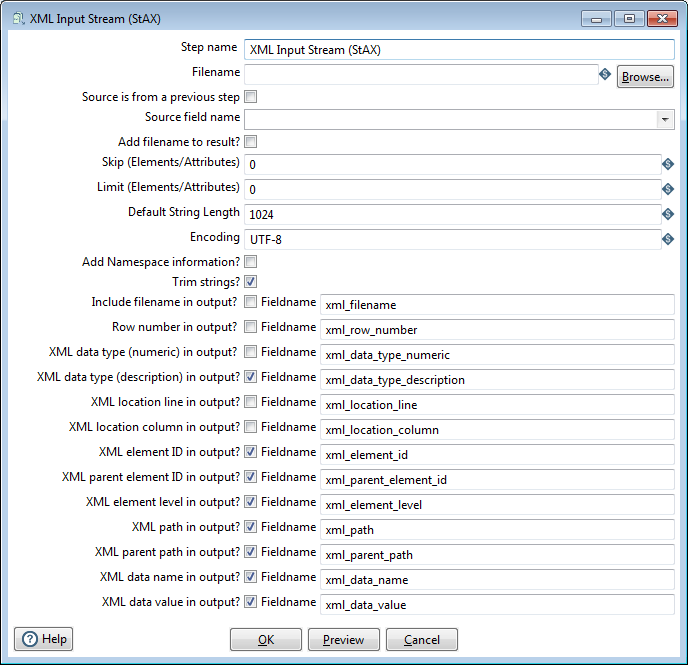
| Option | Description | Default Value/Data Type |
| Step name | Specifies the unique name of the XML Input Stream (StAX) step on the canvas. A transformation step can be placed on the canvas several times; however, it represents the same transformation step. You can customize the name or leave it as the default. | |
| Filename | File name of the input XML file. Specify your file name by entering its path or clicking Browse. If you connect to a step that precedes the XML Input Stream step, the Browse button is hidden, and the text box becomes a drop-down menu that is populated with the fields from the preceding step. Select a value from the drop-down menu to use as the path to an XML file. You can use internal variables to specify the path. | |
| Source is from a previous step | Accept data from a field in a previous step. | |
| Source field name | Selects a field from the previous step to use as XML data. | |
| Add filename to result? | Adds the processed XML filename to the result of this transformation by passing the filename of the XML input file as a value on each result row. You can then use it in subsequent steps where you want to use the filename as a value. | No |
| Skip (Elements/Attributes) | Number of elements or attributes that should be skipped. Use this field for starting the processing at a specific location in a file. The file will still be loaded by the parser, but the rows will not be produced. | 0 |
| Limit (Elements/Attributes) | Limits the number of elements or attributes to process. With the Skip and Limit properties, you can enable chunk loading that is defined in an outer loop. | 0 |
| Default String Length | The default string length for the XML data name and value fields. | 1024 |
| Encoding | Encodes the XML file data in the specified encoding. | UTF-8 |
| Add Namespace information? | Adds the XML data type NAMESPACE to the stream. You can add an
optional prefix (defined in the XML data name) and URI information (defined in the
XML data value). This option adds a defined prefix in the ELEMENT data type to the
XML data name, for example, prefix:product. Due to the extra
namespace handling, this option slows down the processing throughput. | No |
| Trim strings? | Trims all name/value elements and attributes. It eliminates white spaces, tabs, carriage returns, and line feed characters at the beginning and end of the string. | Yes |
| Include filename in output? / Fieldname | Adds the processed file name to the specified field name. | xml_filename (String 256) |
| Row number in output? / Fieldname | Adds the processed row number (starting with 1) to the specified field name. | xml_row_number (Integer) |
| XML data type (numeric) in output? / Fieldname |
Adds the processed data type in numeric format to the specified field name. The following data types are defined: 0 - "UNKNOWN" (Reserved) 1 - "START_ELEMENT" 2 - "END_ELEMENT" 3 - "PROCESSING_INSTRUCTION" (Reserved) 4 - "CHARACTERS" 5 - "COMMENT" (Reserved) 6 - "SPACE" (Reserved) 7 - "START_DOCUMENT" 8 - "END_DOCUMENT" 9 - "ENTITY_REFERENCE" (Reserved) 10-"ATTRIBUTE" 11-"DTD" (Reserved) 12-"CDATA" (Reserved) 13-"NAMESPACE" (When namespace information is selected) 14-"NOTATION_DECLARATION" (Reserved) 15-"ENTITY_DECLARATION" (Reserved). | xml_data_type_numeric (Integer) |
| XML data type (description) in output? / Fieldname |
Adds the processed data type in text format to the specified field name. This option should be used instead of the numeric data type for better readability of the transformation. See the XML data type (numeric) description above for a list of values. Because this option can cause slower processing of strings and extra memory consumption, it is recommended to use the numeric data type format for big data loads. | xml_data_type_description (String 25) |
| XML location line in output? / Fieldname | Adds the processed source XML location line to the specified field name. | xml_location_line (Integer) |
| XML location column in output? / Fieldname | Adds the processed source XML location column to the specified field name. | xml_location_column (Integer) |
| XML element ID in output? / Fieldname | Adds the processed element number (starting with '0') to the specified field name. In contrast to adding the Row number, this field number is incremented by the count of each new element and not the row number. This numbering ensures that the nesting between levels is correct. | xml_element_id (Integer) |
| XML parent element ID in output? / Fieldname |
Adds the parent element number to the specified field name. When you use the XML element ID with the XML parent element ID, a complete XML element tree is available for later usage. | xml_parent_element_id (Integer) |
| XML element level in output? / Fieldname | Adds the processed element level to the specified field name, starting with '0'
for the root START_ and END_DOCUMENT. | xml_element_level (Integer) |
| XML path in output? / Fieldname | Adds the processed XML path to the specified field name. | xml_path (String 1024) |
| XML parent path in output? / Fieldname | Adds the processed XML parent path to the specified field name. | xml_parent_path (String 1024) |
| XML data name in output? / Fieldname | Adds the processed data name of elements, attributes, and optional namespace prefixes to the specified field name. | xml_data_name (String 1024 or Default String Length) |
| XML data value in output? / Fieldname | Adds the processed data value of elements, attributes and optional namespace URIs to the specified field name. | xml_data_value (String 1024 or Default String Length) |
If a Set/Reset functionality is needed, you can use the Modified Java Script Value scripting step or the User Defined Java Class step to create one. The User Defined Java Class step is recommended because it is faster.
Element blocks example
This example parses the XML Input Stream (StAX) Test 2 - Element Blocks.xml file which has two main sample data blocks: Analyzer Lists and Products. The data blocks are separated by splitting the parent XML path to levels using Switch / Case steps. This separation could also be performed by the string contains option of the Switch / Case step or by using other steps. In more complex processing, you should use mappings (sub-transformations) for the different data blocks so they are clearly represented.
Here is the XML sample with different element blocks:
<?xml version="1.0" encoding="UTF-8"?>
<ProductInformation ExportTime="2010-11-23 23:56:40"
ExportContext="german" ContextID="german" WorkspaceID="Test" id="1"
parent="0">
<AnalyzerResult>
<AnalyzerLists>
<AnalyzerList name="items.added">
<AnalyzerElement ItemID="product?id=123456"
ProductID="123456" />
<AnalyzerElement ItemID="product?id=789"
ProductID="789" />
</AnalyzerList>
<AnalyzerList name="items.deleted">
<AnalyzerElement ItemID="product?id=111111"
ProductID="111111" />
<AnalyzerElement ItemID="product?id=222222"
ProductID="222222" />
</AnalyzerList>
<AnalyzerList name="items.dummy_test">
<AnalyzerElement ItemID="product?id=test1"
ProductID="test1" />
<AnalyzerElement ItemID="product?id=test2"
ProductID="test2" />
</AnalyzerList>
</AnalyzerLists>
<AnalyzerDummyTest>
<AnalyzerDummyTest name="Dummy not processed" />
</AnalyzerDummyTest>
</AnalyzerResult>
<Products>
<Product id="123456" name="Product A">
<MetaData>
<Value AttributeID="AttrA">false</Value>
<Value AttributeID="AttrB">true</Value>
<Value AttributeID="AttrShortName">
Product A Short Name
</Value>
<Value AttributeID="AttrLongName">
Product A Long Name
</Value>
</MetaData>
</Product>
<Product id="789" name="Product B">
<MetaData>
<Value AttributeID="AttrA">true</Value>
<Value AttributeID="AttrB">false</Value>
<Value AttributeID="AttrShortName">
Product B Short Name
</Value>
<Value AttributeID="AttrLongName">
Product B Long Name
</Value>
</MetaData>
</Product>
</Products>
</ProductInformation>
A preview of the step looks like the image below, depending on the selected fields: 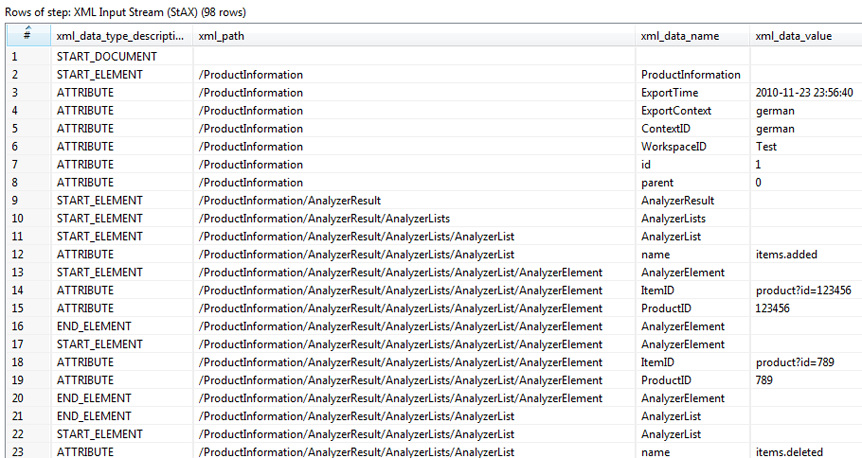
Note that you can see the original streaming information, elements, and attributes from the XML file, and other helpful fields like the element level.
The transformation looks like the image below: 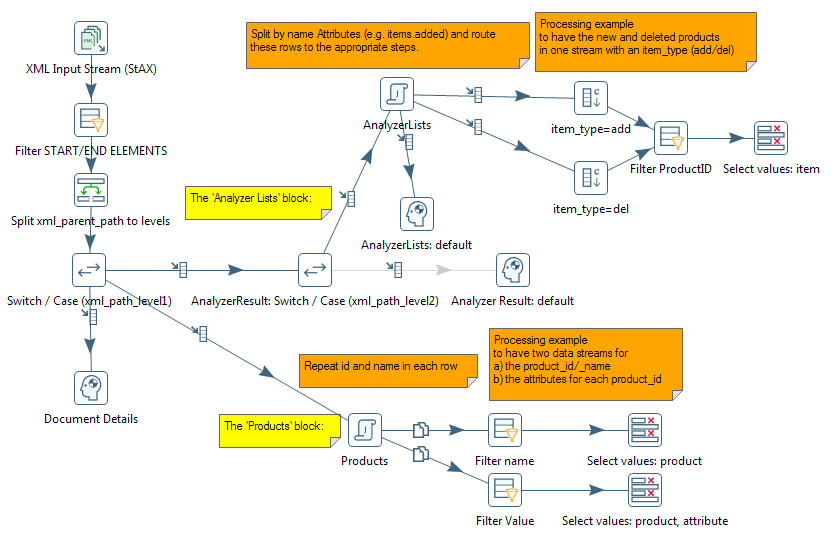
The result for the Analyzer List block looks like this: 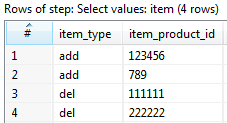
The result for the Products block (split into two separate data
streams for the end system) looks like the image below: