Table Input

The Table Input step reads information from a connected database using SQL statements. Basic SQL statements can be generated automatically by clicking the Get SQL select statement button.
AEL considerations
When using the Table Input step with Adaptive Execution Layer, consider the following factors for Hive and Impala database connections, which can affect performance and results.
- The following options in the step are not supported:
- Enable Lazy conversion.
- Execute for each row.
- Pooling and Clustering database connection options.
- Structures, arrays, and user-defined data types are not supported.
Connect to a Hive database
When using the Table input and Table output steps, you can connect to Hive in one of two ways to achieve the best processing rate for small and large tables within the same cluster:
- Use AEL to access small unmanaged Hive tables on a secure HDP cluster or an Amazon EMR cluster. For details, see Configure the AEL daemon for a Hive service.
- Use AEL with the Hive Warehouse Connector (HWC) to access managed tables or large unmanaged tables in Hive on a secure HDP cluster. For details, see Configuring the AEL daemon for the Hive Warehouse Connector on your Hortonworks cluster.
Connect to an Impala database
Perform the following steps to download and install the Cloudera Impala driver:
Procedure
Go to https://www.cloudera.com/, select Downloads and click Impala JDBC Driver Downloads.
Select Impala JDBC Connector 2.5.42 from the menu and follow the site's instructions for downloading.
A ZIP file containing the Impala_jdbc_2.5.42 driver is downloaded.Unzip the
The contents of the ZIP file are extracted to the folder. The unpacked contents include a documentation folder and two ZIP files. You only need theimpala_jdbc_2.5.42.zipfile to a local folder.ImpalaJDBC41-2.5.42.zip.Open the
The associated JAR files are extracted from the ZIP file.ClouderaImpalaJDBC-2.5.42folder and unzip theClouderaImpalaJDBC41_2.5.42.zipfile to a local folder.Copy all the JAR files, except
log4j-1.2.14.jar, to the pentaho/design-tools/data-integration/adaptive-execution/extra folder.CautionThelog4j-1.2.14.jarfile should not be copied as it is already present and will cause conflicts.Save and close the file.
The Cloudera Impala driver is installed.
Results
General
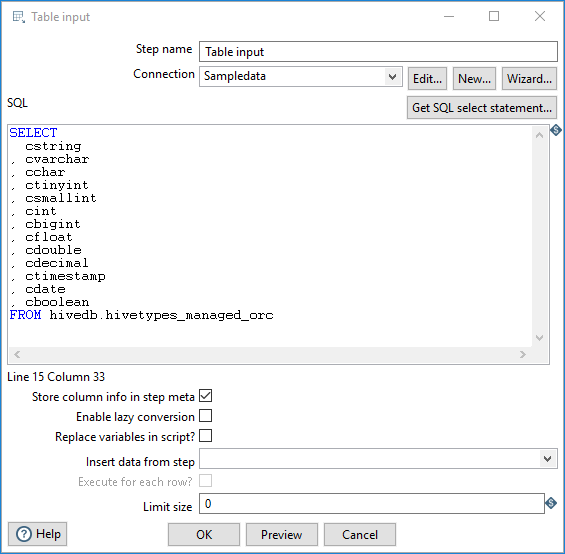
The following fields are general to this transformation step:
| Field | Description |
| Step name | Specify the unique name of the Table Input step on the canvas. You can customize the name or leave it as the default. |
| Connection | Use the list to select the name of an existing database
connection. Select the connection according to the database you are accessing.
If you do not have an existing connection, click New or Wizard. If you need to modify an existing connection, click Edit. See Define Data Connections for instructions. |
Options
The Table Input step has the following options:
| Option | Description |
| SQL | Specify a SQL statement to read information from the connected database. You can also click the Get SQL select statement button to browse tables and automatically generate a basic select statement. |
| Store column info in step meta | Select this option to use the cached metadata stored in the KTR
without making a database connection to query the table. NoteIf you are using
Spark as your processing engine, select this option. (Required) |
| Enable lazy conversion | Select this option to enable the lazy conversion algorithm. When selected, lazy conversion avoids unnecessary data type conversions when possible, which can significantly improve performance. |
| Replace variables in script? | Select this option to replace variables in the script. This feature provides testing capabilities with or without variable substitutions. |
| Insert data from step | Specify the input step name where PDI can expect information to come from. This information can then be inserted into the SQL statement. The locator where PDI inserts information is indicated with a question mark: ?. |
| Execute for each row? | Select this option to execute the query for each individual row. |
| Limit size | Specify the number of lines to read from the database. A value of zero (0) indicates to read all lines. |
| Preview (button) | Click Preview to open a new window and view an execution log derived from a temporary transformation with two steps: the Table Input step and the Dummy step. To see the log, click Logs in the Preview window that opens. |
Example
Below is an SQL statement:
SELECT * FROM customers WHERE changed_date BETWEEN ? AND ?
This SQL statement requests two calendar dates, to create a range, that are read from the Insert data from step option. The target date range can be provided using the Get System Info step. For example, if you want to read all customers that have had their data changed yesterday, you can get a target range for yesterday and read the customer data.
Metadata injection support
You can use the Metadata Injection supported fields with the ETL Metadata Injection step to pass metadata to your transformation at runtime. The following fields of the Table Input step support metadata injection:
- SQL
- Limit size
- Execute for each row
- Replace variables in script
- Enable lazy conversion
- Cached row meta
- Connection