Copybook Input

The Copybook Input step reads binary data files that are mapped by a fixed-length COBOL copybook definition file. COBOL definition and binary files are used in IT scenarios that include data stored on mainframes. You can extract the binary data files and the definition files from the mainframe for data transformation and analysis, and avoid using mainframe cycles for complex data analysis tasks.
Before you begin
- For PDI to process binary data files, you must first download both the copybook definition file and the binary data files from the mainframe environment. For example, you can use FTP or an SFTP server to download the files to a staging area accessible from PDI. You can also use a SFTP VFS path to connect to and read data directly from the mainframe at runtime.
- The binary data file must remain in binary format when used as input to this step. If you are using FTP to download the files, ensure that the data file is not converted to ASCII.
- This step works with Fixed Length COBOL records only. Variable record types
such as
VB,VBS,OCCURS DEPENDING ONare not supported. - Your mainframe administrator can provide more details about the environment-specific copybook file definitions and structures this step requires for reading binary data.
General
- Step name: Specifies the unique name of the Copybook Input step on the canvas. You can customize the name or leave it as the default.
Options
Input tab
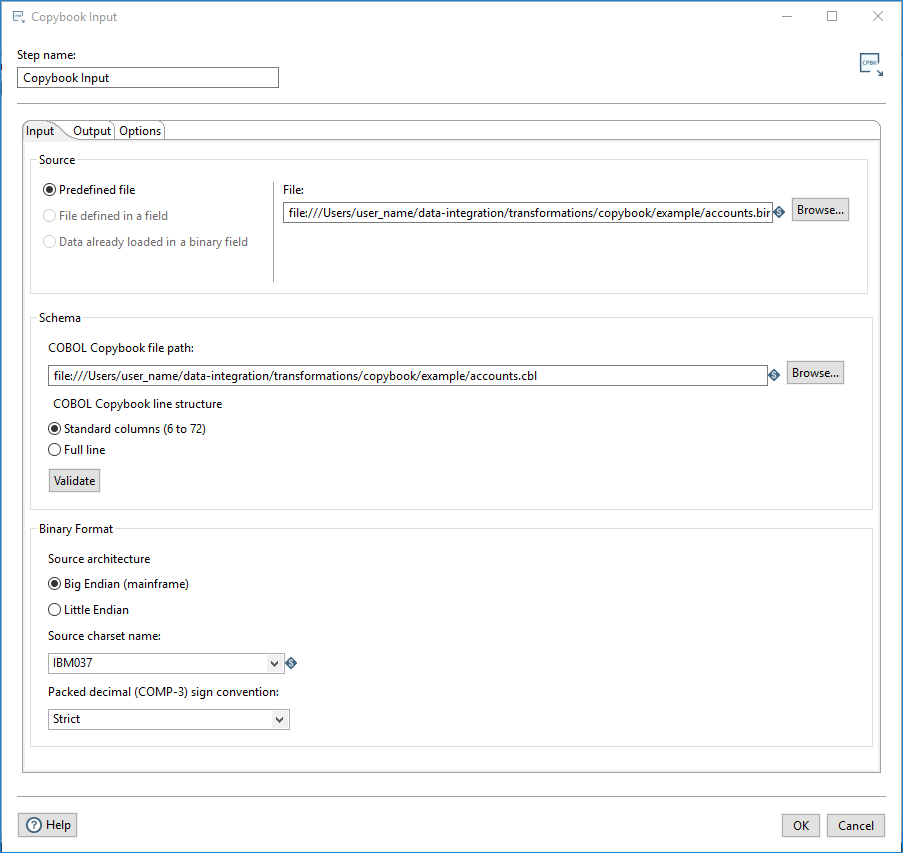
The Input tab has the following sections.
These options specify the location of the binary data
.| Option | Description |
| Predefined file | Select this option to specify a path to a binary data file that contains the data you want to read into the PDI stream. You can type any VFS path directly into the File field, including any variables, or you can click the Browse button to locate the binary data file. |
| File defined in a field | Select this option to read the names of the binary files from a field name in the previous step. Select the name of the field from the drop-down list. |
| Data already loaded in a binary field | Select this option if the binary data is passed into the step from a binary field on the PDI stream. Select the step generating the binary field from the drop-down list. You can use this option to prepare the output of records by another Copybook Input step. Using this method, you can selectively process fields and avoid conversion errors in definition files that include REDEFINES. See the Store record as a binary field option in the Options tab. |
These options define the location of the copybook definition file and include mapping options for the binary data files.
| Option | Description |
| COBOL Copybook file path | Specify the file path to the copybook definition file. You can enter any VFS or SFTP file path or click Browse to open the system file browser. After selecting a file, click Validate to verify that the definition file can be accessed and parsed. |
| COBOL Copybook line structure | Specify the line structure of the definition file.
|
Use these options to describe the binary format of the selected file.
| Option | Description |
| Source architecture | Select the machine architecture of the binary data source files.
The values are:
|
| Source charset name | Select the character encoding set of the binary data file. Mainframe EBCDIC is typically encoded using IBM037 or cp1047 character sets. For more information about character sets and their aliases, see Supported Encodings in the Oracle® documentation. |
| Packed decimal (COMP-3) sign convention | Select how COMP-3 Packed decimals are parsed from the binary data
as it relates to sign convention. For a given field, if validation occurs and fails,
a conversion error will occur at runtime. See Use Error Handling for details.
|
Output tab
The table in the Output tab provides details of the
fields that are read from the binary data and how those fields are placed in the PDI stream as output from the
step. 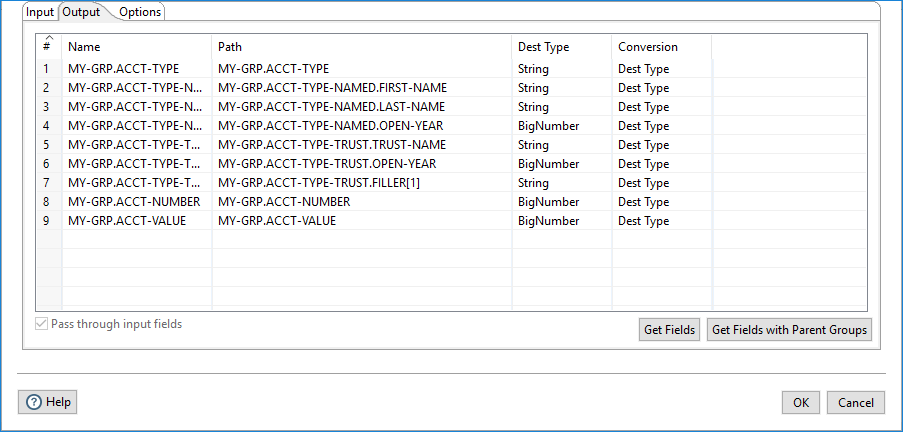
You can populate the table using either the Get Fields or Get Fields with Parent Groups commands. These commands extract directly from the copybook definition file selected in the Input tab. Use the Get Fields with Parent Groups command if you want to include the higher-level organizational data from the copybook definition file that omits the PICTURE clauses.
To pass the input fields to the PDI output stream, select the Pass through input fields check box. Clear this check box to omit the input fields from the PDI output stream.
The output table contains the following columns.
| Column | Description |
| Name | The name of the field in the PDI output stream. You can revise or update this field name as necessary. |
| Path | The fully qualified path to the binary data column in the copybook
definition file. NoteThis field
cannot be edited. It is controlled by the copybook definition file. |
| Dest Type | The PDI data type of the column mapped from the column definition. NoteThis field cannot be edited. It is
controlled by the copybook definition file.
|
| Conversion | This data type is read from the source data for a given field.
|
Options tab
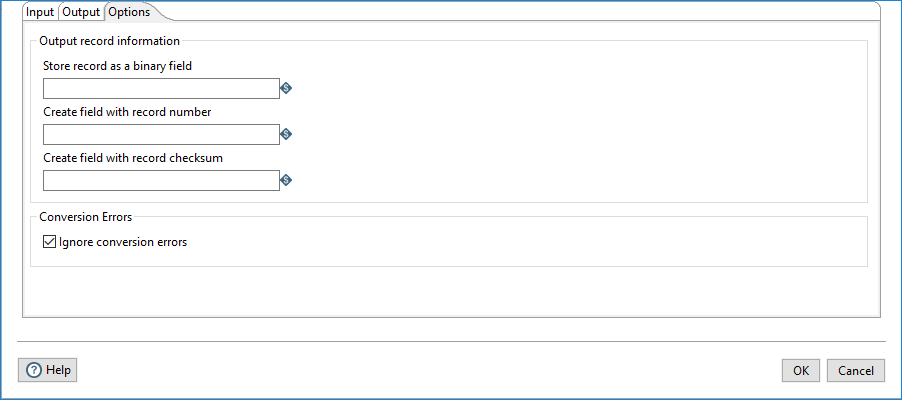
Use this tab to define PDI output stream options.
Use this section to specify details about the records for output.
| Option | Description |
| Store record as a binary field | Specify an additional output field to contain the binary bytes that make up the record currently being processed. You can use the stored binary field as the input for the data fields downstream from the Copybook Input step. |
| Create field with record number | Specify an additional output field to contain the record number within the file. For fixed-length record definitions, multiplying this number by the fixed record size yields the offset of the record within the input file. This field will reset to zero when a new data file is read. Also, the counter is specific to a copy of the step, so changes to the Change Number of Copies to Start option may cause unexpected results. |
| Create field with record checksum | Specify an additional output field to contain a hex string
representation of the sha1 checksum of the source record byte
data.NoteThis option
is useful for debugging conversion errors, but it could be resource
intensive. |
Use this section to specify how to handle errors during conversion.
Ignore conversion errors
Select this check box to log multiple conversion error messages such as malformed records, bad enclosure strings, wrong number of fields, and premature line ends. The errors are logged in JSON object format in a single PDI row. See Use Error Handling for details about the format.
Clear this check box if you want conversion errors in the source binary files to stop the transformation.
Use Error Handling
The JSON object is placed in the error description field within the error row. Error handling must be enabled on the step to capture the error columns and descriptions. On the canvas, right-click the Copybook Input step and select Error Handling to open the Step error handling settings window and configure the error output column names. See the Use the Transformation menu for details.
The following table details the JSON object format for the output error stream.
| Key | Type | Example | Description |
| record | Integer | 0 | The record number originating from the Copybook Input step. |
| converter | String | BigNumberColumnConverter | The converter class that originated the error. |
| exception | String | RecordException | The exception class of the error. |
| message | String | Invalid sign in field: OPEN-YEAR | The error message text, if it exists. |
| fieldName | String | OPEN-YEAR | The name of field that has the error. |
| position | Integer | 22 | The position of the field. |
| length | Integer | 3 | The length of the field. |
| value | String | 404040 | The value read as a hexadecimal string. |
| recordHash | String | 240c992c3aaebccf6dc0e99a4ed1a447e4811bed | The record checksum originating from the Copybook Input step. |
Metadata injection support
All fields of this step support metadata injection. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.
Use the Read metadata from Copybook step to read copybook definition files and obtain the required mapping information to inject fields. In addition to the Name, Path, Dest Type, and Conversion, a decimal precision must be provided.