Using the ORC Output step on the Spark engine

You can set up the ORC Output step to run on the Spark engine. Spark processes null values differently than the Pentaho engine, so you may need to adjust your transformation to process null values following Spark's processing rules.
Because of Cloudera Distribution Spark (CDS) limitations, the step does not support the Adaptive Execution Layer for writing Hive tables containing data files in the ORC format from Spark applications in YARN mode. As an alternative, you can use the Parquet data format for columnar data using Impala.
General
Enter the following information in the transformation step fields:
| Option | Description |
| Step name | Specify the unique name of the ORC Output step on the canvas. You can customize the name or leave it as the default. |
| Folder/File name | Specify the location and name of the file or folder. Click Browse to display the Open File window and navigate to the destination file or folder. For the supported file system types, see Connecting to Virtual File Systems. A folder is created that may contain multiple ORC files. Partial files will be written to this directory. |
| Overwrite existing output file | Select to overwrite an existing file that has the same file name and extension. |
Options
The ORC Output step features two tabs with fields. Each tab is described below.
Fields tab
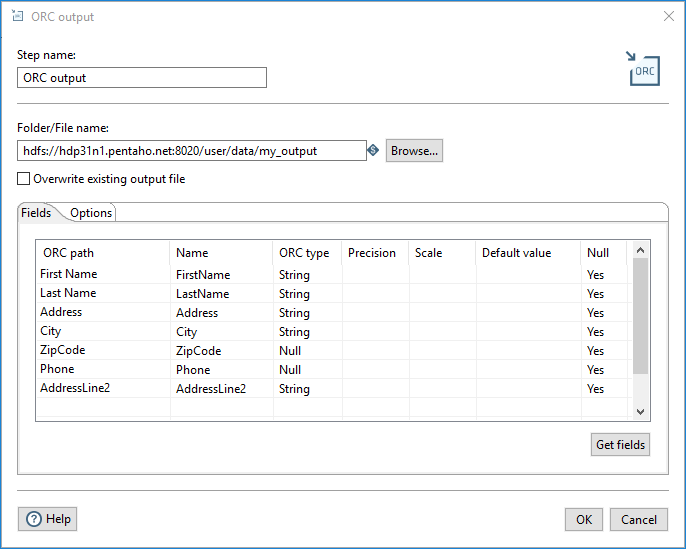
In the Fields tab, you can define fields that make up the ORC type description created by this step. The table below describes each of the options for configuring the ORC type description.
| Field | Description |
| ORC path | Specify the name of the field as it will appear in the ORC data file or files. |
| Name | Specify the name of the PDI field. |
| ORC type | Defines the data type of the field. |
| Precision | Specify the total number of digits in the number (only applies to the Decimal ORC type). The default value is 20. |
| Scale | Specify the number of digits after the decimal point (only applies to the Decimal ORC type). The default value is 10. |
| Default value | Specify the default value of the field if it is null or empty. |
| Null | Specifies if the field can contain null values. |
To avoid a transformation failure, make sure the Default value field contains values for all fields where Null is set to No.
You can define the fields manually, or you can provide a path to the PDI data stream and click Get Fields to populate all the fields. During the retrieval of the fields, a PDI type is converted into an appropriate ORC type, as shown in the table below. You can also change the selected ORC type by using the Type drop-down or by entering the type manually.
AEL types
In AEL, the ORC Output step automatically converts an incoming Spark SQL row to a row in the ORC output file, where the Spark types determine the ORC types that are written to the ORC file.
| ORC Type Desired | Spark Type Used |
| Boolean | Boolean |
| TinyInt | Not supported |
| SmallInt | Short |
| Integer | Integer |
| BigInt | Long |
| Binary | Binary |
| Float | Float |
| Double | Double |
| Decimal | BigNumber |
| Char | Not supported |
| VarChar | Not supported |
| TimeStamp | TimeStamp |
| Date | Date |
Options tab
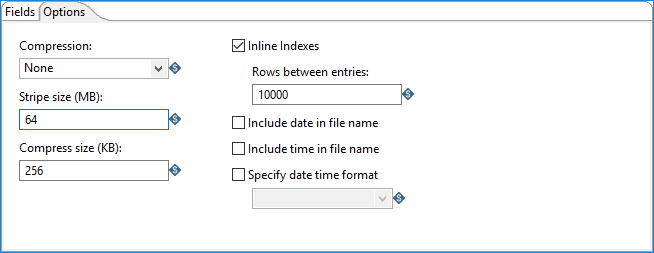
The following options in the Options tab define how the ORC output file will be created.
| Field | Description |
| Compression |
Specifies which codec is used to compress the ORC output file:
|
| Stripe size (MB) | Defines the stripe size in megabytes. An ORC file has one or more stripes. Each stripe is composed of rows of data, an index of the data, and a footer containing metadata about the stripe’s contents. Large stripe sizes enable efficient reads from HDFS. The default is 64.See https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC for additional information. |
| Compress size (KB) | Defines the number of kilobytes in each compression chunk. The default is 256. |
| Inline Indexes | If checked, rows are indexed when written for faster filtering and random access on read. |
| Rows between entries | Defines the stride size or number of rows between index entries (must be greater than or equal to 1000). The stride size is the block of data that can be skipped by the ORC reader during a read operation based on the indexes. The default is 10000. |
| Include date in file name | Adds the system date to the filename with format |
| Include time in file name | Adds the system time to the filename with format
HHmmss (235959 for example). |
| Specify date time format | Select to specify the date time format using the dropdown list. |
Metadata injection support
All fields of this step support metadata injection. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.