Using Parquet Input on the Spark engine

You can set up the Parquet Input step to run on the Spark engine. Spark processes null values differently than the Pentaho engine, so you may need to adjust your transformation to process null values following Spark's processing rules.
General
The following fields are general to this transformation step:
| Field | Description |
| Step name | Specify the unique name of the Parquet input step on the canvas. You can customize the name or use the provided default. |
| Folder/File name | Specify the fully qualified URL of the source file or folder name for the input fields. Click Browse to display the Open File window and navigate to the file or folder. For the supported file system types, see Connecting to Virtual File Systems. The Spark engine reads all the Parquet files in a specified folder as inputs. |
| Ignore empty folder | Select to allow the transformation to proceed when the specified source file is not found in the designated location. If not selected, the specified source file is required in the location for the transformation to proceed. |
Fields
The Fields section contains the following items:
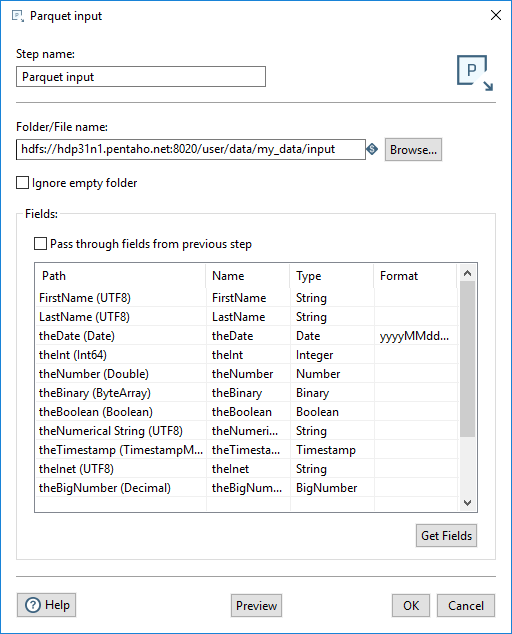
- The Pass through fields from the previous step option reads the fields from the input file without redefining any of the fields.
- The table defines the data about the columns to read from the Parquet file.
The table in the Fields section defines the fields to read as input from the Parquet file, the associated PDI field name, and the data type of the field.
Enter the information for the Parquet input step fields, as shown in the following table:
| Field | Description |
| Path | Specify the name of the field as it will appear in the Parquet data file or files, and the Parquet data type. |
| Name | Specify the name of the input field. |
| Type | Specify the type of the input field. |
| Format | Specify the date format when the Type specified is Date. |
Provide a path to a Parquet data file and click Get Fields. When the fields are retrieved, the Parquet type is converted to an appropriate PDI type, as shown in the table below. You can preview the data in the Parquet file by clicking Preview. You can change the Type by using the Type drop-down or by entering the type manually.
Using Get Fields with Parquet partitioned datasets
This section explains how to use Get Fields and partitioned Parquet files in a Parquet Input step running under AEL-Spark.
When partitioning by column is used with Parquet in a Hadoop cluster, the data is stored in the file system in a structure where additional sub-directories hold the Parquet files with data. The field used as the partitioning column, along with its corresponding values, is used as the sub-directory name and is not actually stored within the Parquet file.
For example, if you had a Parquet dataset named /tmp/sales_parquet that is partitioned by a field called year, the directory structure looks like this:
/tmp/sales.parquet/year=2019
/tmp/sales.parquet/year=2020
The Parquet files with the year data are stored inside these "year=" sub-directories. Since the directory name already contains the year field and its value, this data is not stored within each Parquet file. Because Get Fields reads an actual Parquet file and not a Parquet Hadoop directory structure using this partitioning convention, Get Fields cannot parse the data, in this case, a year value, that is contained in the partitioned sub-directories.
If you are using Parque with partitioned datasets, use one of the following methods to add fields to the table instead of Get Fields.
- Manually edit the XML in the .ktr file using any text editor and add the partitioned fields.
- Use Get Fields to read a different, temporary
Parquet file with the same schema and fields, but without the partitioning. After the
fields are added to the table using this temporary file, change the file path to the
target dataset. You can generate this non-partitioned Parquet file by using the Spark
Shell with the code snippet
spark.read.parquet("/tmp/dataset.parquet").limit(1).coalesce(1).write.parquet("/tmp/dataset_unpartitioned.parquet")where/tmp/dataset.parquetis your partitioned dataset.
Spark types
When used with the Spark engine, the Parquet Input step automatically converts Parquet rows to Spark SQL rows. The following table lists the conversion types:
| Parquet Type | Spark Type Output |
| Boolean | Boolean |
| Int8 | Short |
| Int16 | Short |
| Int32 | Integer |
| Int64 | Long |
| Int96 | Timestamp |
| UInt8 | Short |
| UInt16 | Short |
| UInt32 | Integer |
| UInt64 | Long |
| Binary | Binary |
| FixedLengthByteArray | Binary |
| Float | Float |
| Double | Double |
| Decimal | BigNumber |
| UTF8 | String |
| VarChar | String |
| TimeMillis | Timestamp |
| TimestampMillis | Timestamp |
| Date | Date |
Metadata injection support
All fields of this step support metadata injection. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.