HBase row decoder

The HBase row decoder step decodes an incoming key and HBase result object using a specified mapping. You can use this step with Pentaho MapReduce to process data read from HBase. See Using HBase Row Decoder with Pentaho MapReduce for a detailed look at that use case. For more information about how PDI works with Hadoop clusters, see Pentaho MapReduce workflow.
General
Enter the following information in the transformation step field:
Step name
Specifies the unique name of the HBase row decoder step on the canvas. You can customize the name or leave it as the default
Options
The HBase row decoder step features Configure fields and Create/Edit mapping tabs. Each tab is described below.
Configure fields tab
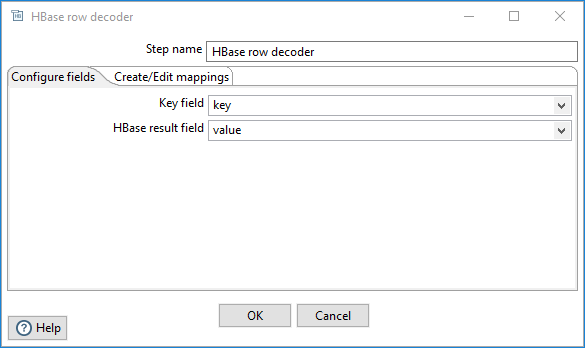
This tab includes the following input fields to the step:
| Field | Description |
| Key field | Select the incoming PDI field containing the input key. |
| HBase result field | Select the incoming PDI field containing the serialized HBase result. |
Create/Edit mappings tab
Most HBase data is stored as raw bytes. PDI uses mapping to decode values and execute meaningful comparisons for column-based result set filtering. Use the Create/Edit mapping tab to define metadata about the values that are stored in an HBase table.
Perform the following tasks before writing a value to HBase:
- Configure a connection by using the Hadoop cluster properties.
- Define which column family the value belongs to and its type.
- Specify type information about the key of the table.
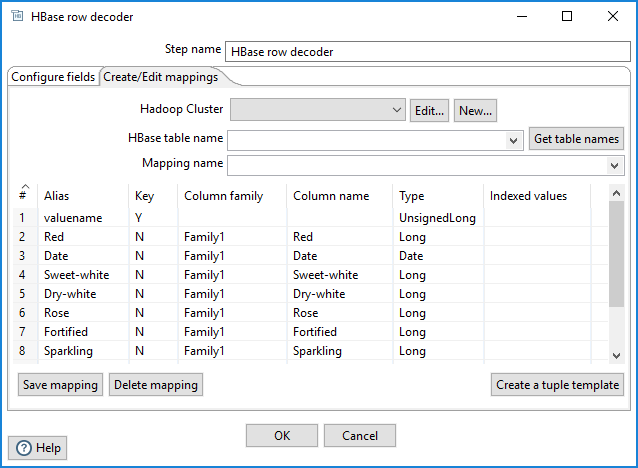
This tab includes the following options:
| Option | Description |
| Hadoop Cluster |
Select an existing Hadoop cluster configuration from the drop-down box. If you do not have an existing connection, click New. If you need to modify an existing connection, click Edit. See Connect to a Hadoop cluster with the PDI client for instructions. |
| HBase table name | Select the source HBase table name that has a defined mapping from the drop-down list of displayed names. Connection information must be valid and complete for this list to populate. Select a table to populate the Mapping name drop-down box with the names of available mappings for that table. Click Get table names to retrieve a list of existing table names. |
| Mapping name | Select the name of an existing map for the source table. The drop-down list is empty when no mappings are defined for the selected table. You can define multiple mappings on the same HBase table using different subsets of columns. |
Key fields table
Enter information about the columns in the HBase table that you want to map. The names of the incoming fields must match the aliases of fields defined in the mapping. There can be fewer incoming fields than defined in the mapping. However, if there are more incoming fields than defined, then an error will occur. One of the incoming fields must match the key defined in the mapping.
A valid mapping must define metadata for the key of the source HBase table. Because no name is given to the key of an HBase table, you must specify an Alias.
An Alias is optional for non-key columns, but you must specify the Column family and Column name. If an Alias is not supplied, then the Column name is used.
You must supply Type information for all the fields.
The key fields table includes the following columns:
| Column | Description |
| # | The order of the mapping operation. |
| Alias | The name you want to assign to the HBase table key. This value is required for the table key column, but optional for non-key columns. |
| Key | Specify if the field is the table's key. The values are Y and N. |
| Column family | The column family in the HBase source table that the field belongs to. Non-key columns must specify a column family and column name. |
| Column name | The name of the column in the HBase table. |
| Type |
The data type for the column. When the Key value is set to Y, the following key column values display in the drop-down list:
When the Key value is set to N, the following non-key column values display in the drop-down list:
|
| Indexed values | Comma-separated data in this field defines the values for string columns. |
To save the mapping in HBase, click Save mapping. You are prompted to correct any missing information in the mapping definition before proceeding.
- If you provided valid connection details and named the mapping, the mapping is saved to the cluster in HBase.
- If you only need the mapping locally, then the connection details and mapping name are not required and the mapping information is serialized automatically into the transformation metadata.
To delete a mapping in HBase, click Delete mapping. The current named mapping in the current named table is deleted from the mapping table, but the actual HBase table remains.
To partially populate the key fields table with fields that define a tuple mapping, click Create a tuple template. Tuple output mode inserts all the data in wide HBase rows where the number of columns may vary from row to row. It assumes that all column values are of the same type. A tuple mapping consists of the following output fields:
- KEY
- Family
- Column
- Value
- Timestamp
The type for "Family" is preconfigured to String and the type for "Timestamp" is preconfigured to Long. You must provide the types for "KEY", "Column" (column name) and "Value" (column value). The default behavior is to output all column values in all column families.
Additional notes on data types
For keys to sort properly in HBase, you must make the distinction between signed and unsigned numbers. Because of the way that HBase stores integer and long data internally, the sign bit must be flipped before storing the signed number so that positive numbers sort after negative numbers. Unsigned integer and unsigned long data can be stored directly without inverting the sign.
The following data types have these additional options or requirements:
String columns
May optionally have a set of legal values defined for them by entering comma-separated data into the Indexed values column in the key fields table.
Date keys
Can be stored as either signed or unsigned long data types, with epoch-based timestamps. If you have a date key mapped as a String type, PDI can change the type to Date for manipulation in the transformation. No distinction is made between signed and unsigned numbers for the Date type because HBase only sorts on the key.
Boolean values
May be stored in HBase as a 0/1 Integer/Long, or as a String (Y/N, yes/no, true/false, T/F).
BigNumber
May be stored as either a serialized BigDecimal object or in string form (a string that can be parsed by BigDecimal's constructor).
Serializable
Any serialized Java object.
Binary
A raw array of bytes.
Using HBase Row Decoder with Pentaho MapReduce
The HBase Row Decoder step is designed specifically for use in MapReduce transformations to decode the key and value data that is output by the TableInputFormat. The key output is the row key from HBase. The value is an HBase result object containing all the column values for the row.
The following use case shows you how to configure Pentaho MapReduce to use the TableInputFormat for reading data from HBase. It also shows you how to configure a MapReduce transformation to process that data using the HBase Row Decoder step.
First, create a Pentaho MapReduce job entry that includes a transformation which uses a MapReduce Input step and an HBase row decoder step, as shown below:
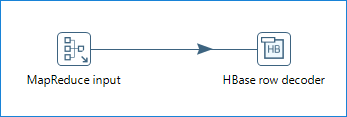
In the transformation, open the MapReduce
Input step. Configure the Key field and Value
field to produce a serialized result by selecting
Serializable in the Type field: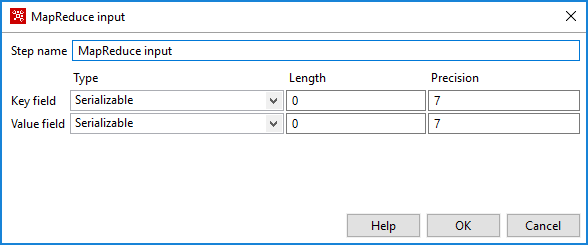
Next, open the HBase row decoder step and set the Key field to use the key and the HBase result field to use the value produced by the MapReduce Input step.
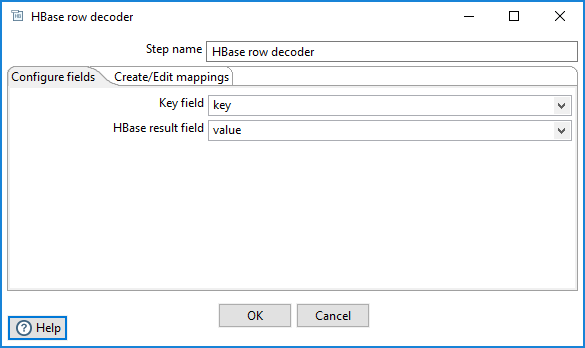
Then, define or load a mapping in the Create/Edit mappings tab. Note that once defined (or loaded), this mapping is captured in the transformation metadata.
Next, configure Pentaho MapReduce job entry to ensure that input splits are created using the TableInputFormat. Define the Input Path and Input format fields in the Job Setup tab, as shown below.
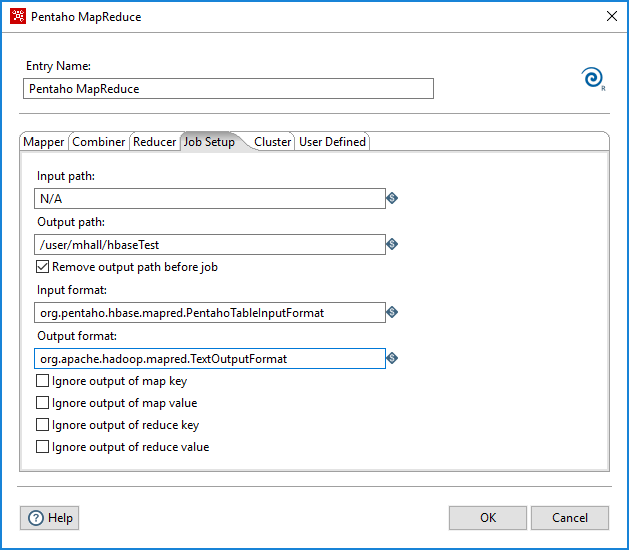
Finally, in the User Defined tab, assign a Name and Value for each property shown in the table below to configure the scan performed by the TableInputFormat:
| Name | Value |
hbase.mapred.inputtable | The name of the HBase table to read from. (Required) |
hbase.mapred.tablecolumns | The space delimited list of columns in ColFam:ColName format. Note that if you want to read all the columns from a family, omit the ColName. (Required) |
hbase.mapreduce.scan.cachedrows | (Optional) The number of rows for caching that will be passed to scanners. |
hbase.mapreduce.scan.timestamp | (Optional) Time stamp used to filter columns with a specific time stamp. |
hbase.mapreduce.scan.timerange.start | (Optional) Starting time stamp to filter columns within a given starting range. |
hbase.mapreduce.scan.timerange.end | (Optional) End time stamp to filter columns within a given ending range. |
Metadata injection support
All fields of this step support metadata injection except for the Hadoop Cluster field. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.