Bulk load into Snowflake

The Bulk load into Snowflake job entry in PDI loads vast amounts of data into a Snowflake virtual warehouse in a single session. For more information about working with Snowflake in PDI, see PDI and Snowflake.
This entry automates Snowflake's COPY INTO command to populate your Snowflake data warehouse with your PDI data, eliminating the need for repetitive SQL scripting. To use the Bulk load into Snowflake job entry, you must size your virtual warehouse, define the source and type of data to load, specify the target data warehouse, then provide any needed parameters.
For more information about using Snowflake, including best practices for bulk loading data, see the Snowflake documentation.
Before you begin
Before using the Bulk load into Snowflake job entry in PDI, you must have the following items:
- A Snowflake account.
- A connection to the database in which to load your data.
- An S3 connection or a VFS connection to a Snowflake staging area for your data source.
- A table and schema set up in the database where you want to place your data. On the first use, you will need to create the table.
General
The following field is general to this job entry:
- Entry Name: Specify the unique name of the job entry on the canvas. You can customize the name or leave it as the default.
Options
The Bulk load into Snowflake entry includes four tabs to define the data input source, the output database and location, options, and advanced options for loading PDI data into Snowflake. Each tab is described below.
Input tab
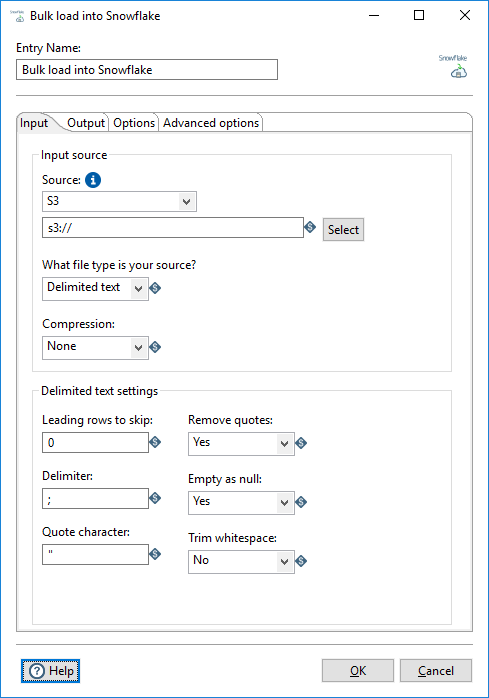
Use the options in this tab to define your input source for the Snowflake COPY INTO command:
| Option | Description |
| Source | Choose from one of the following input source types:
Click Select to specify the file, folder, prefix, or variable of the S3 bucket or staging location to use as the input for the Snowflake COPY INTO command. See "Syntax" in the Snowflake documentation for more details specifying this option. |
| What file type is your source? | Select the file type of the input source. You can select one of the following types:
|
| Compression | Select the type of compression applied to your input source:
|
Depending on what file type you selected for the What file type is your source option, the following file settings appear at the bottom of this tab:
| File Type | File Settings |
| Delimited text | Specify the following settings for a delimited text file:
NoteFor delimited text files, you must have a table in your database with all the columns you need defined. |
| Avro | No additional settings. |
| JSON |
NoteSnowflake only uses the last duplicate value and discards the others.
|
| ORC |
Additional file settings for ORC files. |
| Parquet |
Additional file settings for Parquet files. |
| XML |
|
- JSON
- ORC
- Parquet
- XML
Output tab
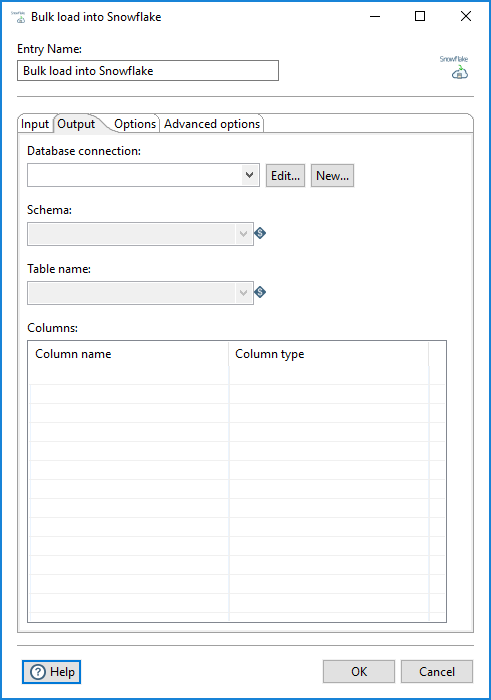
| Option | Description |
| Database connection | Select your database connection from a list of existing Snowflake
connections. If you do not have an existing connection, click New. If you need to modify an existing connection, click Edit. See Define Data Connection for instructions. Note: If timeout errors occur, see Snowflake timeout errors to troubleshoot. |
| Schema | Select the schema to use for the bulk load. The Bulk load into Snowflake entry reads the schemas that exist in the database to populate this list. |
| Table name | Select the name of the table to bulk load. The Bulk load
into Snowflake entry reads the table names from your selected schema
to populate this list. NoteYou can only load one table at a time. For multiple tables, use multiple
Bulk load into Snowflake entries or parameterized schema
and table names to change the table that is loaded. |
| Columns | Preview of the column names and associated data types within your selected table. |
Options tab
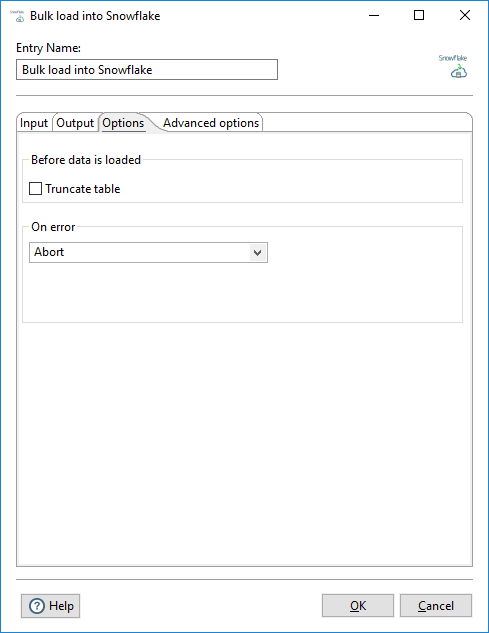
Use the options in this tab to define how the data is loaded using the Snowflake COPY INTO command:
| Option | Description |
| Truncate table | Select to remove all the data in the table before bulk loading the current data. When the Truncate table option is cleared, the data is appended during a new data load (default). |
| On error | Select one of the following values to indicate what to do if an
error occurs during the bulk load:
|
| Skip file after (x) errors | Enter the number of errors than can occur before the file is skipped in the loading process. This field displays when the Skip file number field is selected. |
| Skip file after (%) errors | Enter the percentage of errors than can occur before the file is
skipped in the loading process. This field displays when the Skip file percent field is selected. |
Advanced options tab
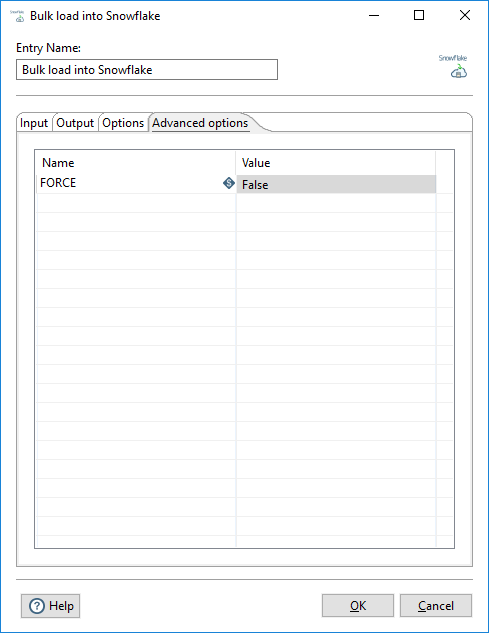
Use this tab to configure parameters for the Snowflake COPY INTO command. Any
Name/Value pair added as a parameter is passed to Snowflake as a
parameter, but the validation of the parameter is the user’s responsibility. See Snowflake’s documentation for further details on these parameters. The
Force parameter here is provided as an example.
| Parameter | Description |
| Force | Specify to force loading of files into a database:
|