Unique Rows

The Unique Rows step removes duplicate rows from the input stream and filters only the unique rows as input data for the step.
Prerequisites
The input stream must be sorted in a step prior to the Unique Rows step; otherwise, only consecutive double rows will be correctly analyzed and filtered.
The rows do not have to be pre-sorted if you use the Unique Rows (HashSet) step, or use the Spark processing engine (Spark Engine) to run the transformation.
General
Use the Unique
Rows step to define parameters for your output and how you want to sort
duplicate rows. 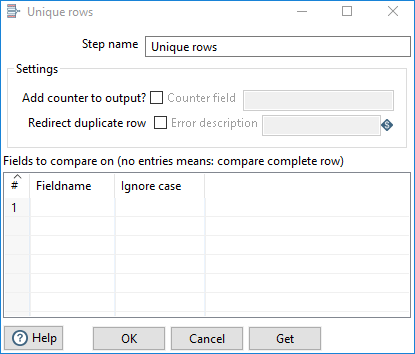
Enter the following information for the step:
- Step name: Specify the unique name of the transformation on the canvas. You can customize the name or leave it as the default.
Settings
The Unique Rows step requires definitions for the following options and parameters:
| Option | Description |
| Add counter to output? | Select this option to add a counter field to the output stream. |
| Counter field | Specify a name for the counter field. |
| Redirect duplicate row |
Select this option to process duplicate rows as an error and redirect them to the error stream of the step. If you do not select this option, the duplicate rows are deleted. AEL does not support certain fields resulting from the use of this option. Please do not select this option if you intend to run your transformation in Spark. |
| Error description | Specify the error handling description that displays when the step detects duplicate rows. This description is only available when Redirect duplicate row is selected. |
| Fields to compare table |
Specify the field names for which you want to find unique values. -OR- Select Get to insert all the fields from the input stream. |
| Ignore case |
You can choose to ignore case, such as upper-, lower-, and title-cases, by setting this option to Y. For example, 'Kettle', 'KETTLE', and 'kettle' are all treated as equivalent when Ignore case is set to Y. If you do not specify any field entries, the step compares the entire row. |