S3 File Output

The S3 File Output step writes data as a text file to Amazon Simple Storage Service (S3), a cloud-based storage system.
Big Data warning
Because data cannot be appended to S3 using an ‘append mode,’ and the data to send to S3 is generated in memory, an Out Of Memory Exception (OOME) error may occur followed by the java.io.IOException: Read end dead exception error when the transformation attempts to close the file.
You can use one of the following actions to avoid these errors:
- Increase the Java Heap Space (Xmx) setting for Spoon (see Increase the PDI client memory limit).
- Set the kettle property
s3.vfs.useTempFileOnUploadData=Y.
Using the latter method, the system can now generate a temporary file with data and upload it to Amazon S3. In most cases, the user has enough free space to store the temporary file and write permissions on the default temporary-file directory.
General
Enter the following information in the transformation step name field:
- Step name: Specifies the unique name of the S3 File Output transformation step on the canvas. You can customize the name or leave it as the default.
Options
The S3 File Output step features several tabs with fields. Each tab is described below.
File tab
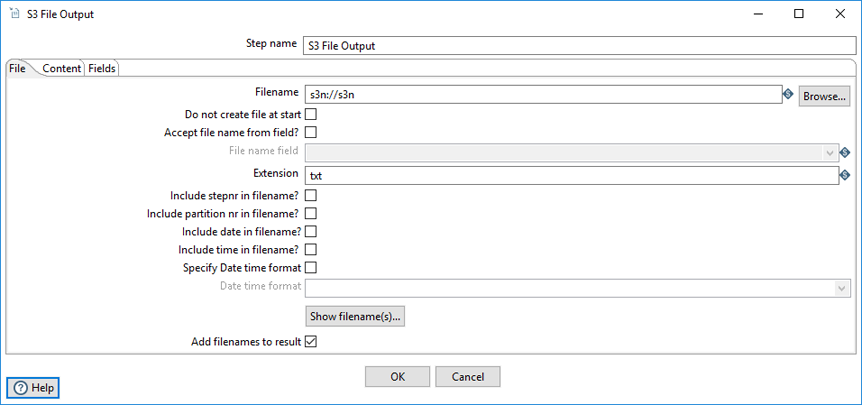
On the File tab, you can define the basic file properties for the output of this step.
| Option | Description |
| Filename | Specify the name of the output text file. The file name of a file in the S3
Cloud uses the following
schema: s3n://s3n/(s3_bucket_name)/(absolute_path_to_file) |
| Do not create file at start | Select to only create the file at the end of the processing cycle. |
| Accept file name from field? | Select to specify file names in a field in the input stream. |
| File name field | Specify the field that will contain the file names when Accept file name from field is selected. |
| Extension | Specify the three-letter file extension to append to the file name. The default is .txt. |
| Include stepnr in filename? | Select to include the copy number in the file name (_0 for example) when you run the step in multiple copies (launching several copies of a step). |
| Include partition nr in file name? | Select to include the data partition number in the file name. |
| Include date in file name? | Select to include the system date in the filename (_20181231 for example). |
| Include time in file name? | Select to include the system time in the filename (_235959 for example). |
| Specify Date time format | Select to include the date time in the filename using a format from the Date time format dropdown list. |
| Date time format | Select the date time format. |
|
Show filename(s) (button) | Click to display a list of the files that will be generated. This is a simulation and depends on the number of rows that go into each file. |
| Add filenames to result | Clear if you do not want to add file names to the output file. |
Content tab
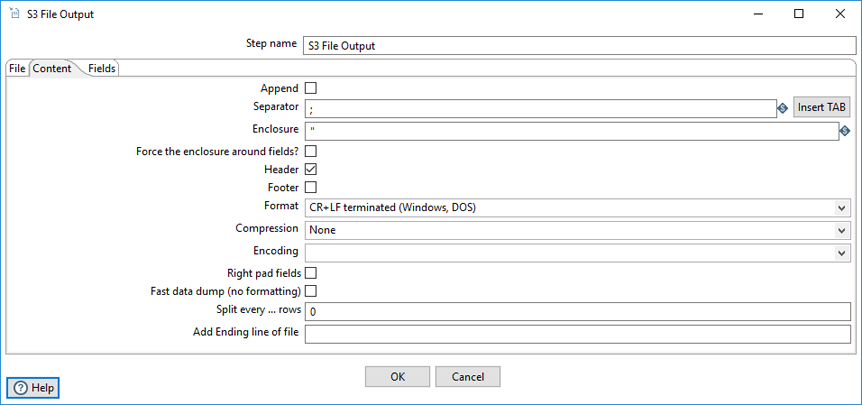
The Content tab allows you to include additional descriptive fields in the result set.
| Option | Description |
| Append | Select to append lines to the end of the file. |
| Separator | Specify the character used to separate the fields in a single line of text, typically a semicolon or tab. Click Insert Tab to place a tab in the Separator field. The default value is semicolon (;). |
| Enclosure | Specify to enclose fields with a pair of specified strings. It allows for separator characters in fields. This setting is optional and can be left blank. The default value is double quotes (“). |
| Force the enclosure around fields? | Specify to force all field names to be enclosed with the character specified in the Enclosure property. |
| Header | Clear to indicate that the output text file does not have a header row (first line in the file). |
| Format | Specify the type of formatting to use. It can be either DOS or UNIX. UNIX files have lines separated by line feeds, while DOS files have lines separated by carriage returns and line feeds. The default value is CR + LF (Windows, DOS). |
| Compression | Specify the type of compression (.zip or .gzip) to use when compressing the output. Only one file is placed in a single archive. The default value is None. |
| Encoding | Specify the text file encoding to use. Leave blank to use the default encoding on your system. To use Unicode, specify UTF-8 or UTF-16. On first use, PDI searches your system for available encodings. |
| Right pad fields | Select to add spaces to the end of the fields (or remove characters at the end) until the length specified in the table under the Fields tab is reached. |
| Fast data dump (no formatting) | Select to improve the performance when dumping large amounts of data to a text file by not including any formatting information. |
| Split every ... rows | Specify to split the resulting text file into multiple parts of N rows if the number N is larger than zero. |
| Add Ending line of file | Specify an alternate ending row to the output file. |
Fields tab
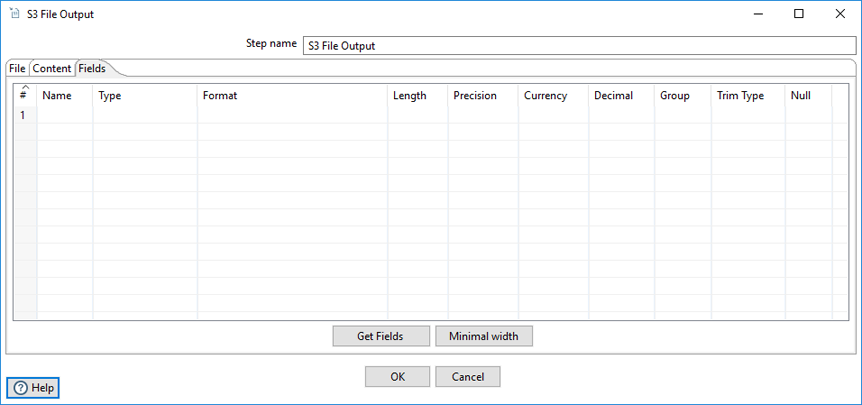
The Fields tab allows you to define the properties for the exported fields.
| Column | Description |
| Name | Specify the name of the field. |
| Type | Select the field's data type from the dropdown list or enter it manually. |
| Format | Select the format mask (number type) from the dropdown list or enter it manually. See Common Formats for information on common valid date and numeric formats you can use in this step. |
| Length |
Specify the length of the field, according to the following field types:
|
| Precision | Specify the number of floating point digits for number-type fields. |
| Currency | Specify the symbol used to represent currencies (for example, $ or €). |
| Decimal | Specify the symbol used to represent a decimal point, either a dot . or a comma , (for example, 5,000.00 or 5.000,00). |
| Group | Specify the method used to separate units of thousands in numbers of four digits or larger, either a dot . or a comma , (for example, 5,000 or 5.000). |
| Trim type | Select the trimming method to apply to a string, which truncates the field (none, left, right, both) before processing. Trimming only works when no field length is specified. |
| Null | Specify the string to insert into the output text file when the value of the field is null. |
|
Get Fields (button) | Click to retrieve a list of fields from the input stream. |
|
Minimal width (button) | Click to minimize the field length by removing unnecessary characters. If selected, string fields will no longer be padded to their specified length. |
AWS credentials
The S3 File Output step provides credentials to the Amazon Web Services SDK for Java using a credential provider chain. The default credential provider chain looks for AWS credentials in the following locations and in the following order:
Environment variables
The variables AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, and AWS_SESSION_TOKEN. See AWS Environment Variables.
AWS credentials file
The credentials file, located in the /.aws directory on Linux, macOS, and Unix operating systems, and in the "%UserProfile%\.aws directory on Windows operating systems. See AWS Configuration and Credential Files.
CLI configuration file
The config file is located in the same directory as the credentials file. The config file can contain a default profile, named profiles, and CLI-specific configuration parameters for each profile.
ECS container credentials
These credentials are provided by the Amazon Elastic Container Service on container instances set up by the ECS administrator. See AWS Using an IAM Role to Grant Permissions to Applications.
Instance profile credentials
These credentials are delivered through the Amazon EC2 metadata service, and can be used on EC2 instances with an assigned instance role.
The S3 File Output step can use any of these methods to authenticate AWS credentials. For more information on setting up AWS credentials, see Working with AWS Credentials.
Metadata injection support
All fields of this step support metadata injection. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.