Data Integration perspective in the PDI client

The Pentaho Data Integration perspective of the PDI Client (Spoon) enables you to create two basic file types:
- Transformations are used to perform ETL tasks.
- Jobs are used to orchestrate ETL activities, such as defining the flow and dependencies for what order transformations should be run, or preparing for execution by checking conditions.
The following sections describe how to use these transformations and jobs within the Data Integration perspective of Spoon.
Basic concepts of PDI
PDI uses a workflow metaphor as building blocks for transforming your data and other tasks. Workflows are built using steps or entries as you create transformations and jobs. Each step or entry is joined by a hop which passes the flow of data from one item to the next.
Transformations
A transformation is a network of logical tasks called steps. Transformations are essentially data flows. In the example below, the database developer has created a transformation that reads a flat file, filters it, sorts it, and loads it to a relational database table. Suppose the database developer detects an error condition and instead of sending the data to a Dummy step (which does nothing), the data is logged back to a table. The transformation is, in essence, a directed graph of a logical set of data transformation configurations. Transformation file names have a .ktr extension.
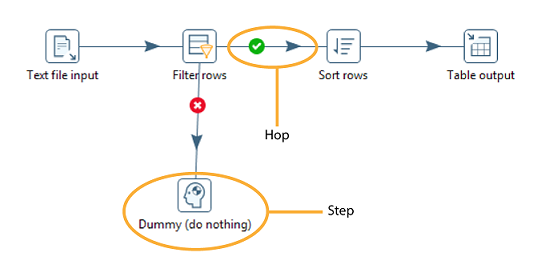
The two main components associated with transformations are steps and hops:
- Steps are the building blocks of a transformation, for example a text file input or a table output. There are many steps available in Pentaho Data Integration and they are grouped according to function; for example, input, output, scripting, and so on. Each step in a transformation is designed to perform a specific task, such
as reading data from a flat file, filtering rows, and logging to a database as shown in the example above. You can add a step by dragging it from the Design tab onto the canvas, or by
double-clicking the step. Steps can be
configured to perform the tasks you require.
Learn more about the features and ETL functions of the various transformation steps available in PDI.
- Hops are data pathways that connect steps together and allow schema metadata to pass from one step to another. In the image above, it seems like there is a sequential execution occurring; however, that is not true. Hops determine the flow of data through the steps not necessarily the sequence in which they run. When you run a transformation, each step starts up in its own thread and pushes and passes data.
You can connect steps together, edit steps, and open the step contextual menu by clicking to edit a step. For more information about connecting steps with hops, see Hops.
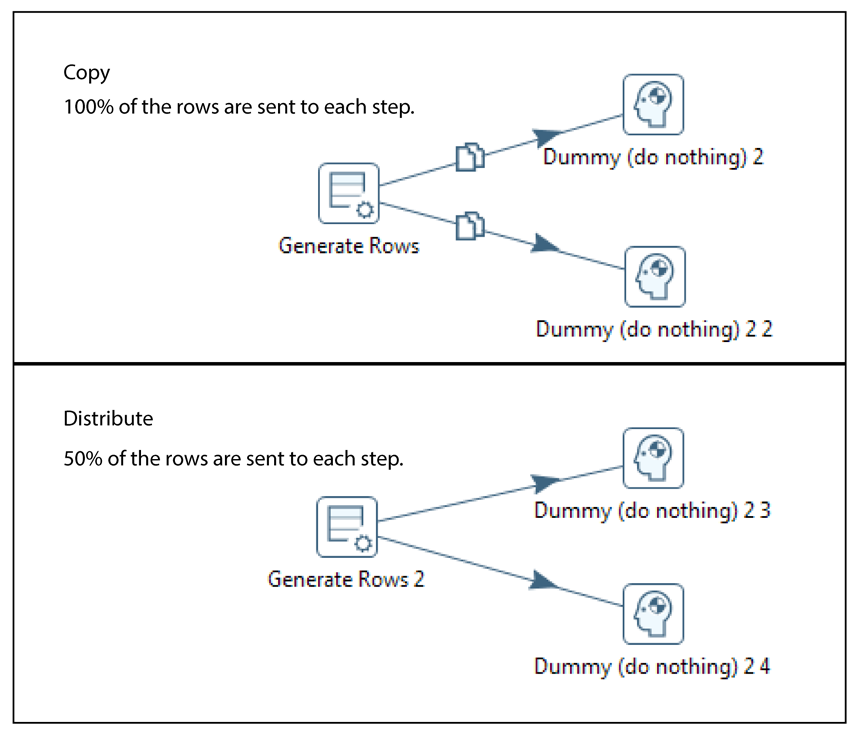
A step can have many connections. Some steps join other steps together, while some serve as an input or output for another step. The data stream flows through steps to the various steps in a transformation. Hops are represented in Spoon as arrows. Hops allow data to be passed from step to step, and also determine the direction and flow of data through the steps. If a step sends outputs to more than one step, the data can either be copied to each step or distributed among them.
Jobs
Jobs are workflow-like models for coordinating resources, execution, and dependencies of ETL activities.
Jobs aggregate individual pieces of functionality to implement an entire process. Examples of common tasks performed in a job include getting FTP files, checking conditions such as existence of a necessary target database table, running a transformation that populates that table, and e-mailing an error log if a transformation fails. The final job outcome might be a nightly warehouse update, for example.
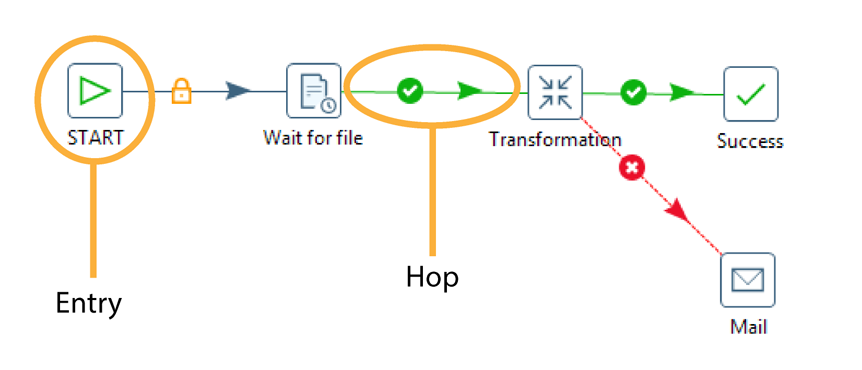
Job entries are the individual configured pieces as shown in the example above; they are the primary building blocks of a job. In data transformations these individual pieces are called steps. Job entries can provide you with a wide range of functionality ranging from executing transformations to getting files from a Web server. A single job entry can be placed multiple times on the canvas; for example, you can take a single job entry such as a transformation run and place it on the canvas multiple times using different configurations. Job settings are the options that control the behavior of a job and the method of logging a job’s actions. Job file names have a .kjb extension.
Learn more about the features and ETL functions of the various job entries available in PDI.
Job hops specify the execution order and the condition on which the next job entry will be executed. You can specify the Evaluation mode by right clicking on the job hop. A job hop is just a flow of control. Hops link to job entries and, based on the results of the previous job entry, determine what happens next.
Job hop conditions are specified in the following table:
| Condition | Description |
| Unconditional | Specifies that the next job entry will be executed regardless of the result of the originating job entry |
| Follow when result is true | Specifies that the next job entry will be executed only when the result of the originating job entry is true; this means a successful execution such as, file found, table found, without error, and so on |
| Follow when result is false | Specifies that the next job entry will only be executed when the result of the originating job entry was false, meaning unsuccessful execution, file not found, table not found, error(s) occurred, and so on |
Hops
A hop connects one transformation step or job entry with another. The direction of the data flow is indicated by an arrow. To create the hop, click the source step, then press the SHIFT key and draw a line to the target step. Alternatively, you can draw hops by hovering over a step until the hover menu appears. Drag the hop painter icon from the source step to your target step.
Additional methods for creating hops include:
- Click on the source step, hold down the middle mouse button, and drag the hop to the target step.
- Use CTRL and left-click to select two steps the right-click on the step and choose New Hop.
To split a hop, insert a new step into the hop between two steps by dragging the step over a hop. Confirm that you want to split the hop. This feature works with steps that have not yet been connected to another step only.
Loops are not allowed in transformations because Spoon depends heavily on the previous steps to determine the field values that are passed from one step to another. Allowing loops in transformations may result in endless loops and other problems. Loops are allowed in jobs because Spoon executes job entries sequentially; however, make sure you do not create endless loops.
Mixing rows that have a different layout is not allowed in a transformation; for example, if you have two table input steps that use a varying number of fields. Mixing row layouts causes steps to fail because fields cannot be found where expected or the data type changes unexpectedly. The trap detector displays warnings at design time if a step is receiving mixed layouts.
You can specify if data can either be copied, distributed, or load balanced between multiple hops leaving a step. Select the step, right-click and choose Data Movement.
A hop can be enabled or disabled (for testing purposes for example). Right-click on the hop to display the Options menu.
PDI client options
The PDI client allows you to customize certain aspects of its behavior. To access the options, choose . The following table describes the General tab options for working with transformations and jobs:
| Option | Description |
| Preview data batch size | Sets batch size of the preview data buffer. When you preview data, this option sets the buffer size used for these values. |
| Max number of lines in the logging windows | Specifies the maximum limit of rows to display in the logging window. |
| Central log line store timeout in minutes | Indicates the number of minutes before the central log line store times out. |
| Max number of lines in the log history | Specifies the maximum limit of line to display in the log history views. |
| Show welcome page at startup | Controls whether or not to display the Welcome page when launching the PDI client. |
| Use database cache | The PDI client caches information that is stored on the source and target databases. In some instances, caching causes incorrect results when you are making database changes. To prevent errors you can disable the cache altogether instead of clearing the cache every time. |
| Open last file at startup | Loads the last transformation you used (opened or saved) from XML or repository automatically. |
| Autosave changed files | Automatically saves a changed transformation before running. |
| Only show the active file in the main tree | Reduces the number of transformation and job items in the main tree on the left by only showing the currently active file. |
| Only save used connections to XML | Limits the XML export of a transformation to the used connections in that transformation. This is helpful while exchanging sample transformations to avoid having all defined connections to be included. |
| Replace existing objects on open/import | Replaces objects, such as existing database connections, during import. If the Ask before replacing objects is also checked, you will be prompted before the import occurs. Requests permission before replacing objects, such as existing database connections during import. |
| Ask before replacing objects | Requests permission before replacing objects, such as existing database connections during import. |
| Show Save dialog | Allows you to turn off the confirmation dialogs you receive when a transformation has been changed. |
| Automatically split hops | Disables the confirmation messages that launch when you want to split a hop. |
| Show Copy or Distribute dialog | Disables the warning message that appears when you link a step to
multiple outputs. This warning message describes the two options for handling
multiple outputs:
|
| Show repository dialog at startup | Controls whether or not the Repository dialog box appears at startup. |
| Ask user when exiting | Controls whether or not to display a confirmation dialog when a user chooses to exit the application. |
| Clear custom parameters (steps/plugins) | Clears all parameters and flags that were set in the plug-in or step dialog boxes. |
| Auto collapse palette tree | Indicates whether the palette tree should be collapsed automatically. |
| Display tooltips | Controls whether or not to display tool tips for the buttons on the main tool bar. |
| Show help tooltips | Displays help tool tips. A tool tip is a short description that appears when you hover the mouse pointer over an object in the PDI client. |
Creating a transformation
In the Data Integration perspective, you can create transformations, work with transformations, and inspect data within transformations.
Create a transformation
Procedure
Perform one of the following actions:
- Click .
- Click the New file icon in the toolbar and select Transformation.
- Hold down the CTRLN keys.
Go to the Design tab. Expand the folders or use the Steps field to search for a specific step.
Either drag or double-click a step to place it on the PDI client canvas.
Double-click the step in the PDI client canvas to open its properties window. For help with filling out the window, click the Help button that is available with each step.
To add another step, either drag or double-click the step in the Design tab to place it on the PDI client canvas.
- If you drag the step to the canvas, you can add a hop by pressing the SHIFT key and drawing a hop from one step to the other.
- If you double-click it, the step appears on the canvas with a hop already connected to your previous step.
Results
Work with transformations
You can save, open, and run transformations.
Inspect your data
You can also gain valuable insights into the data.
Creating a job
In the Data Integration perspective, you can create and work with a job.
Create a job
Procedure
Perform one of the following actions:
- Click .
- Click the New file icon in the toolbar and select Job.
- Hold down the CTRLALTN keys.
Go to the Design tab. Expand the folders or use the Entries field to search for specific entries.
Either drag or double-click an entry to place it on the PDI client canvas.
Double-click the entry to open its properties window. For help on filling out the window, click the Help button that is available in each entry.
To add another entry, either drag or double-click the entry to place it on the PDI client canvas.
- If you dragged the entry to the canvas, you can add a hop by pressing the SHIFT key and drawing a hop from one entry to the other.
- If you double-click it, the entry appears on the canvas with a hop already connected to your previous entry.
Results
Work with jobs
You can save, open, and run jobs.
Add notes to transformations and jobs
Add and manage notes to your transformations and jobs.
Adaptive Execution Layer
Pentaho uses the Adaptive Execution Layer for running transformations with different engines. AEL adapts steps from the transformation you develop in PDI to native operators in the engine you select for your environment, such as AEL-Spark in a Hadoop cluster. The AEL-Spark engine is better suited for running big data transformations in a Hadoop cluster.
When you select the AEL-Spark engine for running your transformation, AEL matches steps in your transformation to the native operators in the Spark engine. For example, if your transformation contains a Hadoop File Input step, AEL uses an equivalent Spark operator. AEL builds a transformation definition for Spark, which moves execution directly to the cluster, leveraging Spark’s ability to coordinate large amount of data over multiple nodes.
AEL must be configured before using the Spark engine. Refer your Pentaho or IT administrator to Set up the Adaptive Execution Layer (AEL) for more details. Once configured, you can select the Spark engine through run configurations. See Run Configurations for more details.
Virtual file system browser
Some transformation steps and job entries have virtual file system (VFS) dialog boxes in place of the traditional local file system windows.
Logging and performance monitoring
Configure logging to monitor transformation or job performance.
Advanced topics
The following topics help to extend your knowledge of PDI beyond basic setup and use:
- PDI Run Modifiers
Use arguments, parameters, or variables to modify how you run transformation and jobs.
- Reuse Transformation Flows with
Mapping Steps
Learn how to map commonly used steps into their own steps.
- Use Checkpoints to Restart
Jobs
Learn how to restart a job at the last checkpoint before an error occurred.
- Use the SQL Editor
Learn how to generate SQL statements.
- Use the Database Explorer
Explore configured database connections.
- Transactional Databases and Job
Rollback
Implement job rollback by making the transformation or job databases transactional.
- Interact with Web
Services
Determine what must occur if your transformation or job interacts with a web service.