Bulk load into Databricks
You can use the Bulk load into Databricks entry to load large amounts of data from files in your cloud accounts into Databricks tables. The entry uses the Databricks COPY INTO command to load the data.
General
Enter the following information in the job entry name field:
- Step name: Specifies the unique name of the Bulk load into Databricks job entry on the canvas. You can customize the name or leave it as the default.
Options
The Bulk load into Databricks entry requires you to specify options and parameters in the Input and Output tabs. Each tab is described below.
Input tab
Use this tab to configure information about the file to copy into the output table. The input file must exist in either a Databricks external location or a managed volume.
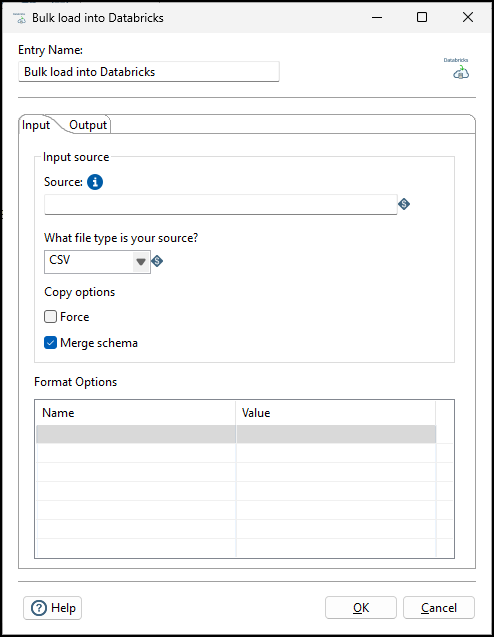
| Field | Description |
| Source | Specify the path to the input file. This must be the path to a file in a Databricks external location or managed volume. |
| What file type is your source? |
Specify the format of the source file. The supported formats are:
|
| Force | Set to false to skip files that have already been copied into the target table (Default). When set to true, files are copied again, even if they have already been copied into the table . |
| Merge schema |
Set to false to fail if the schema of the target table does not match the schema of the incoming files (Default). When set to true, new columns are added to the target table for each column in the source file that does not exist in the target table. Note that the target column types must match the source column types even when Merge schema is selected |
| Format Options |
Each file format has a number of options that are specific to that format. Use this table to specify the appropriate options for your file format. See Databricks Format options. NoteThis entry does not validate that the options entered are appropriate for the file format selected.
|
Output tab
Use this tab to configure the target table in Databricks. Once a connection is selected for the entry to use, the Catalog field is populated with the available catalogs from that Databricks connection. Once you select a catalog, the Schema field is populated, then when you select a Schema, the tables are populated.
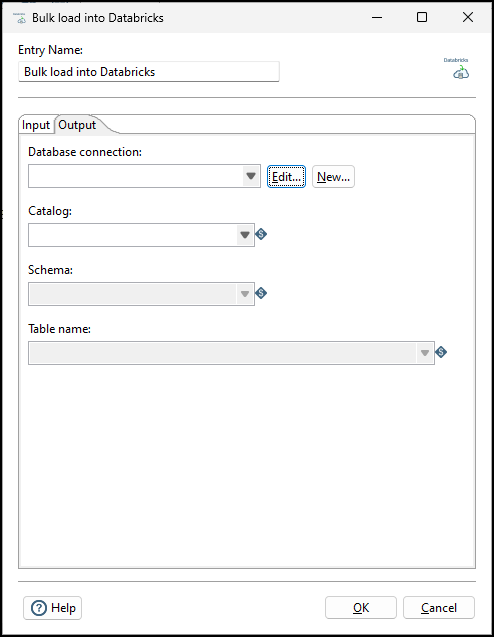
| Field | Description |
| Database connection |
Specify the database connection to the Databricks account. Click Edit to revise an existing connection; click New to add a new connection. Note You must select Generic database as the Connection type to create a connection. Examples of a Custom connection URL are
jdbc:databricks://<server hostname>:443;HttpPath=<HTTP path>;PWD=<Personal Access Token> and jdbc:databricks://<serverhostname>:443;HttpPath=<HTTP path>. The Custom driver class name is com.databricks.client.jdbc.Driver. |
| Catalog | Specify a catalog from the list of available catalogs in your Databricks connection. |
| Schema | Specify the schema of the target table. |
| Table name | Specify the name of the target table. |