PDI and Hitachi Content Platform (HCP)

Hitachi Content Platform (HCP) is the distributed, fixed-content, data storage system from Hitachi Vantara. HCP provides a scalable, easy-to-use repository that can accommodate all types of data, from simple text files to medical images to multigigabyte database images. Read the About Hitachi Content Platform article to learn more about HCP and how it works.
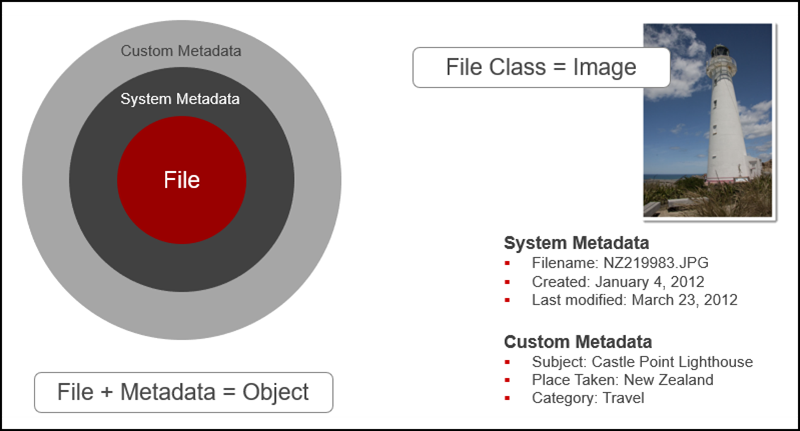
For working with Pentaho Data Integration (PDI), it's useful to remember a few key terms. HCP stores objects in a repository. Each object permanently associates data HCP receives (for example, a document, an image, or a movie) with information about that data called metadata. In PDI, you can query the metadata to locate and access HCP objects. The HCP object (such as the image file below) consists of a read-only file, a unique URL, system metadata properties, and custom metadata annotations.
When using the PDI steps for HCP, you should be familiar with how the HCP repository is partitioned into namespaces. A namespace is a logical grouping of objects such that the objects in one namespace are not visible in any other namespace. Before you can query HCP from PDI, you will need to verify settings and options for your namespaces in the System Management Console and the Tenant Management Console.
PDI currently supports HCP version 8.0.0.9.
You can use PDI transformation steps to improve your HCP data quality before storing the data in other formats, such as JSON , XML, or Parquet. By using PDI to cleanse your HCP data, you can:
- Connect to a wide variety of data sources, import data from those sources, and then store that data in HCP as metadata of your objects.
- Blend data from sources that are in different formats, and then store the aggregated data as object metadata in HCP.
- Extract metadata from HCP, transform the data, then send the data to cloud storage.
PDI has three transformation steps you can use to work with your metadata in HCP.
Locate data objects by searching system and custom metadata annotations. HCP returns the unique URL of objects matching your search terms. For example, a radiology practice can search for an X-ray (object) of a specific patient or all X-rays performed by a specified physician.
Identify and select an HCP object by its URL path and then select a specific target annotation name to read. The step returns the requested custom metadata from the annotation back to your PDI transformation for downstream processing.
Identify and select an HCP object by its URL and then write custom metadata annotations to the object associated with the object URL, enriching and validating the data stored in your HCP repository. For example, a radiology practice could add patient medication data and associated medical conditions to an X-ray (object) or remove invalid diagnosis codes.
These steps use a Virtual File System (VFS) connection to access the HCP repository. See Connecting to Virtual File Systems for details.