Cassandra Output

The Cassandra Output step writes data to a table (column family) of an Apache Cassandra database using CQL (Cassandra Query Language) version 3.x.
General
Enter the following information in the transformation step field.
- Step Name: Specifies the unique name of the Cassandra Output step on the canvas. You can customize the name or leave it as the default.
Options
The Cassandra Output transformation step features several tabs with fields. Each tab is described below.
Connection tab
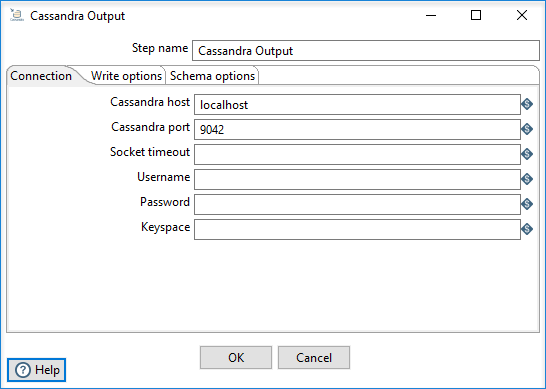
This tab includes the following options:
| Option | Description |
| Cassandra host | Specify the host name for the connection to the Cassandra server. |
| Cassandra port | Specify the port number for the connection to the Cassandra server. |
| Socket timeout | Set an optional connection timeout period, specified in milliseconds. |
| Username | Specify the username of the target keyspace and/or table authentication details. |
| Password | Specify the password of the target keyspace and/or table authentication details. |
| Keyspace | Specify the keyspace (database) name. |
Write options tab
The Cassandra Output step provides a number of options that control what and how data is written to the target Cassandra keyspace (database). This tab contains the following connection details and basic query information (in particular, how to connect to Cassandra and execute a CQL query to retrieve rows from a table):
| Option | Description |
| Table to write to | Specify which the table (column family) to write the incoming rows. |
| Get table names | Click if you want to populate the Table to write to list with names of all the tables that exist in the specified keyspace. |
| Consistency level |
Specify an explicit write consistency. The following values are valid:
The Cassandra default is ONE. |
| Commit batch size | Specify the number of rows to send with each commit |
| Batch insert timeout | Specify the number of milliseconds to wait for a batch to completely insert before splitting into smaller sub-batches. You must specify a value lower than Socket timeout or leave empty for no timeout. |
| Sub batch size | Specify the sub-batch size (in number of rows) if the batch must be split because Batch insert timeout is reached. |
| Insert unlogged batches | Select if you want to use non-atomic batch writing. By default, batches are atomic (if any of the batch succeeds, all of it will succeed). Select this option to remove the atomic restriction. |
| Time to live (TTL) | Specify the amount of time in which to write a column. If the time expires, that column is deleted. |
| Incoming field to use as the key | Specify which incoming field to use as the key. You can use to specify the key from the names of incoming PDI transformation fields. |
| Select fields | Select from a list of incoming PDI transformation fields to specify as the Incoming field to use as the key. |
| Use CQL version 3 | Queries with CQL version 3. |
| Use Thrift I/O | Uses Thrift I/O. |
| Show schema | Click to open a dialog box that shows metadata for the table specified in Table to write to. |
INSERT statement according to PDI's field metadata. If resulting values cannot be parsed by the Cassandra column validator for a particular column then an error occurs.Cassandra Output converts PDI's dense row format into sparse data by ignoring incoming null field values.
Schema options tab
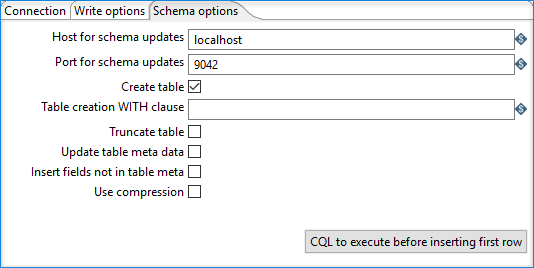
This tab includes the following options:
| Option | Description |
| Host for schema updates | Specify the host name for the connection to the Cassandra schema. |
| Port for schema updates | Specify the port number for the connection to the Cassandra schema. |
| Create table | Select to create a named table (column family) if one does not already exist. |
| Table creation WITH clause | Specify additions to the table creation WITH clause. |
| Truncate table | Select if you want any existing data to be deleted from the named table before inserting incoming rows. |
| Update table meta data | Select if you want to update the table metadata with information on incoming fields not already present. If this option is not selected, any unknown incoming fields are ignored unless the Insert fields not in column meta data option is selected. |
| Insert fields not in column meta data | Select if want to insert the table metadata in any incoming fields not present, with respect to the default table validator. This option has no effect if Update table meta data is selected. |
| Use compression | Select if you want the text of each BATCH INSERT statement compressed (with GZIP) before transmitting it to the node. |
| CQL to execute before inserting first row | Click to specify additional CQL statements you may want to execute before inserting the first row. |
Update table metadata
Selecting the Update table meta data option will result in the table metadata getting updated with information on incoming fields not already present. If this option is not selected, any unknown incoming fields are ignored unless Insert fields not in column meta data is selected. If the latter is selected, then any incoming fields that are not present in the table metadata will be inserted with respect to the default table validator. This option has no effect if Update table meta data is selected.
INSERT statement according to PDI's field meta data. If resulting values cannot be parsed by the Cassandra column validator for a particular column, then an error will occur.Pre-Insert CQL
You have the option of executing an arbitrary set of CQL statements prior to inserting the first incoming PDI row. It is useful for creating or dropping secondary indexes on columns. Clicking CQL to execute before inserting first row opens a CQL editor. You can enter multiple CQL statements as long as each is terminated by a semicolon, as shown in the following example:
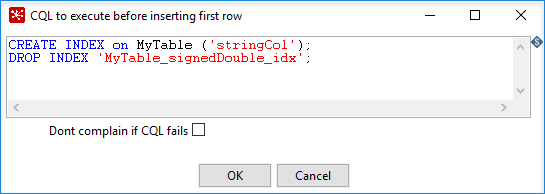
Pre-insert CQL statements are executed after any table metadata updates for new incoming fields, and before the first row is inserted. This allows for indexes to be created for columns corresponding new incoming fields.
Metadata injection support
All fields of this step support metadata injection. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.