Data integration issues

Follow the suggestions in these topics to help resolve common issues associated with Pentaho Data Integration:
- Troubleshooting transformation steps and job entries
- Troubleshooting database connections
- Jobs scheduled on Pentaho Server cannot execute transformation on remote Carte server
- Cannot run a job in a repository on a Carte instance from another job
- Troubleshoot Pentaho data service issues
- Kitchen and Pan cannot read files from a ZIP export
- Using ODBC
- Improving performance when writing multiple files
See Pentaho Troubleshooting articles for additional topics.
Troubleshooting transformation steps and job entries
If you have issues with transformation steps or job entries, check to see if these conditions apply to your situation.
'Missing plugins' error when a transformation or job is opened
If you try to open a transformation or job that contains a step or entry not installed in your copy of the PDI client, the following error message appears:
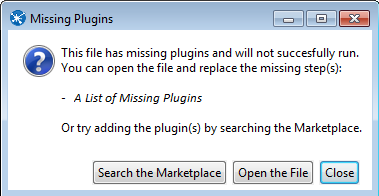
To resolve this issue, either add the step or entry in the PDI client or find it in the marketplace and install it. See the Use the Pentaho Marketplace to manage plugins article for details.
Cannot execute or modify a transformation or job
Have an administrative user check to see if your role has been granted the Execute permission.
Step is already on canvas error
Regardless of whether a step is hidden or displayed in the canvas, it is listed in the Steps folder under your transformation in the View tab of the Data Integration perspective. To redisplay the hidden step on the canvas, drag it from the Steps folder in the View tab to the canvas.
Troubleshooting database connections
If you have issues with database connection in PDI, check to see if any the following conditions apply to your situation.
Unsupported databases
You can add or replace database driver files in the lib directory located under: ...\design-tools\data-integration
Database locks when reading and updating from a single table
For example, if you have a step which reads from a row within a table (a Table Input step) and you need to update the transformation with the Update step, this could cause locking issues, especially with MS SQL databases. Reading and updating rows in the same transformation in the same table should be avoided.
A general solution compatible with all databases is to duplicate the table to be read/updated, and then create separate read/update steps. Arrange the steps to be executed sequentially within the transformation, each on a different, yet identical, version of the same table. Adjusting database row locking parameters or mechanisms will also resolve this issue.
Force PDI to use DATE instead of TIMESTAMP in Parameterized SQL queries
The predicate DATE used at line ID 1 of the execution plan contains an implicit data type conversion on indexed column DATE. This implicit data type conversion prevents the optimizer from selecting indices on table A.To resolve this issue, use a Select Values step and set Precision to1 and Value to DATE. These changes force the parameter to be set as a DATE instead of a TIMESTAMP.
PDI does not recognize changes made to a table
Clearing the cache addresses this issue. The cache needs to be cleared of database-related meta information (field names and their types in each used database table). PDI has this cache to increase processing speed. Perform the following steps to clear this information in the cache from within the PDI client:
Procedure
Select the connection.
Use either of these methods to clear the cache:
Jobs scheduled on Pentaho Server cannot execute transformation on remote Carte server
ERROR 11-05 09:33:06,031 - !UserRoleListDelegate.ERROR_0001_UNABLE_TO_INITIALIZE_USER_ROLE_LIST_WEBSVC!
com.sun.xml.ws.client.ClientTransportException: The server sent HTTP status code 401: Unauthorized You need to make the following configuration changes to remotely execute scheduled jobs:
Procedure
Stop the Pentaho and Carte servers.
Copy the repositories.xml file from the .kettle folder on your workstation to the same location on your Carte slave. Without this file, the Carte slave will be unable to connect to the Pentaho Server to retrieve PDI content.
Open the pentaho/server/pentaho-server/tomcat/webapps/pentaho/WEB-INF/web.xml file in a text editor.
Find the
Proxy Trusting Filtersection, then add your Carte server's IP address to theparam-valueelement. The following code block is a sample of theProxy Trusting Filtersection:<filter> <filter-name>Proxy Trusting Filter</filter-name> <filter-class>org.pentaho.platform.web.http.filters.ProxyTrustingFilter</filter-class> <init-param> <param-name>TrustedIpAddrs</param-name> <param-value>127.0.0.1,192.168.0.1</param-value> <description>Comma separated list of IP addresses of a trusted hosts.</description> </init-param> <init-param> <param-name>NewSessionPerRequest</param-name> <param-value>true</param-value> <description>true to never re-use an existing IPentahoSession in the HTTP session; needs to be true to work around code put in for BISERVER-2639</description> </init-param> </filter>Find the following code snippet in the web.xm file:
<filter-mapping> <filter-name>Proxy Trusting Filter</filter-name> <url-pattern>/i18n</url-pattern> </filter-mapping>After the code snippet above, add the following text in your file:
<!-- begin trust --> <filter-mapping> <filter-name>Proxy Trusting Filter</filter-name> <url-pattern>/webservices/authorizationPolicy</url-pattern> </filter-mapping> <filter-mapping> <filter-name>Proxy Trusting Filter</filter-name> <url-pattern>/webservices/roleBindingDao</url-pattern> </filter-mapping> <filter-mapping> <filter-name>Proxy Trusting Filter</filter-name> <url-pattern>/webservices/userRoleListService</url-pattern> </filter-mapping> <filter-mapping> <filter-name>Proxy Trusting Filter</filter-name> <url-pattern>/webservices/unifiedRepository</url-pattern> </filter-mapping> <filter-mapping> <filter-name>Proxy Trusting Filter</filter-name> <url-pattern>/webservices/userRoleService</url-pattern> </filter-mapping> <filter-mapping> <filter-name>Proxy Trusting Filter</filter-name> <url-pattern>/webservices/Scheduler</url-pattern> </filter-mapping> <filter-mapping> <filter-name>Proxy Trusting Filter</filter-name> <url-pattern>/webservices/repositorySync</url-pattern> </filter-mapping> <filter-mapping> <filter-name>Proxy Trusting Filter</filter-name> <url-pattern>/api/session/userName</url-pattern> </filter-mapping> <filter-mapping> <filter-name>Proxy Trusting Filter</filter-name> <url-pattern>/api/system/authentication-provider</url-pattern> </filter-mapping> <!-- end trust -->Save and close the file.
Edit the Carte.bat (Windows) or carte.sh (Linux) startup script on the machine that runs your Carte server.
Set an OPT variable to
-Dpentaho.repository.client.attemptTrust=true, as shown in the following sample line of code:- Windows:
SET OPT=%OPT% "-Dpentaho.repository.client.attemptTrust=true"
- Linux:
OPT="$OPT -Dpentaho.repository.client.attemptTrust=true"
- Windows:
Save and close the file, then start your Carte and Pentaho servers.
Results
Cannot run a job in a repository on a Carte instance from another job
RepositoriesMeta - Reading repositories XML file: <HOME>/.kettle/repositories.xml General - I couldn't find the repository with name 'singleDiServerInstance' (...) Secondary - Could not execute job specified in a repository since we're not connected to one (...)Perform the steps below to run jobs in a repository on a Carte instance from another job:
Procedure
Using an editor, open the <HOME>/.kettle/repositories.xml file on the server where the Carte instance is located.
Add a new
<repository>element to it or append the current content with the namesingleDiServerInstance, as shown in the following code block:<repository> <id>PentahoEnterpriseRepository</id> <name>singleDiServerInstance</name> <description/> <is_default>false</is_default> <repository_location_url>http://localhost:8080/pentaho</repository_location_url> <version_comment_mandatory>N</version_comment_mandatory> </repository>Save and close the file.
Results
Troubleshoot Pentaho data service issues
listService command, as shown in the following example URL:- http://localhost:8080/pentaho/kettle/listServices
If it does not appear in the list, try the following tasks:
- If you stored the transformation in the Pentaho Repository, check the status using this command: http://localhost:8080/pentaho/kettle/status. Make sure the repository name appears in the configuration details section. If the repository name is missing or an error appears, check the configuration of the slave-server-config and accessibility of the repositories.xml file.
- If you did not store the transformation in the Pentaho Repository, but instead stored it on the local file system, make sure the service name is listed and accessible from the user account that runs the Pentaho Server in: <users home>/.pentaho/metastore/pentaho/Kettle Data Service
If the service name (the table to query) is still missing, reopen the service transformation and check the data service in the transformation settings.
Kitchen and Pan cannot read files from a ZIP export
ZIP files must be prefaced by an exclamation point (!) character. On Linux and other Unix-like operating systems, you must escape the exclamation point with a backslash (\!) as in the following Kitchen example:
Windows:
Kitchen.bat /file:"zip:file:///C:/Pentaho/PDI
Examples/Sandbox/linked_executable_job_and_transform.zip!Hourly_Stats_Job_Unix.kjb"
Linux:
./kitchen.sh
-file:"zip:file:////home/user/pentaho/pdi-ee/my_package/linked_executable_job_and_transform.zip\!Hourly_Stats_Job_Unix.kjb"Using ODBC
Although ODBC can be used to connect to a JDBC compliant database, Pentaho does not recommend using it and it is not supported.
For details, this article explains Why you should avoid ODBC.
Improving performance when writing multiple files
You can use the two following Kettle properties to tune how the Text File Output step and the Hadoop File Output step work in a transformation.
- KETTLE_FILE_OUTPUT_MAX_STREAM_COUNT
This property limits the number of files that can be opened simultaneously by the step. The property only works when the "Accept file name from field?" option (in the File tab) is selected. In this scenario, each row coming into the step has a column containing the file name to which the remaining data in the row is to be written. If each row has a different file name, then the step will open a new file for each row. Once data is written to the file referenced in the row, the file is left open in case the next row references the same file. Leaving the file open prevents the step from aborting. If the transformation is processing many rows and each row has a different file name, then many files will be opened and there is a possibility of exhausting the number of open files allowed by the OS. To avoid this problem, use KETTLE_FILE_OUTPUT_MAX_STREAM_COUNT to define the maximum number of files the step can have open. Once the step reaches the maximum number of open files, it closes one of the open files before opening another. If the file that was closed is referenced in a later row, a different file will be closed and the referenced file will be reopened for append. Setting this parameter to 0 allows for an unlimited number of open files. The default is: 1024
- KETTLE_FILE_OUTPUT_MAX_STREAM_LIFE
This property defines the maximum number of milliseconds between flushes of all files opened by the step. The property is most useful when the "Accept file name from field?" option (in the File tab) is selected. Since the output written to each file is buffered, if many small files are opened and written to, there is a possibility that a large amount of buffered data could exhaust the system memory. Setting this property forces the buffered file data to be periodically flushed, reducing the amount of system memory used by the step. Setting this value to 0 prevents the file streams from being periodically flushed. The default value is: 0
To edit the Kettle properties file, follow the steps in: Set Kettle variables in the PDI client.