Elasticsearch REST Bulk Insert

Use the Elasticsearch REST Bulk Insert step if you have records that you want to submit to an Elasticsearch server for indexing. Elastic® is a platform of products to search, analyze, and visualize data. The Elastic platform includes Elasticsearch, which is a Lucene-based, multi-tenant capable, and distributed search and analytics engine. Use this step to send one or more batches of records to an Elasticsearch server for indexing. Because you can specify the size of a batch, you can use this step to send one, a few, or many records to Elasticsearch for indexing.
When record data flows out of the Elasticsearch REST Bulk Insert step, PDI sends it to Elasticsearch along with your index as metadata. This step is commonly used when you want to send a batch of data to an Elasticsearch server and create new indexes. You can also use this step to add a batch of data to an index. This step is a modified version of the ElasticSearch Bulk Insert step, which is now deprecated.
For more information on Elasticsearch, see https://www.elastic.co/guide/en/ElasticSearch/reference/current/index.html and https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html.
Before you begin
Before you begin, gather the following items:
- A working server with Elasticsearch version 7.x installed or create a SaaS offering for your Elasticsearch server. You should be able to connect to Elasticsearch from the computer running PDI.
- Privileges to create, insert, and update on the directories that you need to access on the Elasticsearch server.
- Files or data that you want Elasticsearch to index.
General
Enter the following information in the transformation step field.
- Step Name: Specifies the unique name of the Elasticsearch REST Bulk Insert step on the canvas. You can customize the name or leave it as the default.
Options
The Elasticsearch REST Bulk Insert step consists of three tabs: General, Document, and Output.
General tab
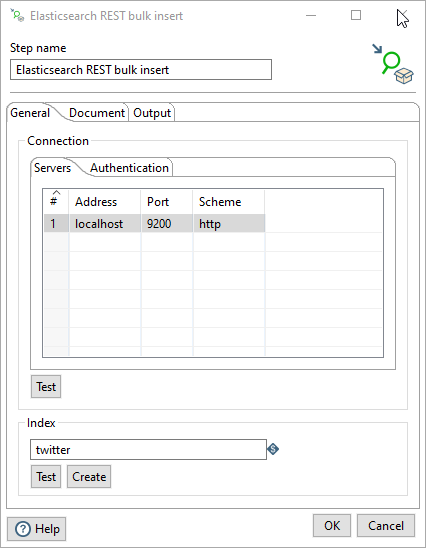
Use the General tab set connections for the Elastic nodes and set options for the destination index.
Specify the Connection options for each server in the table of the Servers tab. The following table describes these connection options:
| Column | Description |
| # | Number of the field’s entry. |
| Address | Enter the hostname (optionally specified with a variable) of the node you want to connect to. |
| Port | Enter the port (optionally specified with a variable) of the Elastic REST interface. |
| Scheme | Enter the scheme or protocol (optionally specified with a variable) to use when performing REST communication, which is usually http, or https for secured Elastic nodes. |
Set user verification options the Authentication tab to choose and test a verification method for the Elastic node user. The following table describes these user verification options:
| Field | Description |
| Authentication |
Select the authentication method for the Elastic nodes:
|
| Test | Click to test the connection and authentication settings. |
Use the Index options to name and test the output Elastic index.
| Field | Description |
| Index | Specify the name of the target index for the documents submitted by bulk insert requests. This value can be specified as a variable. If an index with that name does not yet exist in Elasticsearch, it creates one. |
| Test | Click to test the connectivity to the desired output index. |
| Create | Click to create the index if it does not exist. |
Document tab
You can use the Document tab to designate the documents that will be indexed in bulk insert requests by creating a document to index with stream field data or with an existing JSON document from a field.
Creating a document to index with stream field data
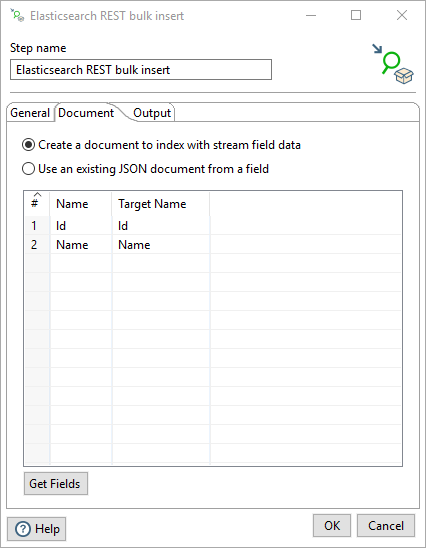
Use the Create a document to index with stream field data option if you want to turn each row of stream data into a unique JSON document to be indexed in the bulk request. You must define the fields to use from the input stream with a target name. Click Get Fields to automatically find all incoming stream data.
| Field | Description |
| Name | Enter the name of the source field that the step receives on the input stream. |
| Target name | Enter the name of the destination field in the generated JSON document to use for the input stream field. |
Using an existing JSON document from a field
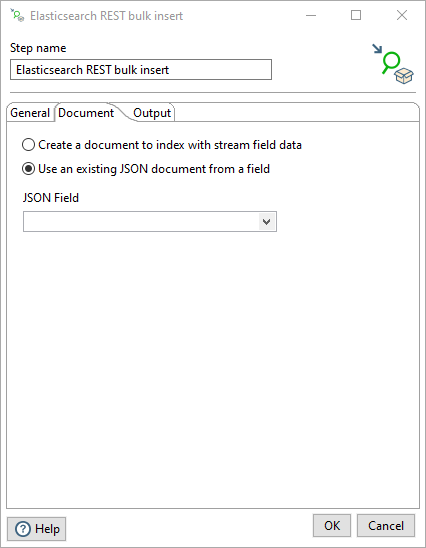
Choose the Use an existing JSON document from a field option if the document that you want to index is already in a JSON form in a field on the input stream.
| Field | Description |
| JSON Field | Select the name of the incoming field that contains a JSON document to be indexed for each row of input. |
Output tab
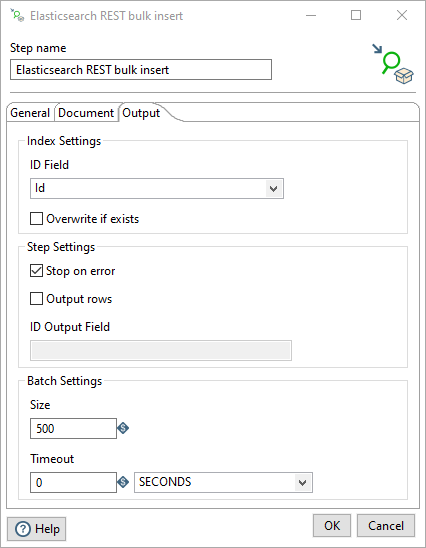
Use the Output tab configure the output of the step and error handling.
Select from the following Index Settings options for the field identifier and index handling.
| Field | Description |
| ID Field | (Optional) Enter a value that identifies the document indexed in Elasticsearch. If you do not enter a value, Elastic generates an ID automatically. |
| Overwrite if exists |
When selected and the ID Field is specified, update a document index if the ID already exists in the target Elastic index. If the destination ID does not exist in the index, then the new document index is added to the Elastic index. |
Select from the following Step Settings options to specify how row data and errors are processed.
| Field | Description |
| Stop on error | Stop processing if there is an error, such as a problem with adding the document or the bulk push to the index or if the JSON is not well-formed. If this option is not selected, and an error occurs, the row is not processed, but the transformation keeps running so that other rows are processed. |
| Output rows | Select to pass through the input row data as well as a new output document index ID if the ID Output Field value is specified. If you select Stop on Error, the rows that were successful up until the time the error occurs are sent to the next step or the output. Otherwise, rows successfully processed are sent to the next step or the output. |
| ID Output Field | (Optional) Enter the name of the ID field to output newly indexed document IDs. If this is left blank, the value in the ID Field is used. |
Select from the following Batch Settings options to set the number of rows and timeout value.
| Field | Description |
| Size | Specify the number of items in a batch. Specify a size greater than one to perform a bulk insert. A size of one does not perform a bulk insert. |
| Timeout | Specify a value and unit of measure to configure the maximum allowable period for the bulk request to process on the Elastic server before the batch times out, and processing ends. |