Catalog Input

You can use the Catalog Input step to read CSV text file types or Parquet data formats of a Lumada Data Catalog resource stored in a Hadoop or S3 ecosystem and output the data payload in the form of rows to be used by a transformation.
CSV files include formats generated by spreadsheets and fixed-width flat files. Parquet data formats are decoded and the fields are extracted using the schema defined in the Parquet source files.
Catalog Input can be used with the Catalog Output transformation step to gather data from various Data Catalog resources and move that data into Hadoop or S3 storage.
You must have role permissions set in Data Catalog to read the data resources.
For more information about accessing Lumada Data Catalog in PDI, see PDI and Lumada Data Catalog.
Before you begin
Before using the Catalog Input step, be aware of the following conditions:
- You must have an established Catalog connection to Data Catalog. For details, see Access to Lumada Data Catalog.
- S3 must be configured as the Default S3 Connection in VFS Connections to access S3 storage. For details, see Connecting to Virtual File Systems.
- You must have an established PDI connection to the cluster(s) you plan on using. For example, a Hadoop driver must be configured as a named connection for your distribution for accessing HDFS. For information on named connections, see Connecting to a Hadoop cluster with the PDI client.
General
The following fields are general to this transformation step.
| Field | Description |
| Step Name | Specify the unique name of the Catalog Input step on the canvas. You can customize the name or leave it as the default. |
| Connection |
Use the list to select the name of your connection to Data Catalog. See Connecting to Virtual File Systems for details. |
Input tab
Use the Input tab to specify the search method used to find the metadata about the payload to read from Data Catalog. Searches are performed on the schema of a supported format type according to the selected method.
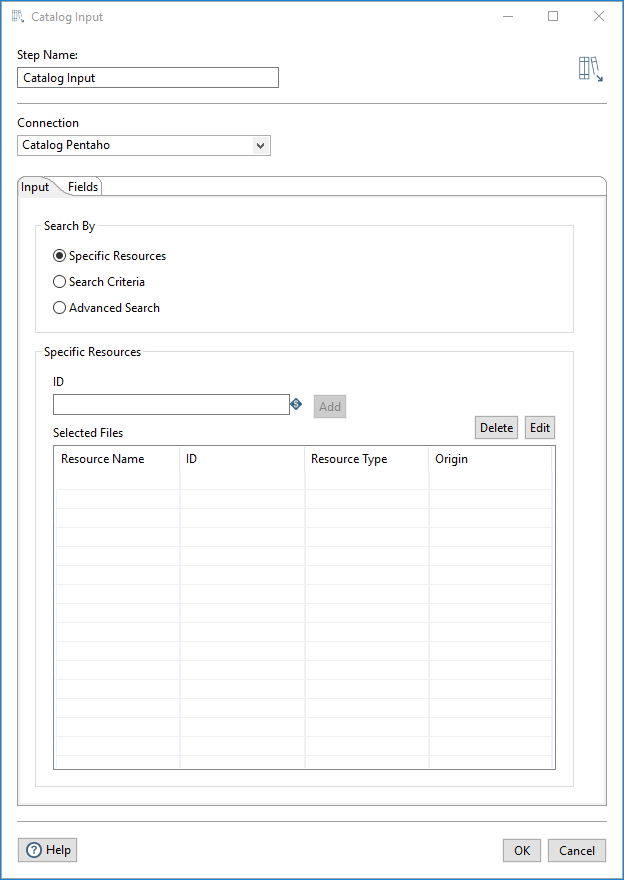
Select Specific Resources if you know the key value of the data resource.
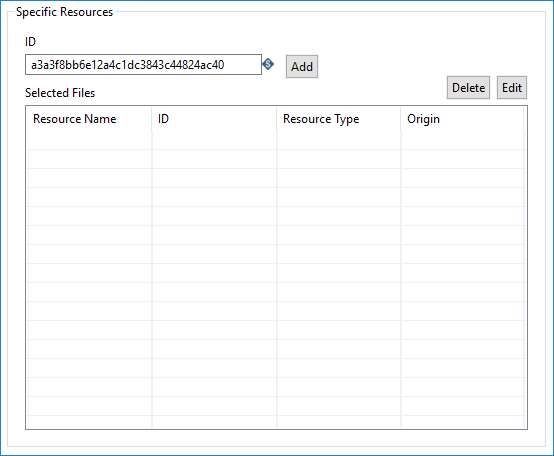
| Field | Description |
| ID | Enter the Data Catalog resource identifier. The resource must be profiled in Data Catalog to be available. |
| Add (button) | Click to retrieve the profiled data associated with the Resource ID in Data Catalog. |
| Delete (button) | Removes a selected resource from the Selected Files table. |
| Edit (button) | Allows you to edit a selected resource from the Selected Files table. |
Results of the search are displayed in the Selected Files table, which provides details about the resources that were found. You can use the Edit button to modify a resource detail or Delete to remove a resource from the search.
| Column | Description |
| Resource Name | Displays the name of the resource in Data Catalog. |
| ID | Displays the Data Catalog resource identifier. |
| Resource Type | Displays the type of the data type associated with the resource in Data Catalog. |
| Origin | Displays the origin of the resource in Data Catalog. |
Select Search Criteria if you know general information about the resource. The search filters all the results by the criteria selected. Enter a keyword in the Keyword field or select criteria from a drop-down menu, then click ADD to include it in the search.
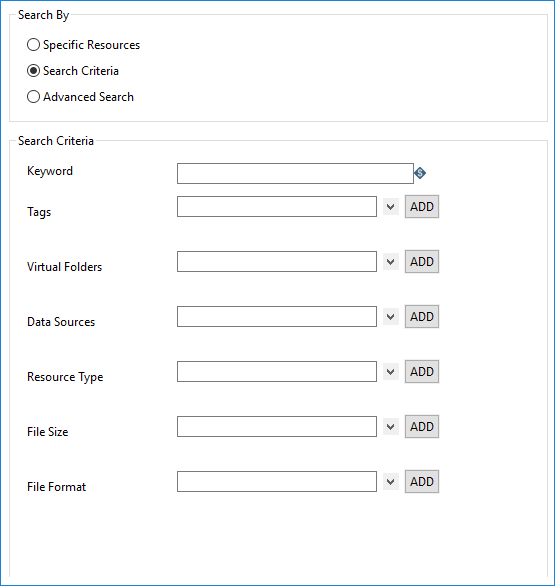
| Field | Description |
| Keyword | Enter a keyword to use for the search. |
| Tags | Select a tag or tags to search for using the drop-down menu. |
| Virtual Folders | Select a virtual folder to search using the drop-down menu.
NoteIf missing or incomplete data is returned, you can use Advanced Search or you may need to change the default limit for returned results. See Lumada Data Catalog searches returning incomplete or missing data for information.
|
| Data Sources | Select a data source to search using the drop-down menu.
NoteIf missing or incomplete data is returned, you can use Advanced Search or you may need to change the default limit for returned results. See Lumada Data Catalog searches returning incomplete or missing data for information.
|
| Resource Type | Select a resource type to search using the drop-down menu.
NoteIf missing or incomplete data is returned, you can use Advanced Search or you may need to change the default limit for returned results. See Lumada Data Catalog searches returning incomplete or missing data for information.
|
| Files Size | Select a file size range to search using the drop-down menu. |
| File Format | Select a specific file format to search for using the drop-down menu. Note that CSV or Parquet file formats are currently supported. |
Select Advanced Search to search using a JSON string. For more information, see Lumada Data Catalog REST API. The search filters all the results by the query parameters.
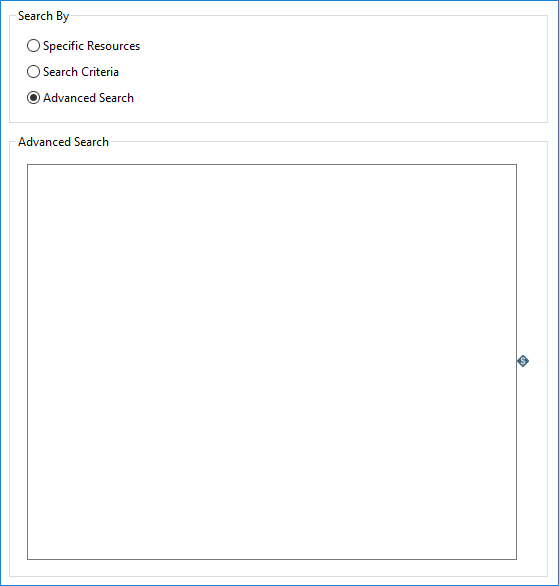
| Field | Description |
| Advanced Search | Enter a JSON string of API-specific query parameters to run against Data Catalog. |
Fields tab
In the Fields tab, you can define properties for the fields of the data type being read.
See Understanding PDI data types and field metadata to maximize the efficiency of your transformation and job results.
CSV fields
When CSV data is read, the table defines the fields to read as input from the CSV file.
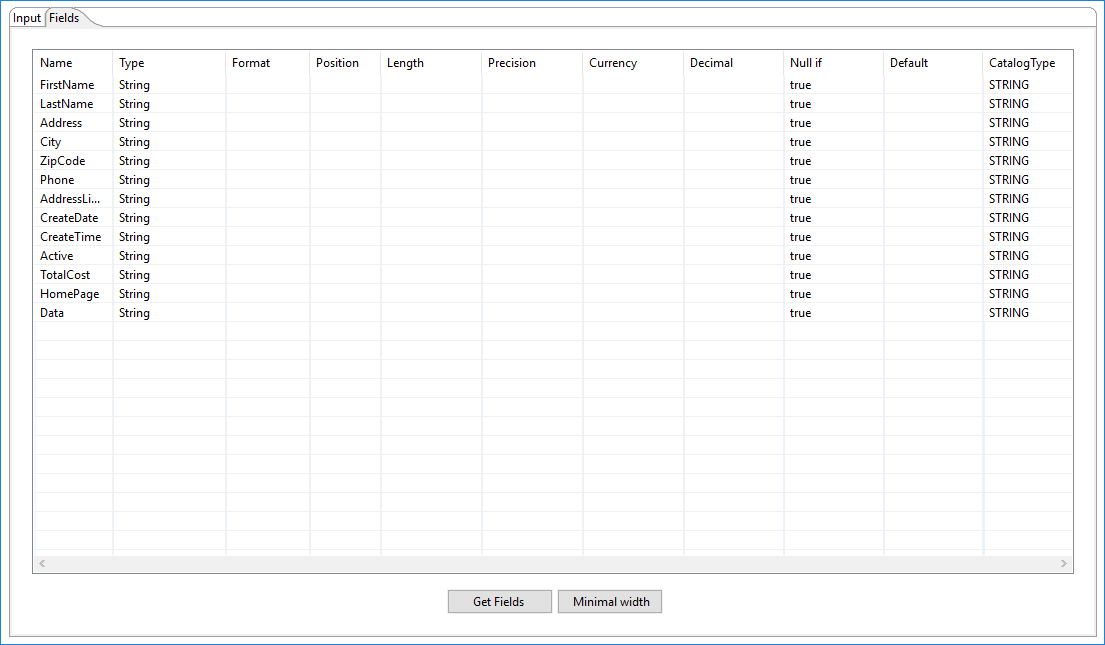
Enter the information for the Catalog Input step fields as shown in the following table.
| Column | Description |
| Name | The name of the field. |
| Type | The data type of the field. |
| Format | Enter the number format. See Number formats for a description of format symbols. |
| Position | The position is needed when processing the 'Fixed' Filetype. It is zero based, so the first character starts with position ‘0’. |
| Length |
The value of this field depends on the format:
|
| Precision |
The value of this field depends on the format:
|
| Currency | Used to interpret the symbol used to represent currencies (for example, $ or €). |
| Decimal | Used to represent a decimal point, either a dot '.' or a comma ',' (for example, 5,000.00 or 5.000,00). |
| Null if | Used to set as null (empty) if the string is equal to the specified value. |
| Default | Used to specify a default value to use in case the field in the CSV file was not specified (empty). |
| CatalogType | The data type as defined in Data Catalog. For example, UTF8. |
| Get Fields (button) | Click to retrieve a list of fields derived from the source file in Data Catalog. |
| Minimal width (button) | Click to minimize the field length by removing unnecessary characters. If selected, string fields will no longer be padded to their specified length. |
Parquet fields
When Parquet data is read, the table defines the fields to read as input from the Parquet file.
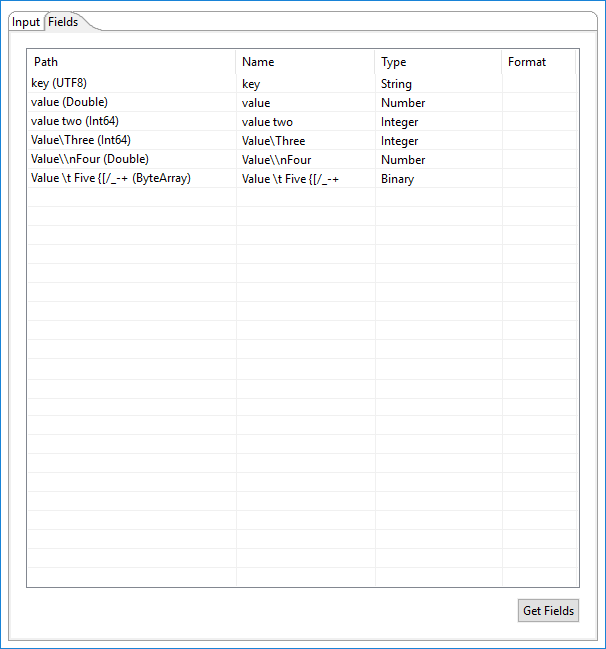
Enter the information for the Catalog Input step fields, as shown in the following table.
| Column | Description |
| Path | The name of the field as it appears in the Parquet data file, and the Parquet data type. An associated PDI field type is provided in parentheses. |
| Name | The name of the input field. |
| Type | The type of the input field as detected by PDI. |
| Format | Specify the Date formats when the Type specified is Date. |
| Get Fields (button) | Click to retrieve a list of fields derived from the source file in Data Catalog. |
Provide a path to a Parquet data file and click Get Fields. When the fields are retrieved, the Parquet type is converted to an applicable PDI type, as shown in the PDI types table. You can change the type by using the Type drop-down menu or by entering the type manually.
PDI types
The Parquet to PDI data type values are as shown in the table below:
| Parquet Type | PDI Type |
| ByteArray | Binary |
| Boolean | Boolean |
| Double | Number |
| Float | Number |
| FixedLengthByteArray | Binary |
| Decimal | BigNumber |
| Date | Date |
| Enum | String |
| Int8 | Integer |
| Int16 | Integer |
| Int32 | Integer |
| Int64 | Integer |
| Int96 | Timestamp |
| UInt8 | Integer |
| UInt16 | Integer |
| UInt32 | Integer |
| UInt64 | Integer |
| UTF8 | String |
| TimeMillis | Timestamp |
| TimestampMillis | Timestamp |