Bulk load into Azure SQL DB
You can execute a job to bulk load into Azure SQL DB.
Use the Bulk load into Azure SQL DB job entry to load data into an Azure SQL database from Azure Data Lake Storage. The Bulk load into Azure SQL DB only supports CSV format data. See Azure SQL documentation.
Before you begin
Before using the Bulk load into Azure SQL DB job entry in PDI, you must have the following items:
- An Azure account.
- A connection to the Azure SQL database in which to load your data. For more information, see Connect to an Azure SQL database.
- A VFS connection to Azure Data Lake Storage.
- A table and schema set up in the database where you want to place your data. The table must have defined all the columns you need. On the first use, you need to create the table.
General
The following field is general to this job entry:
- Entry Name: Specify the unique name of the job entry on the canvas. You can customize the name or leave it as the default.
Options
The Bulk load into Azure SQL DB entry includes four tabs to define the data input source, the output database and location, options, and advanced options for loading PDI data into an Azure SQL database. Each tab is described below.
Input tab
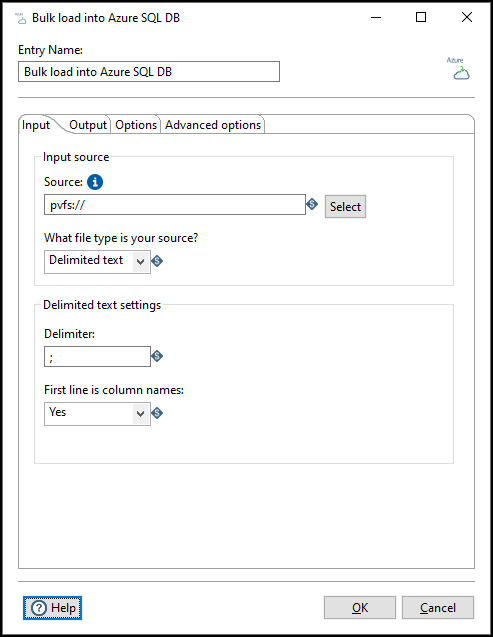
Use the options in this tab to define your input source for the Azure SQL database:
| Option | Description |
| Source | Specify the VFS URL of the data to import. The URL can point to a file or a folder in Azure Data Lake Storage. The URL must begin with pvfs:// and must specify
the bucket and object you want to load. See Pentaho address to a VFS connection . |
| What file type is your source? | Select the file type of the input source. Must be a CSV file. |
|
Delimited text settings |
Specify the following settings for a delimited text file:
|
Output tab
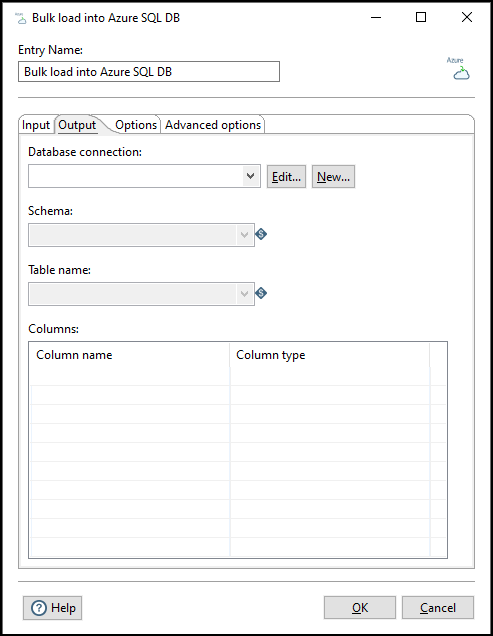
Enter the following information on the Output tab to specify the output destination of the source data:
| Option | Description |
| Database connection |
Select your database connection from a list of existing Azure SQL DB connections. If you do not have an existing connection, click New. If you need to modify an existing connection, click Edit. |
| Schema | Select the schema to use for the bulk load. The Bulk load into Azure SQL DB entry reads the schemas that exist in the database to populate this list. |
| Table name | Select the name of the table to bulk load. The Bulk load into Azure SQL DB entry reads the table names from your selected schema to populate this list. |
| Columns | Preview of the column names and associated data types within your selected table. |
Options tab
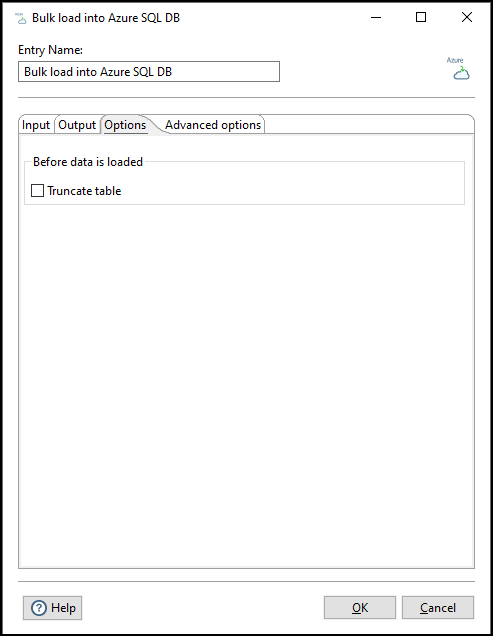
Enter the following information on the Options tab to define how the data is loaded into the destination table:
| Option | Description |
| Truncate table | Select to remove all the data in the table before bulk loading the current data. Clear to append data during a new data load (default). |
Advanced options tab
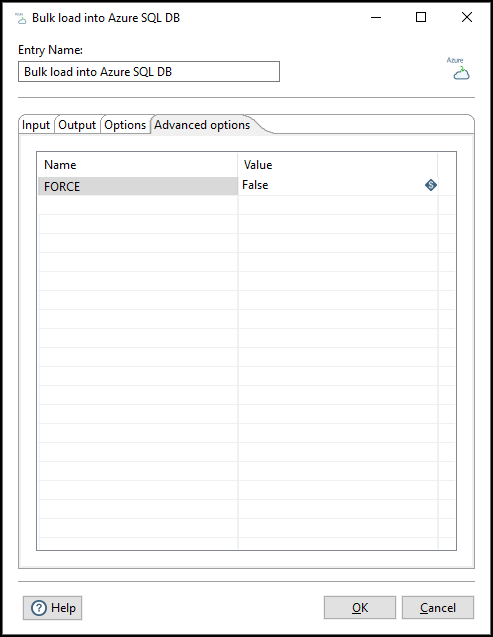
Use this tab to configure parameters for the Bulk load into Azure SQL DB. Any Name/Value pair added as a parameter is
passed to the Azure SQL database as a parameter, but the validation of the parameter is the user’s responsibility. See the Azure SQL documentation for further details on these parameters. The Force parameter here is provided as an example.
| Option | Description |
| Force |
Specify whether to force loading of files into a database:
|