Amazon EMR Job Executor

The Amazon EMR Job Executor entry runs Hadoop jobs in the Amazon Elastic MapReduce (EMR) tool. You can use this entry to access the job flows in your Amazon Web Services (AWS) account.
Before you begin
You must have an AWS account configured for EMR to use this entry, and a Java JAR created to control the remote job.
General
Enter the following information in the job entry field:
- Entry name: Specifies the unique name of the Amazon EMR Job Executor entry on the canvas. You can customize the name or leave it as the default.
Options
The Amazon EMR Job Executor entry features tabs for EMR and job settings. Each tab is described below.
EMR settings tab
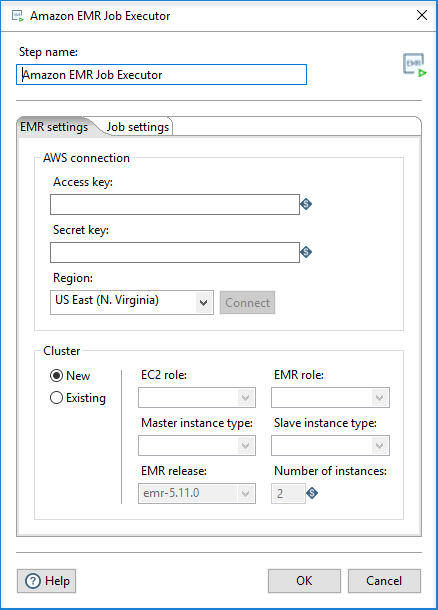
This tab includes options for connecting to your AWS account and cluster.
AWS connection
Use the following options to specify your AWS account:
| Option | Description |
| Access key | Specify the unique identifier for your account. Your Access key combined with your Secret key are used to sign AWS requests. A signed request identifies the sender and prevents the request from being altered. |
| Secret key | Specify the encoded key generated from either your AWS account, individual Identity and Access Management (IAM) users, or temporary sessions. Your Secret key combined with your Access key are used to sign AWS requests. A signed request identifies the sender and prevents the request from being altered. |
| Region | Select which isolated Amazon Elastic Compute Cloud (EC2) geographical area you want use to execute your job flow. The regions available in this list depend on your AWS account. See https://docs.aws.amazon.com/AWSEC2/l...lability-zones for more information. |
Click Connect to establish the connection.
Cluster
Select New if you want to create a new job flow (cluster), or Existing if you already have a job flow ID. Your job flow specifies all the functions you are trying to apply to your data. The ID identifies the job flow.
If you select New, use the following options to generate a new job flow:
| Option | Description |
| EC2 role | Select the Amazon EC2 instance of the EMR role within your cluster. The processes that run on cluster instances use this role when they call other AWS services. The instances available in this list depend on your AWS account. |
| EMR role | Select the role that permits Amazon EMR to call other AWS services such as Amazon EC2 on your behalf. See https://docs.aws.amazon.com/emr/late...iam-roles.html for more information. The roles available in this list depend on your AWS account. |
| Master instance type | Select the Amazon EC2 instance type that will act as the Hadoop master in the cluster. This type will handle MapReduce task distribution. |
| Slave instance type | Select the Amazon EC2 instance type that will act as one or more Hadoop slaves in the cluster. Slaves are assigned tasks from the master. This setup is only valid if the number of instances is greater than 1. |
| EMR release | Select the EMR Hadoop cluster release version, which defines the set of service components and their versions. |
| Number of instances | Specify the number of EC2 instances you want to assign to this job. |
If you select Existing, specify the existing ID through the Existing JobFlow ID option.
Job settings tab
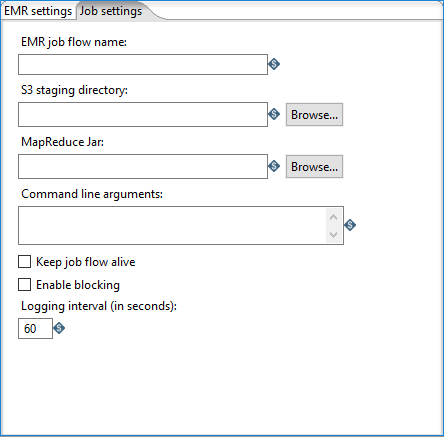
This tab includes the following options:
| Option | Description |
| EMR job flow name | Specify the name of the Amazon EMR job flow to execute. |
| S3 staging directory | Specify the Amazon Simple Storage Service (S3) address of the working directory for this Hadoop job. This directory will contain the MapReduce JAR and log files. |
| MapReduce Jar | Specify the address of the Java JAR that contains your Hadoop mapper and reducer classes. The job must be configured and submitted using a static main method in any class of the JAR. |
| Command line arguments | Enter in any command line arguments you want to pass into the static main method of the specified MapReduce Jar. Use spaces to separate multiple arguments. |
| Keep job flow alive | Select if you want to keep your job flow active after the PDI entry finishes. If this option is not selected, the job flow will terminate when the PDI entry finishes. |
| Enable blocking |
Select if you want to force the job to wait until each PDI entry completes before continuing to the next entry. Blocking is the only way for PDI to be aware of the status of a Hadoop job. Additionally, selecting this option enables proper error handling and routing. When you clear this option, the Hadoop job is blindly executed and PDI moves on to the next entry. |
| Logging interval | If you Enable blocking, specify the number of seconds between status log messages. |