Using the Hadoop File Output step on the Spark engine

You can set up the Hadoop File Output step to run on the Spark engine. Spark processes null values differently than the Pentaho engine, so you may need to adjust your transformation to process null values following Spark's processing rules.
General
Enter the following information in the transformation step name field.
- Step Name: Specifies the unique name of the Hadoop File Output step on the canvas. You can customize the name or leave it as the default
Options
The Hadoop File Output transformation step features several tabs with fields. Each tab is described below.
File tab
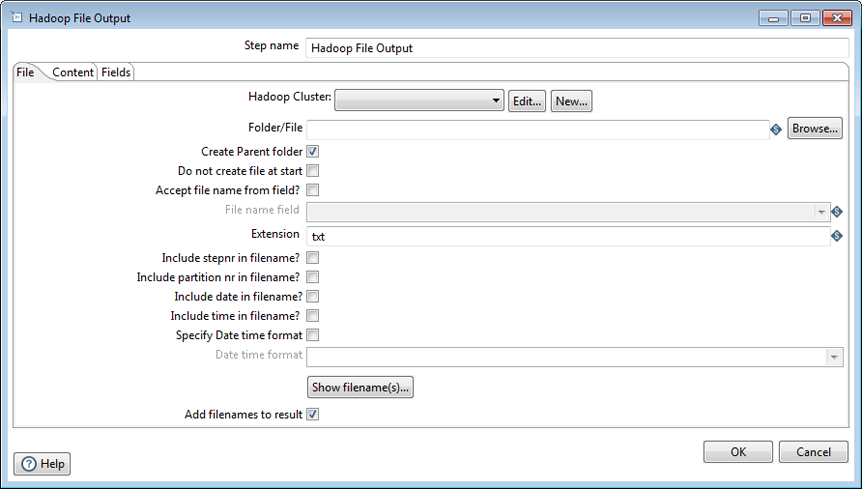
The File tab contains the following options that define the basic properties for the file being created:
| Option | Description |
| Hadoop Cluster |
Specify which Hadoop cluster configuration to use. The environment must match the Spark cluster. You can specify information like host names and ports for HDFS, Job Tracker, and other big data cluster components through the Hadoop Cluster configuration dialog box. Click Edit to edit an existing cluster configuration in the dialog box, or click New to create a new configuration with the dialog box. Once created, Hadoop cluster configurations settings can be reused by other transformation steps and job entries. See Connecting to a Hadoop cluster with the PDI client for more details on the configuration settings. |
| Folder/File | Specify the location and/or name of the output text file written to the Hadoop Cluster. Click Browse to navigate to the source file or folder in the VFS browser. |
| Create Parent Folder | Indicate if a parent folder should be created for the output text file. |
| Do not create file at start | This field is either not used by the Spark engine or not implemented for Spark on AEL. |
| Accept file name from field? | This field is either not used by the Spark engine or not implemented for Spark on AEL. |
| File name field | This field is either not used by the Spark engine or not implemented for Spark on AEL. |
| Extension | Adds the .csv extension to the end of the file name. |
| Include stepnr in filename | This field is either not used by the Spark engine or not implemented for Spark on AEL. |
| Include partition nr in file name? | This field is either not used by the Spark engine or not implemented for Spark on AEL. |
| Include date in file name | Include the system date in the filename (_20181231 for example). |
| Include time in file name | Include the system time in the filename (_235959 for example). |
| Specify Date time format | Indicate if you want to specify the date time format from the list in the Date time format drop-down list. |
| Date time format | Specify date time formats. |
| Show file name(s) | Display a list of the files generated. The list is a simulation and depends on the number of rows that go into each file. |
| Add filenames to result | This field is either not used by the Spark engine or not implemented for Spark on AEL. |
Content tab
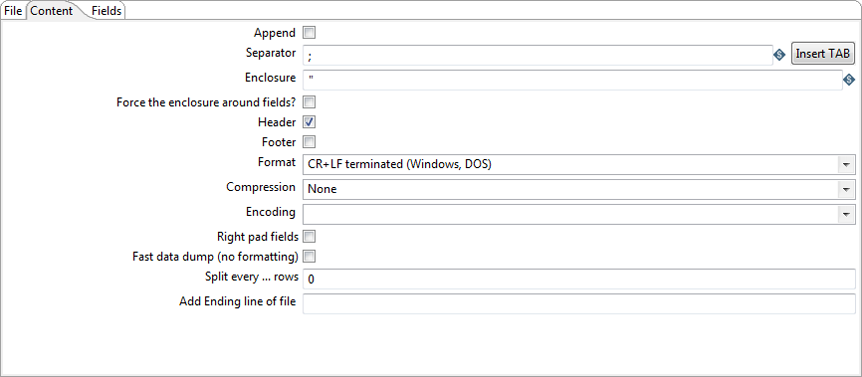
The Content tab contains the following options for describing the content written to the output text file:
| Option | Description |
| Append | Append lines to the end of the specified file. |
| Separator | Specify the character that separates the fields in a single line of text. Typically, it is a semicolon (;) or a tab. Click Insert TAB to place a tab in the Separator field. |
| Enclosure | Specify to enclose fields with a pair of specified strings. It allows for separator characters in fields. This setting is optional and can be left blank. The default value is double quotes (") |
| Force the enclosure around fields? | Specify to force all field names to be enclosed with the character specified in the Enclosure option. |
| Header | Indicate if the output text file has a header row (first line in the file). |
| Footer | This field is either not used by the Spark engine or not implemented for Spark on AEL. |
| Format | On the Spark engine, specify the UNIX format. UNIX files have lines separated by line feeds. |
| Compression | This field is either not used by the Spark engine or not implemented for Spark on AEL. |
| Encoding | This field is either not used by the Spark engine or not implemented for Spark on AEL. |
| Right pad fields | This option is supported on the Spark engine when you select the Minimal width button on the Fields tab. |
| Fast data dump (no formatting) | On the Spark engine, select this option if for fixed length file types. |
| Split every ... rows | This field is either not used by the Spark engine or not implemented for Spark on AEL. |
| Add Ending line of file | This field is either not used by the Spark engine or not implemented for Spark on AEL. |
Fields tab
The Fields tab is where you define properties for the fields being exported. The following table describes each field:
| Field | Description |
| Name | The name of the field |
| Type | Type of the field can be either String, Date or Number. |
| Format | An optional mask for converting the format of the original field. |
| Length |
The length of the field depends on the following field types:
|
| Precision | Number of floating point digits for number-type fields. |
| Currency | Symbol used to represent currencies ($5,000.00 or €5.000,00 for example). |
| Decimal | A decimal point can be a period (.) as in 10,000.00 or it can be a comma (,) as in 5.000,00. |
| Group | A grouping can be a comma (,) as in 10,000.00 or it can be a period (.) as in 5.000,00. |
| Trim Type | The trimming method to apply to a string. Trimming only works when no field length is specified. |
| Null | If the value of the field is null, the specified string is inserted into the output text file. |
Metadata injection support
All fields of this step support metadata injection except for the Hadoop Cluster field. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.