Using the Group By step on the Spark engine

You can set up the Group By step to run on the Spark engine.
When Spark is processing the transformation, the rows are sorted by the group fields. The field names cannot contain spaces, dashes, or special characters. Each field name must start with a letter.
Optionally, you can use the Sort step before the Group By step. If your existing transformations contains a Sort step before the Group By step, it will run successfully.
General
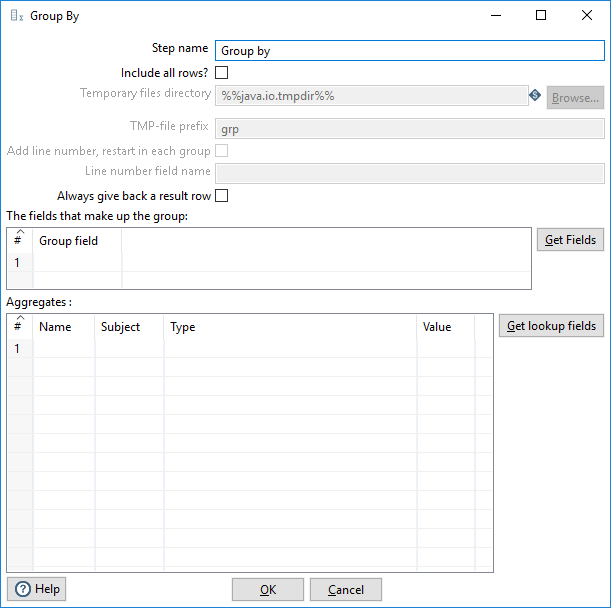
Enter the information in the options as shown in the following table:
| Option | Description |
| Step name | Specifies the unique name of the Group By step on the canvas. You can customize the name or leave it as the default. |
| Include all rows? |
Select this check box if you want to include all rows in the output. Clear this check box if you only want to output the aggregate rows. The following conditions apply if you select Include all rows while using the Spark engine:
The following options are not available unless the Include all rows option is selected:
|
| Temporary files directory | This field is either not used by the Spark engine or not implemented for Spark on AEL. Temporary files are not created when run with Spark. |
| TMP-file prefix | This field is either not used by the Spark engine or not implemented for Spark on AEL. |
| Add line number, restart in each group | Adds a line number that restarts at 1 in each group. When both Include all rows and this option are selected, all rows are included in the output with a line number for each row. |
| Line number field name | Specifies the name of the field where you want to add line numbers for each new group. |
| Always give back a result row | Select this check box to return a result row, even when there is no input row. When there are no input rows, this option returns a count of zero (0). Clear this check box if you only want to output a result row when there is an input row. |
The fields that make up the group table
Use The fields that make up the group table to specify the fields you want to group. Click Get Fields to add all fields from the input stream(s) to the table.
The field names cannot contain spaces, dashes, or special characters, and must start with a letter. The rows are sorted by the grouping fields. Right-click a row in the table to edit that row or all rows in the table.
Aggregates table
The Aggregates table specifies the group you want to aggregate, the aggregation method, and the name of the resulting new field.
The Aggregates table contains the following columns:
| Column | Description |
| Name | The name of the aggregate field. The field name cannot contain spaces, dashes, or special characters, and must start with a letter. |
| Subject | The subject on which you want to use an aggregation method. |
| Type |
The aggregate method. The aggregation methods are:
|
| Value | The aggregate value. |
Examples
Examples included in the design-tools\data-integration\samples\transformations directory are:
- Calculate median and percentiles using the group by steps.ktr
- General - Repeat fields - Group by - Denormalize.ktr
- Group By - Calculate standard deviation.ktr
- Group By - include all rows without a grouping.ktr
- Group by - include all rows and calculations .ktr.
Metadata Injection Support
All fields of this step support metadata injection. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.
The metadata injection values for the aggregation type are:
- SUM
- AVERAGE
- MEDIAN
- PERCENTILE
- MIN
- MAX
- COUNT_ALL
- CONCAT_COMMA
- FIRST
- LAST
- FIRST_INCL_NULL
- LAST_INCL_NULL
- CUM_SUM
- CUM_AVG
- STD_DEV
- CONCAT_STRING
- COUNT_DISTINCT
- COUNT_ANY