Using the Avro Output step on the Spark engine

You can set up the Avro Output step to run on the Spark engine. Spark processes null values differently than the Pentaho engine, so you may need to adjust your transformation to successfully process null values according to Spark's processing rules.
General
Enter the following information in the transformation step fields:
| Field | Description |
| Step name | Specify the unique name of the Avro Output step on the canvas. You can customize the name or leave it as the default. |
| Folder/File name |
Specify the location and name of the file or folder. You can also click Browse to navigate to the destination file or folder through your VFS connection. See Connecting to Virtual File Systems for more information. A folder is created with Avro files. |
| Overwrite existing output file | Select to overwrite an existing file that has the same file name and extension. |
Options
The Avro Output transformation step features several tabs with fields. Each tab is described below.
Fields tab
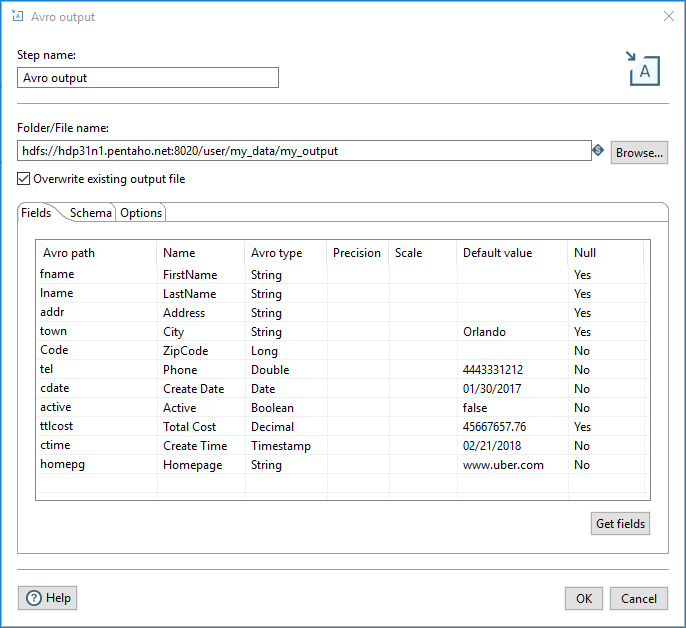
| Field | Description |
| Avro path | The name of the field as it will appear in the Avro data and schema files. |
| Name | The name of the PDI field. |
| Avro type | Defines the Avro data type of the field. |
| Precision | Applies only to the Decimal Avro type, the total number of digits in the number. The default is 10. |
| Scale | Applies only to the Decimal Avro type, the number of digits after the decimal point. The default is 0. |
| Default value | The default value of the field if it is null or empty. |
| Null | Specify if the field can contain null values. |
| PDI Type | Avro Type |
| InetAddress | String |
| String | String |
| TimeStamp | Long |
| Binary | Bytes |
| BigNumber |
Not supported NoteDecimal types are not supported
when running a transformation in AEL, so you must convert the field to another
appropriate Avro type.
|
| Boolean | Boolean |
| Date | Integer |
| Integer | Long |
| Number | Double |
Schema tab
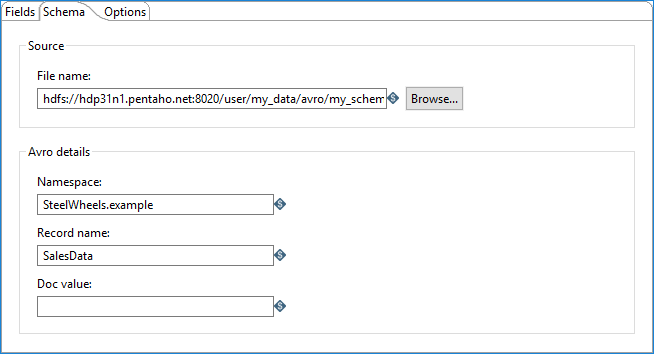
The following options in the Schema tab define how the Avro schema file will be created:
| Option | Description |
| File name | Specify the fully qualified URL where the Avro schema file will be written. The URL may be in a different format depending on file system type. You can also click Browse to navigate to the schema file on your file system. If a schema file already exists, it will be overwritten. If you do not specify a separate schema file for your output, PDI will write an embedded schema in your Avro data file. |
| Namespace | Specify the name, together with the Record name field, that defines the "full name" of the schema (example.avro for example). |
| Record name | Specify the name of the Avro record (User for example). |
| Doc value | Specify the documentation provided for the schema. |
Options tab
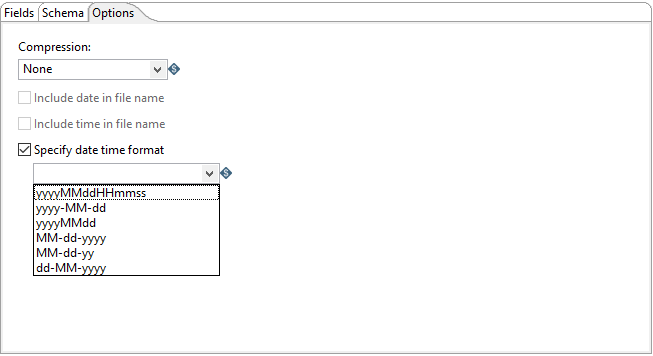
| Option | Description |
| Compression |
Specify which of the following codecs is used to compress data blocks in the Avro output file:
See https://avro.apache.org/docs/1.8.1/spec.html#Object+Container+Files for additional information on these codecs. |
| Include date in filename | Add the system date that the file was generated to the output file name with the default format yyyyMMdd (20181231 for example). |
| Include time in filename | Add the system time that the file was generated to the output file name with the default format HHmmss (235959 for example). |
| Specify date time format | Add a different date time format to the output file name from the options available in the drop-down list. |
Metadata injection support
All fields of this step support metadata injection. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.