SSTable Output

The SSTable Output step writes to a filesystem directory as an Apache Cassandra SSTable using CQL (Cassandra Query Language) version 3.x.
NoteThis step supports Cassandra 2.2 and later.
AEL considerations
When using the SSTable Output step with the Adaptive Execution Layer, the following factor affects performance and results:
- Spark processes null values differently than the Pentaho engine. You will need to adjust your transformation to successfully process null values according to Spark's processing rules.
Options
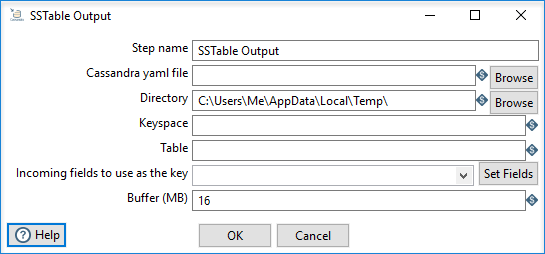
The following options are available for the SSTable Output transformation step.
| Option | Description |
| Step name | Specify the unique name of the SSTable Output step on the canvas. You can customize the name or leave it as the default. |
| Cassandra yaml file | Specify the location of YAML file. A cassandra.yaml file is the main configuration file for Cassandra. It defines node and cluster configuration details. |
| Directory | Specify where to write the output. This directory points to the target table to load to and must match the Keyspace and Table fields. |
| Keyspace | Specify the keyspace (database) name of the target table to load. The name specified must match the Directory field. |
| Table | Specifies the table (column family) to upload. It assumes the metadata for this table was previously defined in Cassandra. The table specified must match the Directory field. |
| Incoming fields to use as the key | Specify which incoming row to use as the key. You can use Set Fields to specify the key from the names of incoming PDI transformation fields. |
| Set Fields | Select from a list of incoming PDI transformation fields to specify as the Incoming fields to use as the key. |
| Buffer (MB) | Specify buffer size to use. A new table file is written every time the buffer is full. |