Regex Evaluation

The Regex evaluation step matches the strings of an input field against a text pattern you define with a regular expression (regex). This step uses the java.util.regex package. The syntax for creating the regular expressions used by this step is defined in the java.util.regex.Pattern javadoc.
You can use this step to parse a complex string of text and create new fields out of the input field with capture groups (defined by parentheses). For example, if you have an input field containing an author's name in quotes and the number of posts made by them, you can create two new fields in your transformation - one for the name, and one for the number of posts as shown below:
Text to parse:
"Author, Ann" - 53 posts
Regex to create two capture groups:
^"([^"]*)" - (\d*) posts$
The resulting field values are: Ann and 53.
General
Enter the following information in the transformation step field:
- Step name: Specifies the unique name of the Regex evaluation step on the canvas. You can customize the name or leave it as the default.
Capture Group Fields table
Use the Capture Group Fields table to specify the new fields for the substrings captured by the regular expression from the input string.
| Column | Description |
| New field | Name of the new field generated from the regular expression. |
| Type | Type of data. |
| Length | Length of the field. |
| Precision | Number of floating point digits for number-type fields. |
| Format | An optional mask for converting the format of the original field. See Common Formats for information on common valid date and numeric formats you can use in this step. |
| Group | A grouping can be a "," (10,000.00 for example) or "." (5.000,00 for example) |
| Decimal | The character used as a decimal point. |
| Currency | Currency symbol ($ or € for example) |
| Null If | Treat this value as null. |
| Default | Default value when the field in the incoming file is not specified (empty). |
| Trim | The trim method to apply to a string. |
See Understanding PDI data types and field metadata to maximize the efficiency of your transformation and job results.
Options
This step features several tabs with fields. Each tab is described below.
Settings tab
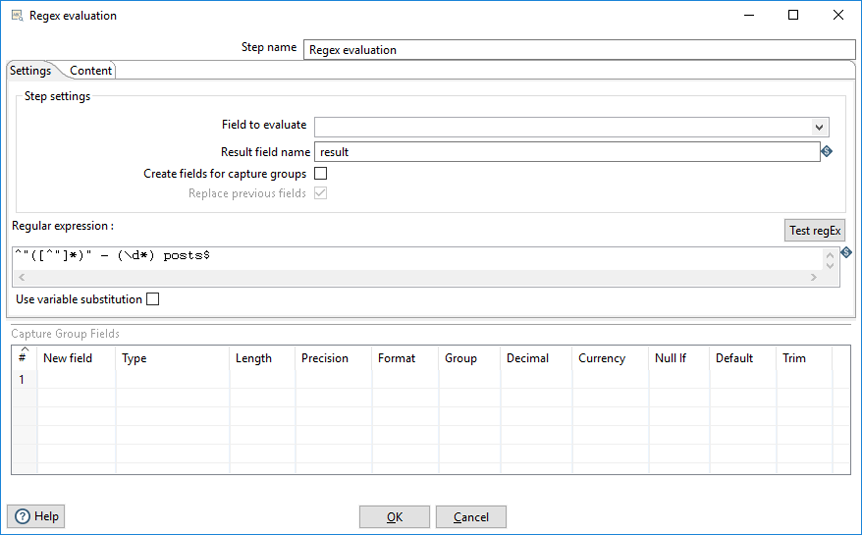
The Settings tab contains the following options:
| Option | Description |
| Field to evaluate | Specify the name of the field from the incoming PDI stream to be matched against the regular expression. |
| Result field name | Specify the name of the output field. This field is added to the outgoing PDI stream and has a value of Y to indicate the value of the input field matched the regular expression or N to indicate it did not match. |
| Create fields for capture groups | Select to create new fields based on capture groups, in the regular expression. When this option is selected, substrings in the captured groups are extracted and stored in new output fields, that you specify in the Capture Group Fields table. Each capture group must have a field defined in the Capture Group Fields table. The order of the fields in the table must be the same as the order of the capturing groups in the regular expression. You can change the data type using the columns in the table. |
| Replace previous fields | Select to replace fields from the incoming PDI stream with fields created for the capture group field names, if the fields have the same name. If this option is clear, new fields are added to the outgoing PDI stream for each capturing group field. This option is available when you select the Create fields for capture groups option. |
| Regular expression | Specify your regular expression. Click Test regEx to open the Regular expression evaluation window. |
| Use variable substitution | Select to expand variable references to their values before evaluating the regular expression pattern. |
Regular expression evaluation window
You can test your regular expression against three different input strings using the following Regular expression evaluation window:
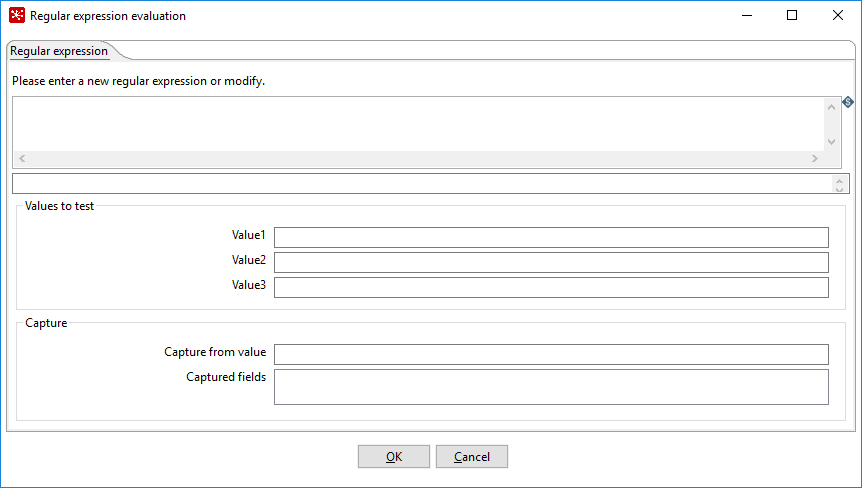
If your expression contains a group field, type a string in the Compare section and the option below the string will be split according to your group(s).
The window contains the following options:
| Field | Description |
| Please enter a new regular expression or modify | Specify your regular expression. |
| Values to test | Specify the values (Value1, Value2, or Value3) to test your string. The background will turn green if that value is a match against your expression or red if it does not. |
| Capture from value | Displays the value of the captured string. |
| Captured fields | Displays the value of the captured groups. |
Content tab
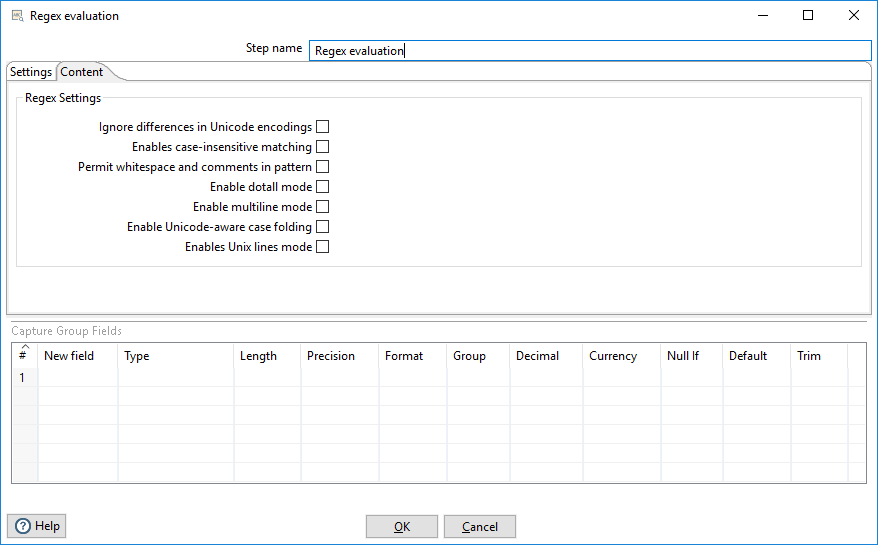
The Content tab contains the following options:
| Option | Description |
| Ignore differences in Unicode encodings | Select to ignore different Unicode character encodings. This action may improve performance, but your data can only contain US ASCII characters. |
| Enables case-insensitive matching | Select to use case-insensitive matching. Only characters in the US-ASCII
charset are matched. Unicode-aware case-insensitive matching can be enabled by
specifying the 'Unicode-aware case...' flag in conjunction with this flag. The
execution flag is ( |
| Permit whitespace and comments in pattern | Select to ignore whitespace and embedded comments starting with # through the
end of the line. In this mode, you must use the \s token to match whitespace. If
this option is not enabled, whitespace characters appearing in the regular
expression are matched as-is. The execution flag is
( |
| Enable dotall mode | Select to include line terminators with the dot character expression
match. The execution flag is ( |
| Enable multiline mode | Select to match the start of a line '^' or the end of a line
'$' of the input sequence. By default, these expressions only
match at the beginning and the end of the entire input sequence.The execution
flag is( |
| Enable Unicode-aware case folding | Select this option in conjunction with the Enables case-insensitive
matching option to perform case-insensitive matching consistent with
the Unicode standard. The execution flag is ( |
| Enables Unix lines mode | Select to only recognize the line terminator in the behavior of
'.', '^', and '$'.\The
execution flag is ( |
Examples
Suppose your input field contains a text value like "Author, Ann" - 53 posts. The following regular expression creates four capturing groups and can be used to parse out the different parts:
^"((["]), (["]))" - (\d+) posts\.$
This expression creates the following four capturing groups, which become output fields:
- Fullname:
((["]), (["])) - Lastname:
([^"]+) - Firstname:
([^"]+) - Number of posts:
(\d+)
In this example, a field definition must be present for each of these capturing groups.
If the number of capture groups in the regular expression does not match the number of fields specified, the step will fail and an error is written to the log. Capturing groups can be nested. In the example above the fields Lastname and Firstname correspond to the capturing groups that are themselves contained inside the Fullname capturing group.
The design-tools/data-integration/samples/transformations directory contains the samples/transformations/Regex Eval - parse NCSA access log records.ktr as another example on how to use this step.