Hadoop Copy Files

This job entry copies files in a Hadoop cluster from one location to another.
General
Enter the following information in the job entry field:
- Job Name: Specify the unique name of the Hadoop Copy Files entry on the canvas. You can customize the name or leave it as the default.
Options
The Hadoop Copy Files job entry features two tabs with fields. Each tab is described below.
Files/Folders tab
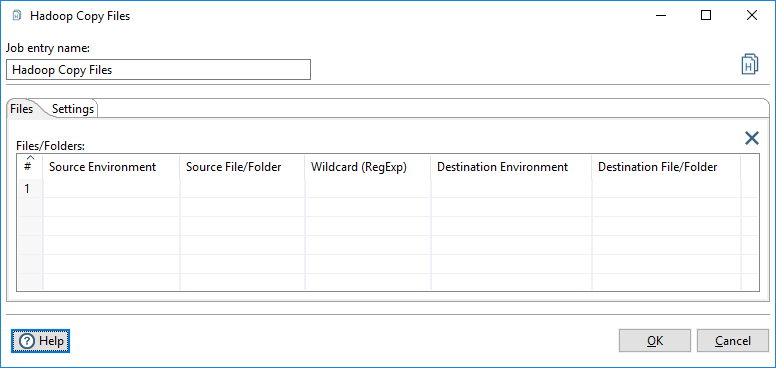
| Option | Description |
| Source Environment | Specify the type of file system containing the files you want to copy. |
| Source File/Folder | Specify the file or directory you want to copy. Click Browse to to navigate to the source file or folder through the VFS browser. See VFS browser for more information. |
| Wildcard (RegExp) | Specify the files to copy with regular expressions instead of static file names. For example, .*\.txt selects all files with a .txt extension. |
| Destination Environment | Specify the file system where you want to put your copied files. |
| Destination File/Folder | Specify the file or directory where you want to place your copied file. Click Browse and select Hadoop to enter your Hadoop cluster connection details. |
NoteThe source environment and destination environments must be the same.
Settings tab

| Option | Description |
| Include subfolders | Select to copy all subdirectories in the chosen directory. |
| Destination is a file | Select to specify the destination is a file. |
| Copy empty folders | Select to copy empty directories. The Include Subfolders option must be selected for this option to be valid. |
| Create destination folder | Select to create the specified destination directory if it does not exist. |
| Replace existing files | Select to overwrite duplicate files in the destination directory. |
| Remove source files | Select to remove the source files after copying them. This is equivalent to a move procedure. |
| Copy previous results to arguments | Select to use previous step results as your sources and destinations. |
| Add files to result files name | Select to create a list of files that were copied in this step. |
If you are not using Kerberos security, this step sends the username of the logged-in user when copying the files regardless of the username entered in the connect field. To change the username, set the environment variable HADOOP_USER_NAME to the username you want to use. You can set the username by changing the OPT variable in the spoon.bat or spoon.sh file as shown in the following example:
OPT="$OPT .... -DHADOOP_USER_NAME=HadoopNameToSpoof"