Configuring application tuning parameters for Spark

Spark tuning is the customization of PDI transformation and step parameters to improve the performance of your PDI transformation executed on the Spark engine. These Spark parameters include both the AEL properties and PDI transformation parameters, which we call application tuning parameters, and the step-level parameters, which we call Spark tuning options, as described in About Spark tuning in PDI.
This article provides a reference for application tuning, including configuring AEL properties and PDI transformation parameters to meet your cluster size and resource requirements. For details regarding step-level Spark tuning options, see Spark Tuning.
Audience and prerequisites
These setup tasks are intended for two different audiences. Application tuning tasks that use AEL properties are intended for cluster administrators who manage the cluster nodes and the applications on each node for the Spark engine. Alternately, application tuning tasks that use PDI transformation parameters are intended for ETL developers who have permissions to read, write, and execute commands on the Spark cluster.
To configure the application tuning parameters, you need the following information:
- The processing model for the Spark engine in PDI, as described in Executing on the Spark engine.
- Available cluster resources.
- Size of the data.
- Amount of resources available to the Spark application during execution, including memory allotments and number of cores.
- Access to the YARN ResourceManager to monitor cluster resources.
- Access to the Spark execution resources on the Spark History Server.
Spark tuning process
The following property and parameter configurations are part of a Spark tuning strategy that follows a three-step approach:
- Set the Spark parameters globally. Use the AEL properties file to set the application tuning parameters. These parameters are deployed on the cluster or the Pentaho Server, and act as a baseline for all transformations and users.
- Set the Spark parameters locally in PDI. When running a transformation in PDI, you can override the global application tuning parameters. These settings are specific to the user and the transformation run.
- Set Spark tuning options on a PDI step. Open the Spark tuning parameters for a step in a transformation to further fine tune how your transformation runs.
Application tuning parameters for Spark
Application tuning parameters use the spark. prefix and are
passed directly to the Spark cluster for configuration. Pentaho offers full support of Spark properties. See the Spark properties documentation for a full list.
Available application tuning parameters for Spark may depend on your deployment or cluster management. All the Spark parameters in PDI support the use of variables. The following table lists the Spark parameters available in PDI. See the Spark properties documentation for full descriptions, default values, and recommendations.
| Spark | Parameter Value | Description |
| spark.executor.instances | Integer | The number of executors for the Spark application. |
| spark.executor.memoryOverhead | Integer | The amount of off-heap memory to be allocated per executor. |
| spark.executor.memory | Integer | The amount of memory to use per executor process. |
| spark.driver.memoryOverhead | Integer | The amount of off-heap memory to be allocated per driver in cluster mode. |
| spark.driver.memory | Integer | The amount of memory to use for the driver process. |
| spark.executor.cores | Integer | The number of cores to use on each executor. |
| spark.driver.cores | Integer | The number of cores to use for the driver process in cluster mode. |
| spark.default.parallelism | Integer | The default number of partitions in RDDs returned by transformations, such as join, reduceByKey, and parallelize when not set by user. |
If an identical property is set in a user's transformation, it overrides the setting on the cluster or Pentaho Server.
spark. prefix and are executed on the Spark
cluster as applications without affecting the cluster configuration. See Setting PDI step Spark tuning options for details.Set the Spark parameters globally
Spark tuning may be affected by the following factors:
- When a Hadoop or a Spark cluster is a shared enterprise asset.
- When cluster resources are shared among many Spark applications that are processed in parallel.
Perform the following steps to set up the application.properties file:
Procedure
Log on to the cluster and stop the AEL daemon as described in Step 6 of Configure the AEL daemon for YARN mode.
Navigate to the design-tools/data-integration/adaptive-execution/config folder and open the application.properties file with any text editor.
Enter the Spark configuration parameter and value for each setting that you want to make in the cluster. For example,
spark.yarn.executor.memoryOverhead=1024Note See Determining Spark resource requirements for an example of calculating resources.Save and close the file.
Restart the AEL daemon as described in Step 6 of Configure the AEL daemon for YARN mode.
Results
Set the Spark parameters locally in PDI
Perform the following steps to set the Spark parameters in PDI:
Procedure
In the PDI, double-click the transformation canvas, or press CtrlT.
The transformation properties dialog box opens.Click the Parameters tab.
The Parameters table opens.Enter the Spark parameter in the Parameters column and the value for that property in the Default Value column of the table. Optionally, enter a description.
NoteIf the parameter and the variable share the same name, the parameter takes precedence.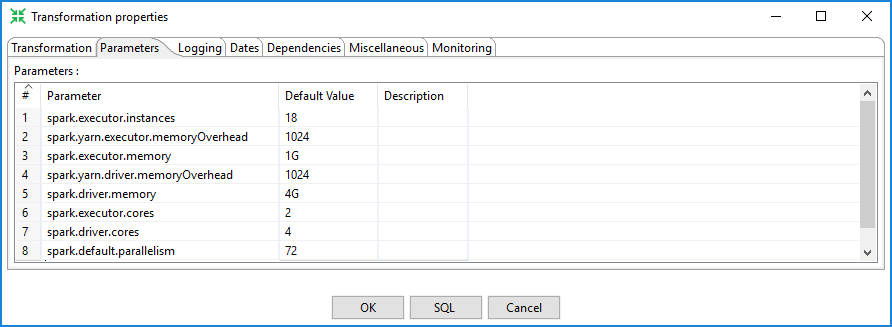
Click OK.
Results
Optimizing Spark tuning
To refine your initial application tuning parameters, perform test runs of PDI steps on the Spark cluster to verify the most optimal, repeatable settings. Using an iterative approach, you can modify the parameter values for the most efficient settings for your Spark cluster and individual KTR configurations. As more jobs are executed on the cluster, the tuning parameters may need to be adjusted for additional resource consumption, overhead, and other factors. You can verify optimized tuning as described in the following steps.
Step 1: Set the Spark parameters on the cluster
Before you begin
Procedure
Set the Spark parameters as described in Set the Spark parameters globally.
Run a single step PDI transformation on the cluster using a small number of executors per node and record the number of minutes it takes for the run to complete.
Increment the number of executors per node by 1, and then rerun the PDI transformation and record the time it takes to complete.
Repeat step 3 for as many executors per node that you want to verify.
The following table shows an example of the results using the Sort PDI transformation step.PDI step Run number Executors per node Job duration Sort 1 2 37 minutes Sort 2 3 42 minutes Sort 3 4 38 minutes Sort 4 5 40 minutes Evaluate the results of the runs, then choose the fastest, most repeatable run.
The performance results of your executed transformations are available on the YARN ResourceManager and Spark History Server.Set the values for the Spark parameters in the
application.propertiesfile according to the findings in step 5.Rerun the transformation with the selected value several times to verify the results.
The global tuning for the Spark application is recorded in the Logging tab in the Execution Results panel of PDI.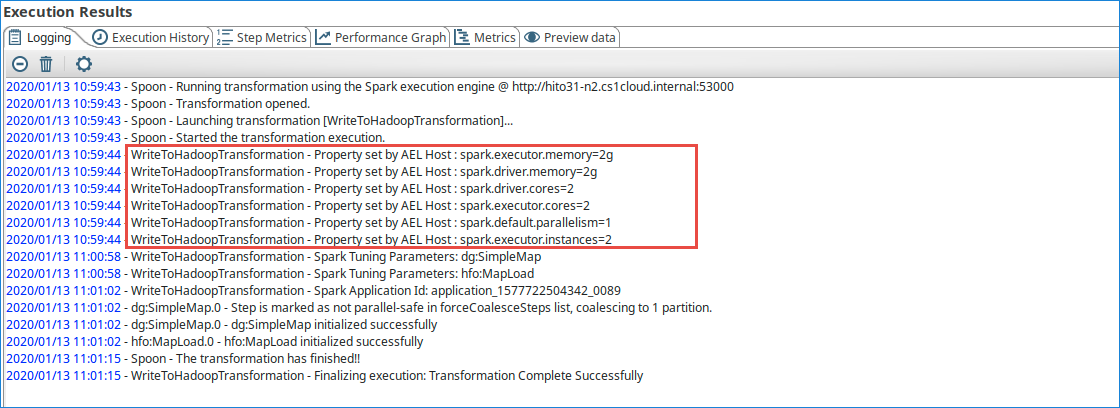
Results
Step 2: Adjust the Spark parameters in the transformation
Before you begin
Use the following steps to optimize Spark tuning locally.
Procedure
Set the Spark parameters as described in Set the Spark parameters locally in PDI.
Run the transformation on the cluster and evaluate the results as recorded in the Logging tab in the Execution Results panel of PDI.
The local tuning for the Spark application is recorded in the Logging tab in the Execution Results panel of PDI.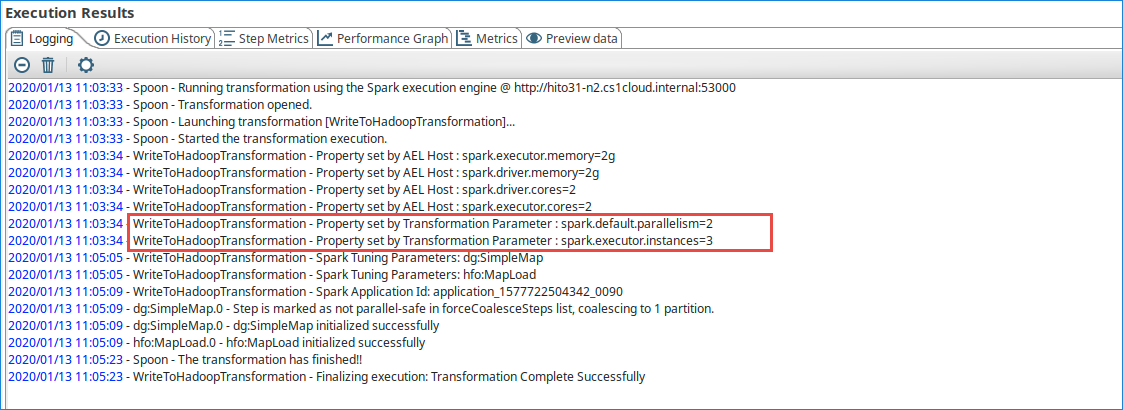
Modify the values of the Spark parameters then rerun the transformation.
Repeat step 3 as needed to collect data on the performance results of the different values.
Examine the results of your iterations in the log.
Set the Spark parameters in the transformation according to the values that produced the fastest runtime.
Results
Step 3: Set the Spark tuning options on a PDI step in the transformation
Before you begin
Use the following steps to fine-tune Spark for a specific step in the KTR.
Procedure
Set the Spark parameters as described in Setting PDI step Spark tuning options.
Run the transformation on the cluster and evaluate the results as recorded in the Logging tab on the Execution Results panel of PDI.
The step names and tuning options for the Spark application are recorded in the Logging tab in the Execution Results panel of PDI.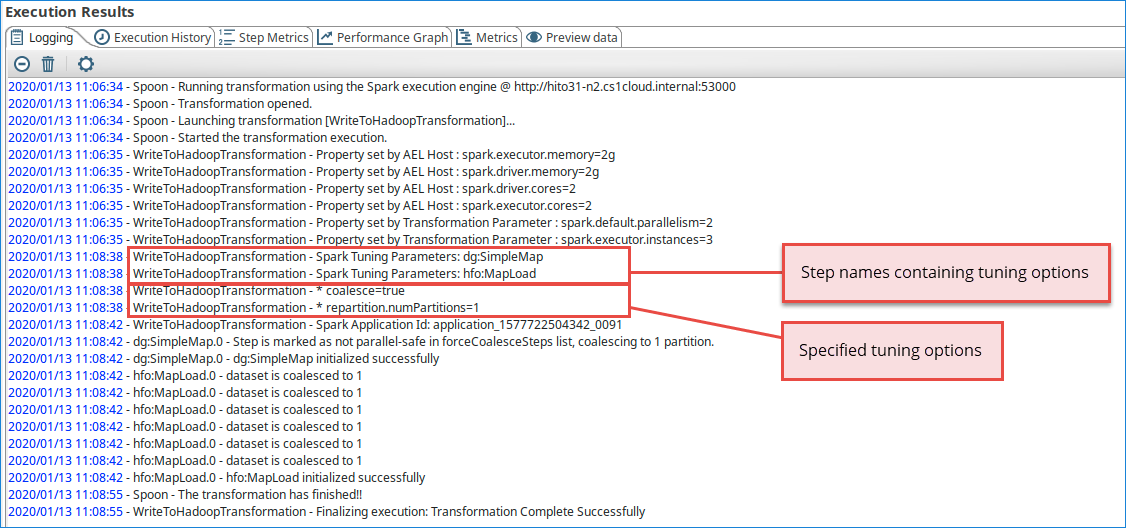
Modify the values of the Spark parameters then rerun the transformation.
Repeat step 3 as needed to collect performance results data for different values.
Examine the results of your iterations in the log.
Set the Spark parameters in the step according to the values that produced the fastest runtime.
Results