Spark Submit

Apache Spark is an open-source cluster computing framework.
Use the Spark Submit job entry to submit Spark jobs to any of the following Hadoop clusters:
- CDH 5.9 and later
- HDP 2.4 and later
- Azure HDI 3.5 and later
- EMR 4.6 and later
- MapR 5.1 and later
You can submit Spark jobs written in either Java, Scala, or Python.
Before you begin
Before you install Spark, we strongly recommend that you review the following Spark documentation, release notes, and known issues first:
- https://spark.apache.org/releases/
- https://spark.apache.org/docs/latest/configuration.html
- https://spark.apache.org/docs/latest/running-on-yarn.html
- Spark installation and configuration documentation
You may also want to reference the https://spark.apache.org/docs/2.2.0/submitting-applications.html instructions on how to submit jobs for Spark.
If planning to use a MapR Spark client, you will first need to install and configure it before configuring Spark to work withPDI. If you are not using a MapR Spark client, proceed to Install and configure Spark client for PDI use.
Install and configure the MapR Spark client
Procedure
Follow the instructions in http://maprdocs.mapr.com/51/AdvancedInstallation/SettingUptheClient-Instal_26982445-d3e172.html to set up your MapR packages, repositories, and MapR client for your version of MapR.
Copy the hive-site.xml file from the /opt/mapr/spark/your version of spark/conf folder on the MapR cluster to the MapR configuration folder on your client machines.
Install the MapR Spark client using the following command:
- sudo apt-get install mapr-spark
Follow the instructions in http://maprdocs.mapr.com/51/Spark/ConfigureSparkOnYarn_MapRClient.html to configure the hadoop-yarn-server-web-proxy JAR file to run Spark applications on Yarn.
Navigate to <SPARK_HOME>/conf folder and create the spark-defaults.conf file using the instructions in https://spark.apache.org/docs/latest/configuration.html.
Find the spark-assembly.jar file on a cluster node that has its own Spark client as shown in the following example:
- sudo find/ -name spark-assembly*
Copy the spark-assembly.jar file from your local machine to the cluster as shown in the following example:
hadoop fs -put /Local Path To spark-assembly.jar /Path To Location On Cluster
Edit the spark-defaults.conf file to add the following code using your MAPRFS name and spark-assembly.jar file path from Step 7:
spark.yarn.jar maprfs:///Path To Location On MAPRFS To Your spark-assembly file.jar
Results
Install and configure Spark client for PDI use
You will need to install and configure the Spark client to work with the cluster on every machine you will want to run Spark jobs through PDI. How you configure these clients depends on your version of Spark.
Spark version 1.x.x
Procedure
On the client, download the Spark distribution of the same version as the one used on the cluster.
Set the HADOOP_CONF_DIR environment variable to a folder containing cluster configuration files as shown in the following sample for an already configured shim:
pentaho-big-data-plugin/hadoop-configurations/shim directory
Navigate to <SPARK_HOME>/conf and create the spark-defaults.conf file using the instructions outlined in https://spark.apache.org/docs/latest/configuration.html.
Find the spark-assembly.jar file on a cluster node that has its own Spark client as shown in the following example:
- sudo find/ -name spark-assembly
Copy the spark-assembly.jar file from your local machine to the cluster as shown in the following example:
hadoop fs -put /Local Path To spark-assembly.jar/Path To Location On ClusterEdit the spark-defaults.conf file to set the spark.yarn.archive property to the location of your spark-assembly.jar file on the cluster as shown in the following examples:
spark.yarn.archive hdfs://NameNode hostname:8020/user/spark/lib/spark-assembly.jar
Create home folders with write permissions for each user who will be running the Spark job as shown in the following examples:
hadoop fs -mkdir /user/user namehadoop fs -chown <user name>/user/<user name>
If you are connecting to an HDP cluster, add the following lines in the spark-defaults.conf file:
spark.driver.extraJavaOptions -Dhdp.version=2.7.1.2.3.0.0-2557spark.yarn.am.extraJavaOptions -Dhdp.version=2.7.1.2.3.0.0-2557
NoteThe Hadoop version should be the same as Hadoop version used on the cluster.If you are connecting to an HDP cluster, also create a text file named java-opts in the <SPARK_HOME>/conf folder and add your HDP version to it as shown in the following example:
-Dhdp.version=2.3.0.0-2557
NoteRun the hdp-select status Hadoop client command to determine your version of HDP.If you are connecting to a supported version of the HDP or CDH cluster, open the core-site.xml file, then comment out the net.topology.script.file property as shown in the following code block:
<!-- <property> <name>net.topology.script.file.name</name> <value>/etc/hadoop/conf/topology_script.py</value> </property> -->
Spark version 2.x.x
Procedure
On the client, download the Spark distribution of the same or higher version as the one used on the cluster.
Set the HADOOP_CONF_DIR environment variable to a folder containing cluster configuration files as shown in the following sample for an already-configured shim:
pentaho-big-data-plugin/hadoop-configurations/shim directory
Navigate to <SPARK_HOME>/conf and create the spark-defaults.conf file using the instructions outlined in https://spark.apache.org/docs/latest/configuration.html.
Create a ZIP archive containing all the JAR files in the SPARK_HOME/jars directory.
Copy the ZIP file from the local file system to a world-readable location on the cluster.
Edit the spark-defaults.conf file to set the spark.yarn.archive property to the world-readable location of your ZIP file on the cluster as shown in the following examples:
spark.yarn.archive hdfs://NameNode hostname:8020/user/spark/lib/your ZIP file
Also add the following line of code to the spark-defaults.conf file:
spark.hadoop.yarn.timeline-service.enabled false
If you are connecting to an HDP cluster, add the following lines in the spark-defaults.conf file:
spark.driver.extraJavaOptions -Dhdp.version=2.3.0.0-2557spark.yarn.am.extraJavaOptions -Dhdp.version=2.3.0.0-2557
NoteThe -Dhdp version should be the same as Hadoop version used on the cluster.If you are connecting to an HDP cluster, also create a text file named java-opts in the <SPARK_HOME>/conf folder and add your HDP version to it as shown in the following example:
-Dhdp.version=2.3.0.0-2557
NoteRun the hdp-select status Hadoop client command to determine your version of HDP.If you are connecting to a supported version of the HDP or CDH cluster, open the core-site.xml file, then comment out the net.topology.script.file property as shown in the following code block:
<!-- <property> <name>net.topology.script.file.name</name> <value>/etc/hadoop/conf/topology_script.py</value> </property> -->
Troubleshooting your configuration
Errors may occur when trying to connect CDH 5.7 or later with Spark 1.6.x or while running a Spark job from a Windows machine.
Connecting CDH 5.7 or later with Spark 1.6.x
If you are connecting to the CDH 5.7 (or later) cluster when using Apache Spark 1.6.x on your client node, an error may occur while trying to run a job containing a Spark Submit entry in yarn-client mode. This error will be similar to the following message:
- Caused by: java.io.InvalidClassException: org.apache.spark.rdd.MapPartitionsRDD; local class incompatible: stream classdesc serialVersionUID = -1059539896677275380, local class serialVersionUID = 6732270565076291202
Perform one of the following tasks to resolve this error:
- Install and configure CDH 5.7 (or later) Spark on the client machine where Pentaho is running instead of Apache Spark 1.6.x. See Cloudera documentation for Spark installation instructions.
- If you want to use Apache Spark 1.6.x on a client machine, then upload spark-assembly.jar from the client machine to your cluster in HDFS, and point the spark.yarn.jar property in the spark-defaults.conf file to this uploaded spark-assembly.jar file on the cluster.
Running a Spark job from a Windows machine
The following errors may occur when running a Spark Submit job from a Windows machine:
- ERROR yarn.ApplicationMaster: Uncaught exception: org.apache.spark.SparkException: Failed to connect to driver! - JobTracker's log
- Stack trace: ExitCodeException exitCode=10 - Spoon log
To resolve these errors, create a new rule in the Windows firewall settings to enable inbound connections from the cluster.
General
The following table describes the fields for setting up which Spark job to submit:
| Field | Description |
| Entry Name | Specify name of the entry. You can customize or leave it as the default. |
| Spark Submit Utility | Specify the script that launches the spark job. |
| Master URL | Select the master URL for the cluster. The following two master URLs are
supported:
|
| Type | Select the file type of your Spark job to be submitted. Your job
can be written in Java, Scala, or Python. The fields displayed in the
Files tab depend on what language option you select. Python support on Windows requires Spark version 1.5.2 or higher. |
| Enable Blocking | Select blocking to have the Spark Submit entry wait until the Spark job finishes running. If this option is not selected, the Spark Submit entry proceeds with its execution once the Spark job is submitted for execution. Blocking is enabled by default. |
We support the yarn-cluster and yarn-client modes. Descriptions of the modes can be found in the following site:
Options
The Spark Submit entry features several tabs with fields. Each tab is described below.
Files tab
The fields of this tab depend on whether you set the Spark job Type to Java or Scala or Python.
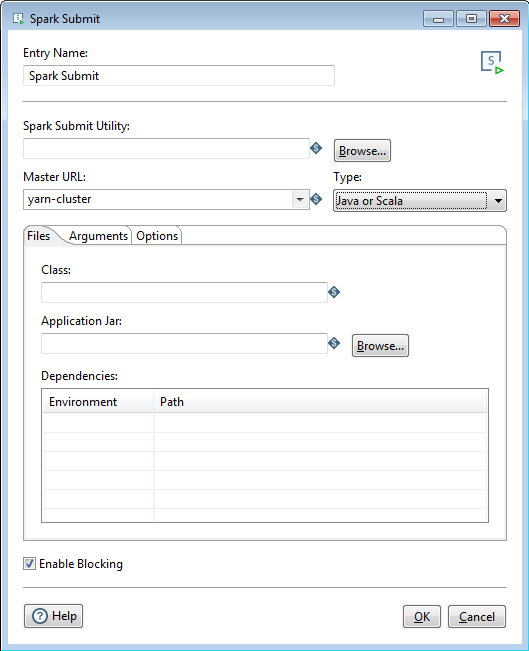
Java or Scala
If you select Java or Scala as the file Type, the Files tab will contain the following options:
| Option | Description |
| Class | Optionally, specify the entry point for your application. |
| Application Jar | Specify the main file of the Spark job you are submitting. It is a path to a bundled jar including your application and all dependencies. The URL must be globally visible inside of your cluster, for instance, an hdfs:// path or a file:// path that is present on all nodes. |
| Dependencies | Specify the Environment and Path of other packages, bundles, or libraries used as a part of your Spark job. Environment defines whether these dependencies are Local to your machine or Static on the cluster or the web. |
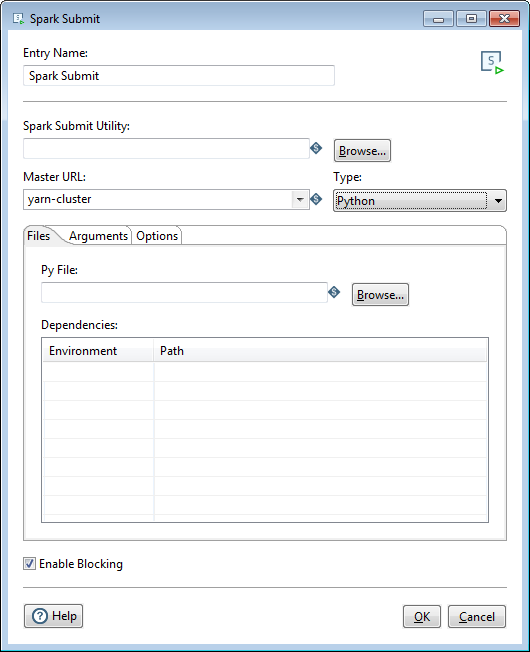
Python
If you select Python as the file Type, the Files tab will contain the following options:
| Option | Description |
| Py File | Specify the main Python file of the Spark job you are submitting. |
| Dependencies | Specify the Environment and Path of other packages, bundles, or libraries used as a part of your Spark job. Environment defines whether these dependencies are Local to your machine or Static on the cluster or the web. |
Arguments tab
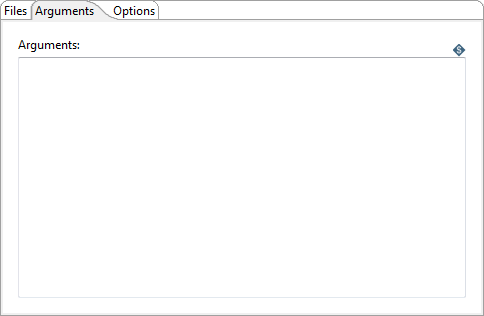
Enter the following information to pass arguments to the Spark job:
| Option | Description |
| Arguments | Specify and arguments passed to your main Java class, Scala class, or Python Py file through the text box provided. |
Options tab
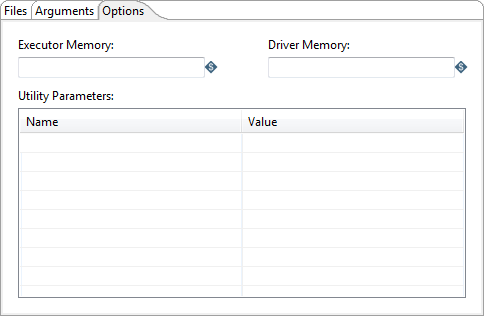
Enter the following information to adjust the amount of memory used or define optional parameters:
| Option | Description |
| Executor Memory | Specify the amount of memory to use per executor process. Use the JVM format (for example, 512m or 2g). |
| Driver Memory | Specify the amount of memory to use per driver. Use the JVM format (for example, 512m or 2g). |
| Utility Parameters | Specify the Name and Value of optional Spark configuration parameters associated with the spark-defaults.conf file. |