MongoDB Output

This step writes data to a MongoDB collection.
AEL considerations
When using the MongoDB Output step with the Adaptive Execution Layer, the following factor affects performance and results:
- Spark processes null values differently than the Pentaho engine. You will need to adjust your transformation to successfully process null values according to Spark's processing rules.
General
Enter the following information in the transformation step name field.
- Step Name: Specify the unique name of the MongoDB Output step on the canvas. You can customize the name or leave it as the default.
Options
The MongoDB Output step features several tabs with fields. Each tab is described below.
Configure connection tab
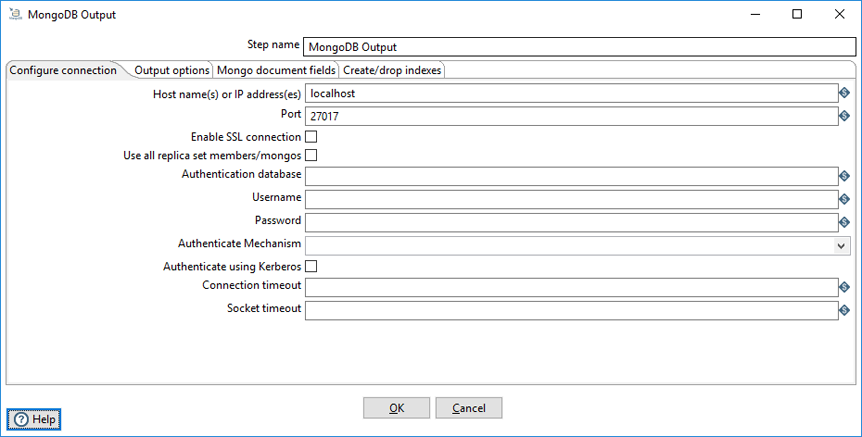
The Configure connection tab enables you to specify the database and collection for your output.
Enter the following information in the transformation step fields:
| Field | Description |
| Host name(s) or IP address(s) | Specify the network name or address of the MongoDB instance(s). You can also specify a different port number for each host name by separating the host name and port number with a colon. You can input multiple host names or IP addresses, separated by a comma. |
| Port | Specify the port number of the MongoDB instance or instances. Use this to specify a default port if no ports are given as part of the host name(s) or IP address(es) field. The default value is 27017. |
| Enable SSL connection | Specify to connect to a MongoDB Server that is configured with SSL. |
| Use all replica set members/mongos |
Select to use all replica sets when multiple hosts are specified in the Host name(s) or IP address(s) field. If a replica set contains more than one host, the Java driver discovers all hosts automatically. The driver connects to the next replica set in the list if the set you try to connect to is down. |
| Authentication database | Specify the authentication database. |
| Username | Specify the username required to access the database. If you want to use Kerberos authentication, enter the Kerberos principal in this field. |
| Password | Specify the password associated with the username. If you are using Kerberos authentication, you do not need to enter the password. |
| Authenticate Mechanism | Select the method used to verify the identity of users. The values are SCRAM-SHA-1 and MONGODB-CR. |
| Authenticate using Kerberos | Select to specify authentication using Kerberos. |
| Connection timeout | Specify (in milliseconds) how long to wait for a connection to a database before terminating the connection attempt. Leave blank to never terminate the connection. |
| Socket timeout | Specify (in milliseconds) how long to wait for a write operation before terminating the operation. Leave blank to never terminate the operation. |
Output options tab
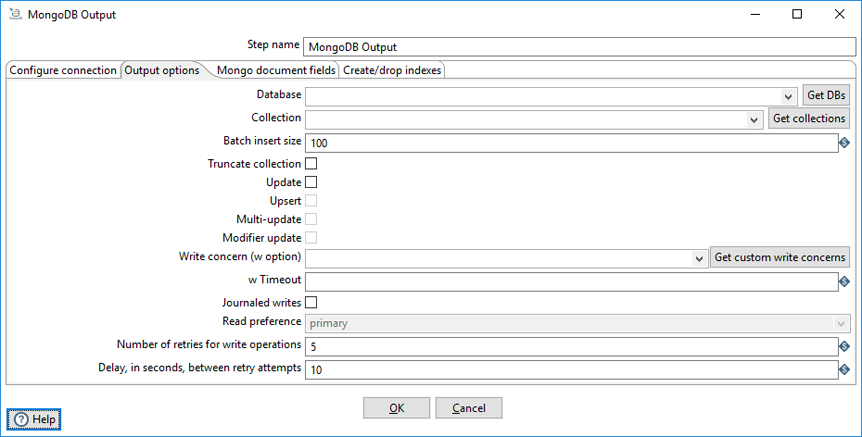
The Output options tab provides additional controls for inserting data into a MongoDB collection. If the specified collection does not exist, it is created before a document is inserted.
Enter the following information in the transformation step fields:
| Option | Description |
| Database | Specify the target database for the output. When a valid hostname and port has been set, you can click Get DBs to retrieve the names of existing databases within a selected database. |
| Collection | Specify the target collection for the output. When a valid hostname and port has been set, you can click Get Collections to retrieve the names of existing collections within a selected database. If the specified collection does not exist, it will be created before data is inserted. |
| Batch insert size | Specify the batch size for bulk insert operations. The default value is 100 rows. |
| Truncate collection | Select to delete existing data in the target collection before inserting new data. |
| Update |
Sets the update write method for the specified database and collection. The Upsert and Modifier update options are not available unless the Update field is selected. |
| Upsert | Select to change the write method from insert to upsert. The upsert method replaces a matched record with an entire new record based on all the incoming fields specified in the Mongo document fields tab. A new record is created if match conditions fail for an update. |
| Multi-update | Select to update all matching documents for each update or upsert operation. |
| Modifier update |
Select to enable modifiers ( To update more than one matching document, select Modifier update and Upsert. Selecting Modifier update, Upsert, and Multi-update applies updates to all matching documents, instead of just the first. |
| Write concern (w option) |
Specify the minimum number of servers that must succeed for a write operation. The values are:
Click Get custom write concerns to retrieve custom write concerns that you have stored in the repository. |
| w Timeout | Specify time (in milliseconds) to wait for a response to write operations before terminating the operation. Leave blank to never terminate. |
| Journaled writes | Select to set write operations to wait until the mongod (the primary daemon process for the MongoDB system) acknowledges the write operation and commits the data to the journal. |
| Read preference |
Specify which node to read first
The default is Primary. The Read preference is available when Modifier update is selected. |
| Number of retries for write operations | Specify the number of times that a write operation is attempted. |
| Delay, in seconds, between retry attempts | Specify the number of seconds to wait before the next retry. |
Mongo document fields tab
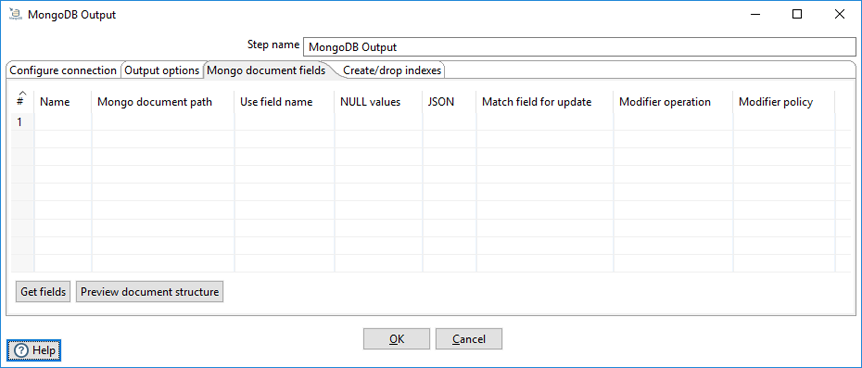
Use the Mongo document fields tab to define how field values coming into the step are written to a Mongo document. The Modifier policy column controls when the execution of a modifier operation affects a particular field. You can use modifier policies when the data for one Mongo document is split over several incoming PDI rows or when it is not possible to execute different modifier operations that affect the same field simultaneously.
Enter the following information in the transformation step fields:
| Column | Field Description |
| Name | Names of the incoming fields. |
| Mongo document path | The hierarchical path to fields in a document in dot notation format. |
| Use field name | Whether to use the incoming field name as the final entry in the path. The values are Y (use incoming field names) and N (do not use incoming field names). When set to Y, a preceding period (.) is assumed. |
| NULL values |
Whether to insert null values in the database. The values are:
|
| JSON | Indicates the incoming value is a JSON document. |
| Match field for update | Indicates whether to match a field when performing an upsert operation. The first document in the collection that matches all fields tagged as Y in this column is replaced with the new document constructed with incoming values for all the defined field paths. If a matching document does not exist, then a new document is inserted into the collection. |
| Modifier operation |
Specify in-place modifications of existing document fields. The modifiers are:
|
| Modifier policy |
Controls when execution of a modifier operation affects a field. The values are:
|
| Get fields | Populates the Name column of the table with the names of the incoming fields. |
| Preview document structure | Opens a dialog showing the structure that will be written to MongoDB in JSON format. |
Example
Here is an example of how you can define a document structure with an arbitrary hierarchy. Use the following input data and document field definitions to create the example document structure in MongoDB:
Input data
first, last, address, age Bob, Jones ,"13 Bob Street", 34 Fred, Flintstone, "10 Rock Street",50 Zaphod, Beeblebrox, "Beetlejuice 1", 356 Noddy,Puppet,"Noddy Land",5
Document field definitions
| Name | Mongo document path | Use field name | NULL values | JSON | Match field for update | Modifier operation | Modifier policy |
| first | top1 | Y | N | N | N/A | lnsert&Update | |
| last | array[O] | Y | N | N | N/A | lnsert&Update | |
| address | array[O] | Y | N | N | N/A | lnsert&Update | |
| age | array[O] | Y | N | N | N/A | lnsert&Update |
Document structure
{
"top1" : {
"first" : "<string val>"
},
"array" : [ { "last" : "<string val>" , "address" : "<string val>"}],
"age" : "<integer val>"
}
Create/drop indexes tab
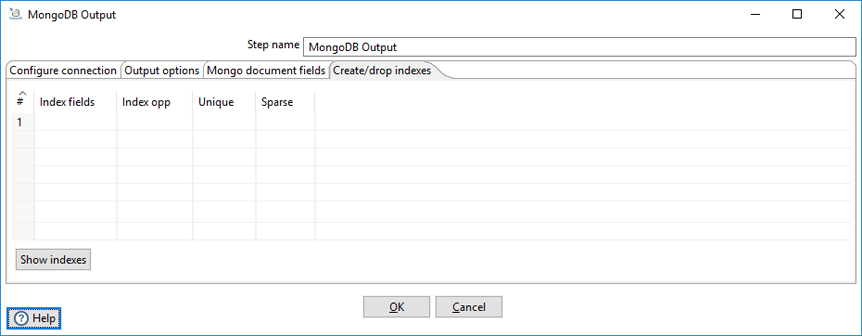
Use the Create/drop indexes tab to create and drop indexes on one or more fields. Unless unique indexes are being used, MongoDB allows duplicate records to be inserted. Indexing is performed after all rows have been processed by the step.
Enter the following information in the transformation step fields:
| Field | Description |
| Index fields | Specify a single index (using one field) or a compound index (using multiple fields). Compound indexes are specified by a comma-separated list of paths. Use dot notation to specify the path to a field to use in the index. An optional direction indicator can be specified: 1 for ascending or -1 for descending. |
| Index opp | Specify whether to create or drop an index. |
| Unique | Specify whether to index only fields with unique values. |
| Sparse | Specify whether to index only documents that have the indexed field. |
| Show indexes | Click Show indexes to display a list of existing indexes. |
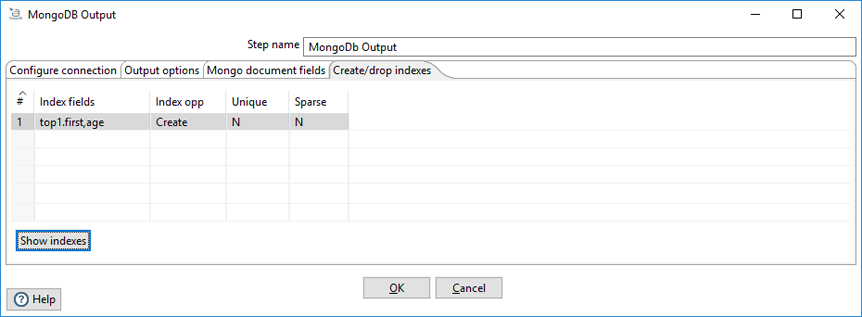
Create/drop indexes example
The following graphic shows the specification of a compound index of the "first" and "age" fields in ascending order:
Metadata injection support
All fields of this step support metadata injection. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.