Create step plugins

A transformation step implements a data processing task in an ETL data flow. It
operates on a stream of data rows. Transformation steps are designed for input, processing, or
output. Input steps fetch data rows from external data sources, such as files or databases.
Processing steps work with data rows, perform field calculations, and stream operations, such
as joining or filtering. Output steps write the processed data back to storage, files, or
databases.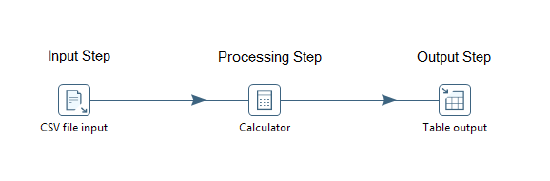
This section explains the architecture and programming concepts for creating your own PDI transformation step plugin. We recommended that you open and refer to the sample step plugin sources while following these instructions.
A step plugin integrates with PDI by implementing four distinct Java interfaces. Each interface represents a set of responsibilities performed by a PDI step. Each of the interfaces has a base class that implements the bulk of the interface in order to simplify plugin development.
Unless noted otherwise, all step interfaces and corresponding base classes are part of the org.pentaho.di.trans.step package.
| Java Interface | Base Class | Main Responsibilities |
StepMetaInterface | BaseStepMeta |
|
StepDialogInterface | org.pentaho.di.ui.trans.step.BaseStepDialog |
|
StepInterface | BaseStep |
|
StepDataInterface | BaseStepData |
|
Using your icon in PDI
Now that you have an image which provides a quick, intuitive representation of what your Step or Entry does and maintains consistency with other user interface elements within PDI, you need to save it delete in the proper format and to the proper location.
Including images in a built-in Kettle transformation or job
Procedure
Save your icon to Scalable Vector Graphics (SVG) Version 1.1 format.
If you want to include an image in a built-in Kettle transformation or job, place the SVG (and PNG) images in pentaho-kettle/ui/packages-res/ui/images
Edit the kettle-job-entries.xml or kettle-steps.xml file to point to the new icon file.
This file is located inside of the {kettle-install}/lib/kettle-engine-VERSION.jar.This can be done like this:<job-entry id="COPY_FILES"> <description>i18n:org.pentaho.di.job.entry:JobEntry.CopyFiles.TypeDesc</description> <classname>org.pentaho.di.job.entries.copyfiles.JobEntryCopyFiles</classname> <category>i18n:org.pentaho.di.job:JobCategory.Category.FileManagement</category> <tooltip>i18n:org.pentaho.di.job.entry:JobEntry.CopyFiles.Tooltip</tooltip> <iconfile>ui/images/CPY.svg</iconfile> <documentation_url>http://wiki.pentaho.com/display/EAI/Copy+Files</documentation_url> <cases_url/> <forum_url/> </job-entry>
Including images in a Kettle plugin
Procedure
Save your icon to Scalable Vector Graphics (SVG) Version 1.1 format.
Place the image in the plugin.
The specifics of the plugin's assembly will indicate where to put the image, but usually it is placed in the your-plugin-project/src folder.The image will be loaded, at runtime, from the plugin’s JAR file. The location of the file is indicated by the JobMeta or StepMeta for your plugin. This is usually accomplished with a Java annotation, like in this example:@JobEntry( id = "HadoopCopyFilesPlugin", image = "HDM.svg", name = "HadoopCopyFilesPlugin.Name", description = "HadoopCopyFilesPlugin.Description", categoryDescription = "i18n:org.pentaho.di.job:JobCategory.Category.BigData", i18nPackageName = "org.pentaho.di.job.entries.hadoopcopyfiles" ) public class JobEntryHadoopCopyFiles extends JobEntryCopyFiles {If you have developed a dialog (UI) for your plugin, you might want an SVG graphic to appear, as per UX standards. This code should be put in your plugin, in the Job or Step classes.
This can be done like this:icon.setImage(UIResource.getInstance().getImage("ModelAnnotation.svg", getClass().getClassLoader(), ConstUI.ICON_SIZE, ConstUI.ICON_SIZE));
Maintain step settings
The StepMetaInterface is the main Java interface that a
plugin implements.
| Java Interface | org.pentaho.di.trans.step.StepMetaInterface |
| Base class | org.pentaho.di.trans.step.BaseStepMeta |
The implementing class keeps track of step settings using private fields with
corresponding get and set methods. The dialog class
implementing StepDialogInterface uses these methods to copy the user
supplied configuration in and out of the dialog.
These interface methods are also used to maintain settings.
void setDefault()This method is called every time a new step is created and allocates or sets the step configuration to sensible defaults. The values set here are used by the PDI client (Spoon) when a new step is created. This is a good place to ensure that the step settings are initialized to non-null values. Null values can be cumbersome to deal with in serialization and dialog population, so most PDI step implementations stick to non-null values for all step settings.
public Object clone()This method is called when a step is duplicated in the PDI client. It returns a deep copy of the step meta object. It is essential that the implementing class creates proper deep copies if the step configuration is stored in modifiable objects, such as lists or custom helper objects.
See org.pentaho.di.trans.steps.rowgenerator.RowGeneratorMeta.clone() in the PDI source for an example
of creating a deep copy.
The plugin serializes its settings to both XML and a PDI repository. These interface methods provide this functionality.
public String getXML()This method is called by PDI whenever a step serializes its settings to XML. It is called when saving a transformation in the PDI client. The method returns an XML string containing the serialized step settings. The string contains a series of XML tags, one tag per setting. The helper class,
org.pentaho.di.core.xml.XMLHandler, constructs the XML string.public void loadXML()This method is called by PDI whenever a step reads its settings from XML. The XML node containing the step settings is passed in as an argument. Again, the helper class,
org.pentaho.di.core.xml.XMLHandler, reads the step settings from the XML node.public void saveRep()This method is called by PDI whenever a step saves its settings to a PDI repository. The repository object passed in as the first argument provides a set of methods for serializing step settings. The passed in transformation id and step id are used by the step as identifiers when calling the repository serialization methods.
public void readRep()This method is called by PDI whenever a step reads its configuration from a PDI repository. The step id given in the arguments is used as the identifier when using the repositories serialization methods.
When developing plugins, make sure the serialization code is in synch with the settings available from the step dialog. When testing a step in the PDI client, PDI internally saves and loads a copy of the transformation before executing it.
The StepMetaInterface plugin class is the main class, tying in with the rest of PDI architecture. It is
responsible for supplying instances of the other plugin classes implementing StepDialogInterface, StepInterface, and StepDataInterface. The
following methods cover these responsibilities. Each method implementation constructs a new instance of the corresponding class, forwarding the passed in arguments to the constructor.
public StepDialogInterface getDialog()public StepInterface getStep()public StepDataInterface getStepData()
Each of these methods returns a new instance of the plugin class implementing StepDialogInterface, StepInterface, and StepDataInterface.
PDI
needs to know how a step affects the row structure. A step may be adding or removing fields,
as well as modifying the metadata of a field. The method implementing this aspect of a step
plugin is getFields().
public void getFields()Given a description of the input rows, the plugin modifies it to match the structure for its output fields. The implementation modifies the passed in
RowMetaInterfaceobject to reflect changes to the row stream. A step adds fields to the row structure. This is done by creatingValueMetaobjects, such as the PDI default implementation ofValueMetaInterface, and appending them to theRowMetaInterfaceobject. The Work with fields section goes into deeper detail aboutValueMetaInterface.
This sample transformation uses two steps. The Demo step adds the field, demo_field, to empty rows produced by the Generate Rows step.
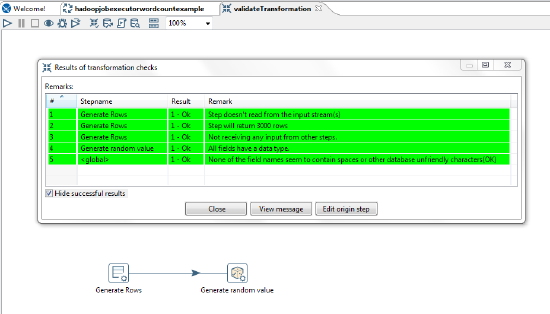
The PDI client supports a Validate Transformation feature, which
triggers a self-check of all steps. PDI invokes the check() method of each step on the
canvas, allowing each step to validate its settings.
public void check()Each step has the opportunity to validate its settings and verify that the configuration given by the user is reasonable. In addition, a step checks if it is connected to preceding or following steps, if the nature of the step requires that kind of connection. An input step may expect to not have a preceding step for example. The check method passes in a list of check remarks, to which the method appends its validation results. The PDI client displays the list of remarks collected from the steps, allowing you to take corrective action in case there are validation warnings or errors.
The class implementing StepMetaInterface must be annotated
with the Step Java annotation. Supply the
following annotation attributes:
| Attribute | Description |
id | A globally unique ID for the step |
image | The resource location for the png icon image of the step |
name | A short label for the step |
description | A longer description for the step |
categoryDescription | The category the step should appear under in the PDI step tree. For example Input, Output, Transform, etc. |
i18nPackageName | If the i18nPackageName attribute is supplied in the annotation attributes, the values of name, description, and categoryDescription are interpreted as
i18n keys relative to the message bundle contained in given package. The keys may be supplied in the extended form i18n:<packagename> key to
specify a package that is different from the package given in the i18nPackageName attribute. |
Please refer to the Sample step plugin for a complete implementation example.
Implement the Step Settings dialog box
This section explains how to create a step settings dialog in your plugins.
StepDialogInterface is the Java interface that implements the
plugin settings dialog.
| Java Interface | org.pentaho.di.trans.step.StepDialogInterface |
| Base class | org.pentaho.di.ui.trans.step.BaseStepDialog |
Maintain the dialog for step settings
The dialog class is responsible for constructing and opening
the settings dialog for the step. Whenever you open the step settings in the PDI client (Spoon), the
system instantiates the dialog class passing in the
StepMetaInterface object and calling open() on the
dialog. SWT is the native windowing environment of the PDI client and is the
framework used for implementing step dialogs.
public String open()This method returns only after the dialog has been confirmed or cancelled. The method must conform to these rules.
- If the dialog is confirmed
- The
StepMetaInterfaceobject must be updated to reflect the new step settings - If you changed any step settings, the Changed flag of the
StepMetaInterfaceobject flag must be set totrue open()returns the name of the step
- The
- If the dialog is cancelled
- The
StepMetaInterfaceobject must not be changed - The Changed flag of the
StepMetaInterfaceobject must be set to the value it had at the time the dialog opened open()must returnnull
- The
- If the dialog is confirmed
The StepMetaInterface object has an internal
Changed flag that is accessible using hasChanged() and
setChanged(). The PDI client decides whether the transformation has unsaved changes
based on the Changed flag, so it is important for the dialog to set the
flag appropriately.
The sample step plugin project has an implementation of the dialog class that is consistent with these rules and is a good basis for creating your own dialog.
Process rows
This section explains how you implement row processing in your plugins.
The class implementing StepInterface is responsible for the
actual row processing when the transformation runs.
| Java Interface | org.pentaho.di.trans.step.StepInterface |
| Base class | org.pentaho.di.trans.step.BaseStep |
The implementing class can rely on the base class and has only three important methods it implements itself. The three methods implement the step life cycle during transformation execution: initialization, row processing, and clean-up.
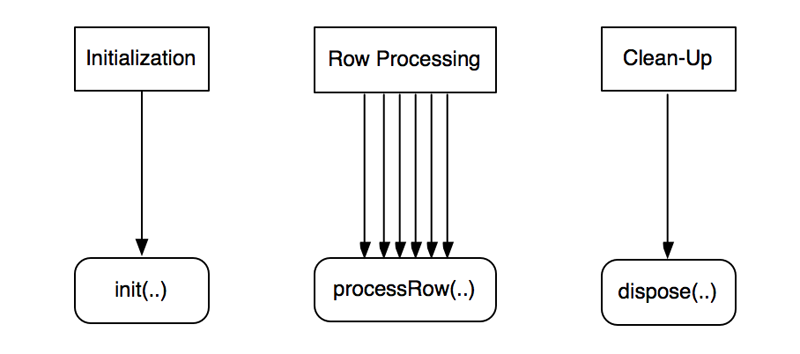
During initialization PDI calls the init() method of the step once. After all steps have
initialized, PDI calls processRow() repeatedly until the step signals that it is done processing all
rows. After the step is finished processing rows, PDI calls dispose().
The method signatures have a StepMetaInterfaceobject and a StepDataInterface object. Both objects can be safely cast down to the specific implementation classes of the step.
Aside from the methods it needs to implement, there is one additional and very important rule: the class must not declare any fields. All variables must be kept as part of the class
implementing StepDataInterface. In practice this is not a problem, since the object implementing StepDataInterface is passed in to all relevant methods, and
its fields are used instead of local ones. The reason for this rule is the need to decouple step variables from instances of StepInterface. This enables PDI to implement different threading models to execute a transformation.
The init() method is called when a transformation is preparing
to start execution.
public boolean init()Every step is given the opportunity to do one-time initialization tasks, such as opening files or establishing database connections. For any steps derived from
BaseStep, it is mandatory thatsuper.init()is called to ensure correct behavior. The method returnstruein case the step initialized correctly, it returnsfalseif there is an initialization error. PDI will abort the execution of a transformation in case any step returnsfalseupon initialization.
Once the transformation starts, it enters a tight loop, calling
processRow() on each step until the method returns
false. In most cases, each step reads a single row from the input stream,
alters the row structure and fields, and passes the row on to the next step. Some steps,
such as input, grouping, and sorting steps, read rows in batches, or can hold on to the read
rows to perform other processing before passing them on to the next step.
public boolean processRow()A PDI step queries for incoming input rows by calling
getRow(), which is a blocking call that returns a row object ornullin case there is no more input. If there is an input row, the step does the necessary row processing and callsputRow()to pass the row on to the next step. If there are no more rows, the step callssetOutputDone()and returnsfalse.
The method must conform to these rules.
- If the step is done processing all rows, the method calls
setOutputDone()and returnsfalse. - If the step is not done processing all rows, the method returns
true. PDI callsprocessRow()again in this case.
The sample step plugin project shows an
implementation of processRow() that is commonly used in data processing
steps.
In contrast to that, input steps do not usually expect any incoming rows from previous steps. They are designed to execute processRow() exactly once, fetching data from the
outside world, and putting them into the row stream by calling putRow() repeatedly until done. Examining existing PDI steps is a good guide for designing your processRow() method.
The row structure object is used during the first invocation of processRow() to determine the indexes of fields on which the step operates. The BaseStep
class already provides a convenient First flag to help implement special processing on the first invocation of processRow(). Since the row structure is
equal for all input rows, steps cache field index information in variables on their StepDataInterface object.
Once the transformation is complete, PDI calls
dispose() on all steps.
Public void dispose()Steps are required to deallocate resources allocated during
init()or subsequent row processing. Your implementation should clear all fields of theStepDataInterfaceobject, and ensure that all open files or connections are properly closed. For any steps derived fromBaseStep, it is mandatory thatsuper.dispose()is called to ensure correct deallocation.
Store the processing state
This section explains how to store the processing state.
| Java Interface | org.pentaho.di.trans.step.StepDataInterface |
| Base class | org.pentaho.di.trans.step.BaseStepData |
The class implementing StepInterface does not store processing state in any of its fields. Instead an additional class implementing StepDataInterface is used
to store processing state, including status flags, indexes, cache tables, database connections, file handles, and alike. Implementations of StepDataInterface declare the
fields used during row processing and add accessor functions. In essence the class implementing StepDataInterface is used as a place for field variables during row
processing.
PDI creates instances of the class implementing StepDataInterface at the appropriate time and passes it
on to the StepInterface object in the appropriate method calls. The base class already implements all necessary interactions with PDI and there is no need to override any base class methods.
Work with rows
A row in PDI is represented by a Java object array, Object[]. Each field value is stored at an index in
the row. While the array representation is efficient to pass data around, it is not immediately clear how to determine the field names and types that go with the array. The row array itself
does not carry this meta data. Also an object array representing a row usually has empty slots towards its end, so a row can accommodate additional fields efficiently. Consequently, the length
of the row array does not equal the amount of fields in the row. The following sections explain how to safely access fields in a row array.
PDI
uses internal objects that implement RowMetaInterface to describe and
manipulate row structure. Inside processRow() a step can retrieve the
structure of incoming rows by calling getInputRowMeta(), which is provided
by the BaseStep class. The step clones the
RowMetaInterface object and passes it to getFields() of
its meta class to reflect any changes in row structure caused by the step itself. Now, the
step has RowMetaInterface objects describing both the input and output
rows. This illustrates how to use RowMetaInterface objects to inspect row
structure.
There is a similar object that holds information about individual row fields. PDI uses internal objects that implement ValueMetaInterface to describe and manipulate field information, such as field name, data type, format mask, and alike.
A step looks for the indexes and types of relevant fields upon first execution of processRow(). These methods of RowMetaInterface are useful to achieve
this.
| Method | Purpose |
indexOfValue(String valueName) | Given a field name, determine the index of the field in the row. |
getFieldNames() | Returns an array of field names. The index of a field name matches the field index in the row array. |
searchValueMeta(String valueName) | Given a field name, determine the meta data for the field. |
getValueMeta(int index) | Given a field index, determine the meta data for the field. |
getValueMetaList() | Returns a list of all field descriptions. The index of the field description matches the field index in the row array. |
If a step needs to create copies of rows, use the cloneRow()
methods of RowMetaInterface to create proper copies. If a step needs to add
or remove fields in the row array, use the static helper methods of RowDataUtil. For example, if a step is
adding a field to the row, call resizeArray(), to add the field. If the
array has enough slots, the orignial array is retruned as is. If the array does not have
enough slots, a resized copy of the array is returned. If a step needs to create new rows
from scratch, use allocateRowData(), which returns a somewhat
over-allocated object array to fit the desired number of fields.
| Class/Interface | Purpose |
| RowMetaInterface | Describes and manipulates row structure |
| ValueMetaInterface | Describes and manipulates field types and formats |
| RowDataUtil | Allocates space in row array |
Work with fields
This section explains field properties.
ValueMetaInterface objects are used to
determine the characteristics of the row fields. They are typically obtained from a
RowMetaInterface object, which is acquired by a call to
getInputRowMeta(). The getType() method returns one of
the static constants declared by ValueMetaInterface to indicate the PDI
field type. Each field type maps to a corresponding native Java type for the actual value.
The following table illustrates the mapping of the most frequently used field types.
| PDI data type | Type constant | Java data type | Description |
| String | TYPE_STRING | java.lang.String | A variable unlimited length text encoded in UTF-8 (Unicode) |
| Integer | TYPE_INTEGER | java.lang.Long | A signed long 64-bit integer |
| Number | TYPE_NUMBER | java.lang.Double | A double precision floating point value |
| BigNumber | TYPE_BIGNUMBER | java.math.BigDecimal | An arbitrary unlimited precision number |
| Date | TYPE_DATE | java.util.Date | A date-time value with millisecond precision |
| Boolean | TYPE_BOOLEAN | java.lang.Boolean | A boolean value true or false |
| Binary | TYPE_BINARY | java.lang.byte[] | An array of bytes that contain any type of binary data. |
Do not assume that the Java value of a row field matches these data types directly. This may or may not be true, based on the storage type used for the field.
In addition to the data type of a field, the storage type, getStorageType()/setStorageType(), is used to interpret the actual field value in a row array.
These storage types are available.
| Type constant | Actual field data type | Interpretation |
| STORAGE_TYPE_NORMAL | As listed in previous table | The value in the row array is of the type listed in the data type table above and represents the field value directly. |
| STORAGE_TYPE_BINARY_STRING | java.lang.byte[] | The field has been created using the Lazy Conversion feature. This means it is a non-altered sequence of bytes as read from an external medium, usually a file. |
| STORAGE_TYPE_INDEXED | java.lang.Integer | The row value is an integer index into a fixed array of possible values. The ValueMetaInterface object maintains the set of possible values in
getIndex()/setIndex() |
In a typical data processing scenario, a step is not interested in dealing with the complexities of the storage type. It just needs the actual data value on which to do processing. In order
to safely read the value of a field, the ValueMetaInterface object provides a set of accessor methods to get at the actual Java value. The argument is a value from a row array
that corresponds to the ValueMetaInterface object. The accessor methods always return a proper data value, regardless of the field storage type.
getString()getInteger()getNumber()getBigNumber()getDate()getBoolean()getBinary()
For each of these methods, RowMetaInterface has corresponding methods that require the row array and the index of the field as arguments.
ValueMetaInterface represents all aspects of a PDI field, including conversion masks, trim type, and alike. All of these are available using corresponding accessor methods, such as getConversionMask() and getTrimType(). Refer to the Javadoc for a complete overview.
Handling errors
Transformation steps may encounter errors at many levels. They may encounter unexpected data, or problems with the execution environment. Depending on the nature of the error, the step may decide to stop the transformation by throwing an exception, or support the PDI error handling feature, which allows you to divert bad rows to an error handling step.
If a step encounters an error during row processing, it may log an error and stop the transformation. This is done by calling setErrors(1), stopAll(),
setOutputDone(), and returning false from processRow(). Alternatively, the step can throw a KettleException, which also causes the transformation to stop.
It is sensible to stop the transformation when there is a problem with the environment or configuration of a step. For example, when a database connection cannot be made, a required file is not present, or an expected field is not in the row stream. These are errors that affect the execution of the transformation as a whole. If on the other hand the error is related to row data, the step should implement support for the PDI Error Handling feature.
You may want to divert bad rows to a specific error handling step. This
capability is referred to as the Error Handling feature. A step supporting this feature
overrides the BaseStep implementation of supportsErrorHandling() to return true. This
enables you to specify a target step for bad rows in the PDI client UI. During runtime, the step
checks if you configured a target step for error rows by calling
getStepMeta().isDoingErrorHandling(). If error rows are diverted, the
step passes the offending input row to putError() and provides additional
information about the errors encountered. It does not throw a
KettleException. If you do not configure a step to generate error rows
and send them to another step for processing, the step falls back to calling a hard stop.
Most core PDI steps support row-level error handling. The Number Range step is a good example. If error handling is enabled, it diverts the row into the error stream. If it is not, the step stops the transformation.
Understanding row counters
During transformation execution, each PDI step keeps track of a set of step metrics. These are displayed in the PDI client (Spoon) in the Step Metrics tab.
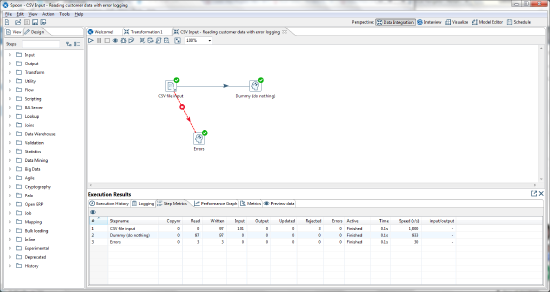
Each step metric is essentially a row counter. The counters are manipulated by calling the corresponding increment, decrement, get, and set methods on BaseStep. This table
provides a list of the counters and the correct way to use them.
| Counter Name | Meaning | When to Increment |
linesRead | Rows received from previous steps | Never increment manually. This is handled by getRow(). |
linesWritten | Rows passed to next steps | Never increment manually. This is handled by putRow(). |
linesInput | Rows read from external sources, such as files, database, and alike | Call incrementLinesInput() when a new row is received from an external source. |
linesOutput | Rows written to external sources, such as files, database, and alike | Call incrementLinesOutput() when a row is written to an external system or file. |
linesUpdated | Rows updated in external sources, such as database, and alike | Call incrementLinesUpdated() when a row is updated in an external system or file. |
linesSkipped | Rows for which part of the processing has been skipped | Call incrementLinesSkipped() when a row was skipped. This is relevant when the step implements conditional processing, and the condition for processing a row is
not satisfied. For example, an updating step may skip rows that are already up to date. |
linesRejected | Rows diverted to an error step as part of error handling | Never increment manually. This is handled by putError(). |
Logging in steps
A step interacts with the PDI logging system by using the logging methods inherited from BaseStep.
These methods are used to issue log lines to the PDI logging system on different severity levels. Multi-argument versions of the methods are available to do some basic formatting, which is equivalent to a call to MessageFormat.format(message, arguments).
public void logMinimal()public void logBasic()public void logDetailed()public void logDebug()public void logRowlevel()public void logError()
These methods query the logging level. They are often used to guard sections of code, that should only be executed with elevated logging settings.
public boolean isBasic()public boolean isDetailed()public boolean isDebug()public boolean isRowLevel()
Steps should log this information at specified levels.
| Log Level | Log Information Content |
| Minimal | Only information that is interesting at very high-levels, for example Transformation Started or Ended; individual steps do not log anything at this level |
| Basic | Information that may be interesting to you during regular ETL operation |
| Detailed | Prepared SQL or other query statements, resource allocation and initialization like opening files or connections |
| Debug | Anything that may be useful in debugging step operations |
| RowLevel | Anything that may be helpful in debugging problems at the level of individual rows and values |
| Error | Fatal errors that abort the transformation |
A transformation defines a feedback size in its settings. The feedback size defines the number of rows after which each step logs a line reporting its progress. This is implemented by calling
checkFeedback() with an appropriate row counter as argument to determine if feedback should be logged. Feedback logging happens on the basic log-level. There are many ways
you can implement this. Here is an example implementation snippet.
if (checkFeedback(getLinesWritten())) {
if(isBasic()) logBasic("linenr "+getLinesWritten());
}
It may make sense to use different row counters for checking the feedback size depending on the implementation logic of your step. For example, a step that accumulates incoming rows into one
single summary row, should probably use the linesRead counter to determine the feedback interval.
The Excel Output step has a good example implementation of feedback logging.
Add metadata injection support to your step
You can add metadata injection support to your step by marking the step meta class and the step’s fields with injection-specific annotations. You use the @InjectionSupported annotation to specify that your step is able to support metadata injection. Then, you use either the @Injection annotation to specify which fields in your step can be injected as metadata, or use the @InjectionDeep annotation for fields more complex than usual primitive types (such as string, int, float, etc.).
InjectionSupported
Use the @InjectionSupported annotation in your step meta class to indicate that it supports metadata injection. This annotation has the following parameters.
| Parameter | Description |
| localizationPrefix | Indicates the location for your messages in the <step_package>/messages/messages_<locale>.properties file. When the metadata injection properties are
displayed in PDI, the description for the field is retrieved from the localization file by the mask
<localization_prefix><field_name>. |
| groups | Indicates the optional name of the groups you use to arrange your fields. Your fields will be arranged in these groups when they appear in the ETL Metadata Injection step properties dialog. |
For example, setting the localizationPrefix parameter to “Injection.” for the “FILENAME” field indicates the <step_package>/messages/messages_Injection.FILENAME.properties file. This prefix and "FILENAME" field within the following @InjectionSupported annotation tells the system to use the key "Injection.FILENAME" to retrieve descriptions along with the optional “GROUP1” and “GROUP2" groups.
@InjectionSupported(localizationPrefix="Injection.", groups = {"GROUP1","GROUP2"})
If your step already has metadata injection support using a pre-6.0 method, such as it returns an object from the getStepMetaInjectionInterface() method, then you will need
to remove the injection class and getStepMetaInjectionInterface() method from the step meta class. After this class and method are removed, the method
getStepMetaInjectionInterface() is called from the base class (BaseStepMeta), and returns null. The null value indicates your step does not support pre-6.0
style metadata injection. Otherwise, if your step did not use this type of implementation, you do not need to add or manually modify this method to the step meta class.
Although inheritance applies to injectable fields specified by the @Injection and @InjectionDeep annotations, you still need to apply the @InjectionSupported annotation to any step inheriting the injectable fields from another step. For example, if an existing input step has already specified injectable fields through the @Injection annotation, you do not need to use the @Injection annotation for fields you inherited within the step you create. However, you still need to use the @InjectionSupported annotation in your step meta class even though that annotation is also already applied in the existing input step.
Injection
Each field (or setter) you want to be injected into your step should be marked by the @Injection annotation. The parameters of this annotation are the name of the injectable field and the group containing this field:
@Injection(name = "FILENAME", group = "FILE_GROUP") - on the field or setter
This annotation has the following parameters.
| Parameter | Description |
| name | Indicates the name of the field. If the annotation is declared on the setter (typical style setter with no return type and accepts a single parameter), this parameter type is used for data conversion, as if it was declared on a field. |
| group | Indicates the groups containing the field. If group is not specified, root is used when the field displayed in the ETL Metadata Injection step properties dialog. |
This annotation can be used either:
- On a field with simple type (string, integer, float, etc.)
- On the setter of a simple type
- In an array of simple types
- On a
java.util.Listof simple types. For thisListusage, type should be declared as generic.
Besides with these types, you need to understand special exceptions for enums, arrays, and data type conversions.
You can mark any enum field with the @Injection annotation. For enum fields, metadata injection converts source TYPE_STRING values into enum values of the same name. For your user to be able to use any specified values, all possible values should be described in the documentation of your metadata injection step.
Any @Injection annotation can be added to an array field:
@Injection(name="FILES") private String[] files;
The metadata object can also have a more complex structure:
MyStepMeta.java
public class MyStepMeta {
@InjectionDeep
private OneFile[] files;
public class OneFile {
@Injection(name="NAME", group="FILES")
public String name;
@Injection(name="SIZE", group="FILES")
public int size;
}
}
Metadata injection creates objects for each row from the injection information stream. The number of objects equals the number of rows in the information stream. If different injections (like NAME and SIZE in the example above) are loaded from different information streams, you have to make sure that the row numbers are equal on both streams.
You can convert from RowSet to simple type for a field with the DefaultInjectionTypeConverter class. Currently supported data types for fields are string,
boolean, integer, long, and enum. You can also define non-standard custom converters for some fields by declaring them in the 'converter' attribute of @Injection annotation. These custom
conversations are extended from the InjectionTypeConverter class.
InjectionDeep
Only the fields of the step meta class (and its ancestors) are checked for annotations, which works well for simple structures. If your step meta class contains more complex structures (beyond primitive types), you can use the @InjectionDeep annotation with an optional prefix parameter to inspect annotations inside these complex (not primitive) fields:
@InjectionDeep(prefix = "MyPrefix")
This annotation can be used on the array or java.util.List of complex fields.
The optional prefix parameter enables you to use a class in the @InjectionDeep annotation more than once and still keep unique metadata injection property names. For
example, MyStepMeta has more than one Info field. By specifying "FIRST" and "LAST" prefixes through the @InjectionDeep annotation, the metadata injection
property structures of "FIRST.NAME" and "LAST.NAME" can be uniquely identified:
public class Info {
@Injection(name = "NAME")
String name;
}
public class MyStepMeta {
@InjectionDeep(prefix = "FIRST")
Info first;
@InjectionDeep(prefix = "LAST")
Info last;
}
Generics
You can use generic object types in your declared variables, arrays, or lists.
Your step meta class must extend or implement a base which uses generics. For example, if
you have a base class named MyBaseMeta, which makes use of generic types,
you need to extend it within the step meta class:
@InjectionSupported(...)
public class MyMeta extends MyBaseMeta<String> {
}
Your base class (MyBaseMeta) could then be defined with any of the following generics:
public abstract class MyBaseMeta<T> {
@Injection(...)
T name;
@Injection(...)
T[] children;
@Injection(...)
List<T> additional;
}
ou can also use generics with the @InjectionDeep annotation. For example:
public abstract class MyBaseMeta<T> {
@InjectionDeep
T info;
@InjectionDeep
T[] children;
@InjectionDeep
List<T> additional;
}
Deploy step plugins
Procedure
Create a JAR file containing your plugin classes and resources
Create a new folder, give it a meaningful name, and place your JAR file inside the folder
Place the plugin folder you just created in a specific location for PDI to find.
Depending on how you use PDI, you need to copy the plugin folder to one or more locations as follows.- Deploying to the PDI client (Spoon) or Carte:
- Copy the plugin folder into this location: design-tools/data-integration/plugins/steps.
- Restart the PDI client. After restarting the PDI client, the new job entry is available for use.
- Deploying to the Pentaho Server:
- Copy the data integration plugin folder to this location: server/pentaho-server/pentaho-solutions/system/kettle/plugins/steps.
- Copy the business analytics plugin folder to this location: server/pentaho-server/pentaho-solutions/system/kettle/plugins/steps.
- Restart the server. After restarting the Pentaho Server, the plugins are available to the server.
- Deploying to the PDI client (Spoon) or Carte:
Sample step plugin
The sample Step plugin is designed to show a minimal functional implementation of a step plugin that you can use as a basis to develop your own custom transformation steps.
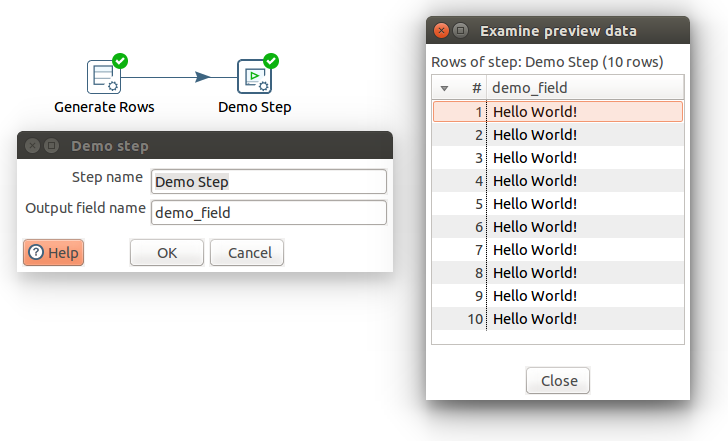
Procedure
Obtain the sample plugin source.
The plugin source is available in the download package. Download the package and unzip it. The job entry plugin resides in the kettle-sdk-step-plugin folder.Configure the build by opening kettle-sdk-step-plugin/build/build.properties and setting the kettle-dir property to the base directory of your PDI installation.
Build and deploy.
You may choose to build and deploy the plugin from the command line, or work with the Eclipse IDE instead. Both options are described below.- Build and deploy from the command line:
The plugin is built using Apache Ant. Build and deploy the plugin from the command line by invoking the install target from the build directory.
kettle-sdk-step-plugin $ cd build build $ ant install
The install target compiles the source, creates a JAR file, creates a plugin folder, and copies the plugin folder into the plugins/steps directory of your PDI installation.
- Build and deploy from Eclipse:
- Import the plugin sources into Eclipse:
- From the menu, select .
- Browse to the kettle-sdk-step-plugin folder and choose the project to be imported.
- To build and install the plugin, follow these steps:
- Open the Ant view in Eclipse by selecting from the main menu and select
Ant.
You may have to select if you have not used the Ant view before.
- Drag the file build/build.xml from your project into the Ant view, and execute the install target by double-clicking it.
- After the plugin has been deployed, restart the PDI client (Spoon).
- Open the Ant view in Eclipse by selecting from the main menu and select
Ant.
- Import the plugin sources into Eclipse:
- Build and deploy from the command line:
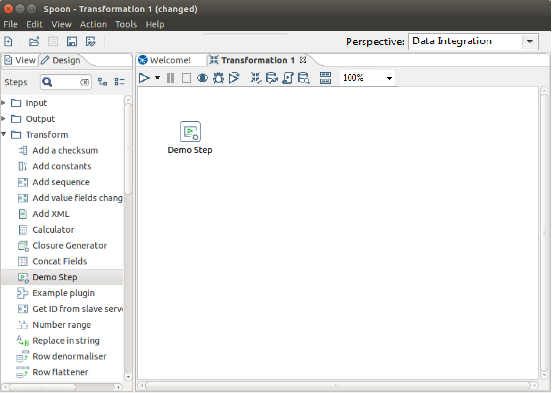
Open the PDI client, and verify that the new step is available as "Demo Step" in the Transform section.
Exploring more steps
PDI sources provide example implementations of transformation steps. Each PDI core step is located in a sub-package of org.pentaho.di.trans.steps found in the engine/src folder. The corresponding dialog class in located in org.pentaho.di.ui.trans.steps found in the ui/src folder.
For example, these are the classes that make up the Row Generator step.
org.pentaho.di.trans.steps.rowgenerator.RowGeneratorMetaorg.pentaho.di.trans.steps.rowgenerator.RowGeneratororg.pentaho.di.trans.steps.rowgenerator.RowGeneratorDataorg.pentaho.di.ui.trans.steps.rowgenerator.RowGeneratorDialog
The
dialog classes of the core PDI steps are located in a
different package and source folder. They are also assembled into a separate JAR file. This
allows PDI to load
the UI-related JAR file when launching the PDI client (Spoon) and avoid loading the UI-related JAR when it is not
needed.