Managing jobs

In Lumada Data Catalog, administrators can delegate data processing jobs to user roles. Depending on your role, you can perform administrative data cataloging and processing functions like profiling and tag propagation on data nodes.
For sources you can access based on your role and the permissions set by your system administrator, you can run a job either with a job template or with a job sequence. You can select sequences that Data Catalog provides, or if you have a privileged role, you can use custom job templates with your data assets.
Templates
You can use administrator-created job templates to run job sequences that apply to specific clusters. Job templates have system or Spark-specific parameters as command line arguments for the job sequences, such as driver memory, executor memory, or number of threads required based on a cluster size. You can override the default Data Catalog parameters. For example, you can set the incremental profile to false, profile a Collection as a single resource, or force a full profile instead of the default sampling option.
Contact your system administrator to determine the template that is best suited for your data cluster.
Sequences
You can use Data Catalog's job sequences to execute jobs. These jobs are executed with default parameters, and you cannot use the Sequence option to override the default parameters.
Guest-level users cannot run jobs. Stewards and analysts can only run jobs if the administrator has enabled job execution for their roles.
Run a job template on a resource
You can use a template when you run a Lumada Data Catalog job. A template is a custom definition for a given sequence, which may have a custom set of parameters.
For example, if you have a template with job format for asset path /DS1/virtualFolder/VFA and a custom parameter set [-X -Y -Z] is used to run the same job against a resource in /DS2/virtualFolder/VFB, only the asset path in the applied template is updated internally to reflect that of VFB.
The same applies to a dataset template. If you use a template with job format for an asset DSet1 and custom parameter set [-X -Y -Z] to run the same job against a resource in DSet2, only the asset name in the applied template is updated internally to reflect that of DSet2. To run a job template against a resource such as a virtual folder, dataset, or a single resource, follow the steps below.
Procedure
You need to run a job against a resource. From the main Data Catalog dashboard, click Browse Folders and drill down to the resource.
Click More actions and then select Run job now from the menu that displays.
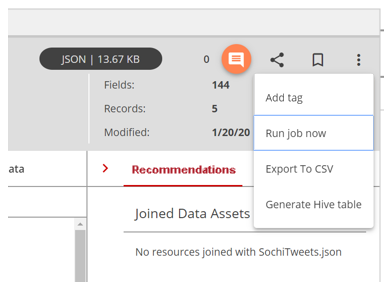 The Run Job Now dialog box
opens.
The Run Job Now dialog box
opens.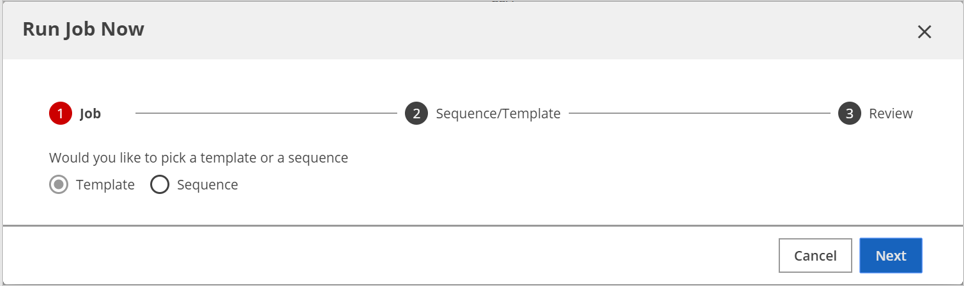
On the Job page, select Template and then click Next.
The job templates display. Note that the selected resource determines the available job templates.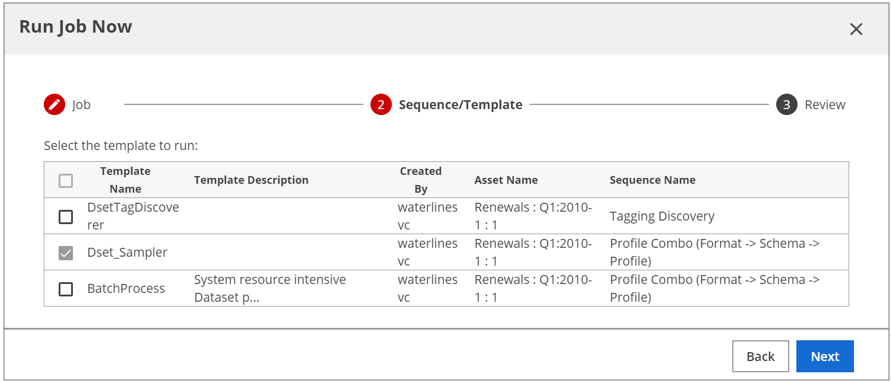
On the Sequence/Template page, select the check box next to the template that you want to run and click Next.
The Review page appears.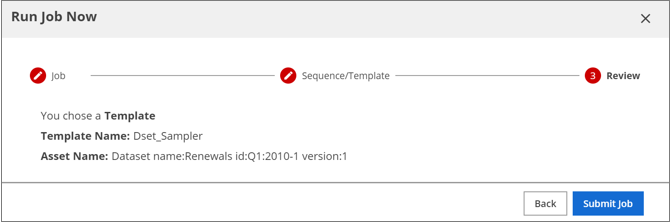
Review the job template you selected, and click Submit Job.
Results
Run a job sequence on a resource
You can use a sequence when you run a Data Catalog job.
Procedure
You need to run a job against a resource. From the main Data Catalog dashboard, click Browse Folders and drill down to the resource.
Click More actions and then select Run job now from the menu that displays.
The Run Job Now dialog box
opens.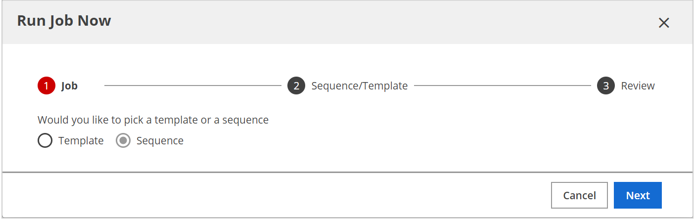
On the Job page, select Sequence and click Next.
The job sequences display. Note that the selected resource determines the available job sequences.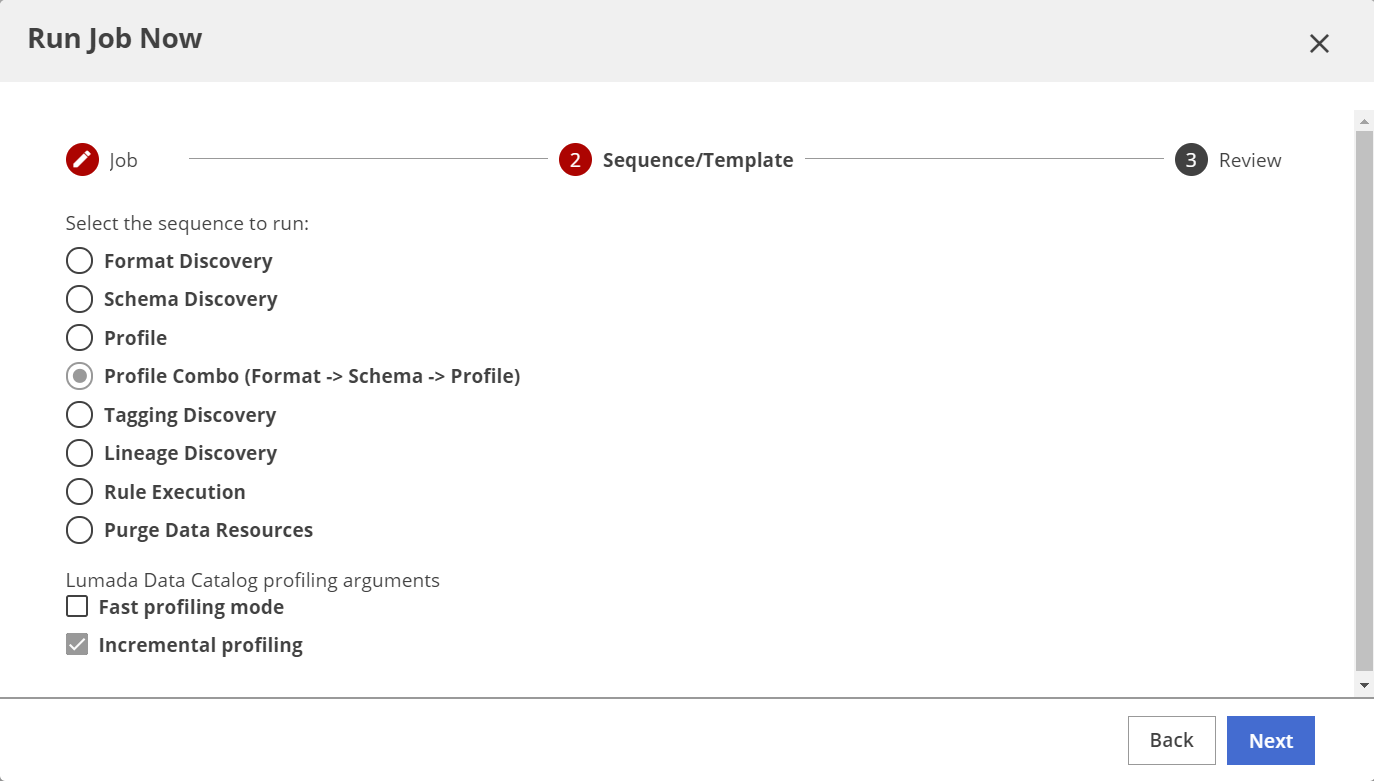
On the Sequence/Template page, select the type of job sequence to run, and click Next.
The Review page appears.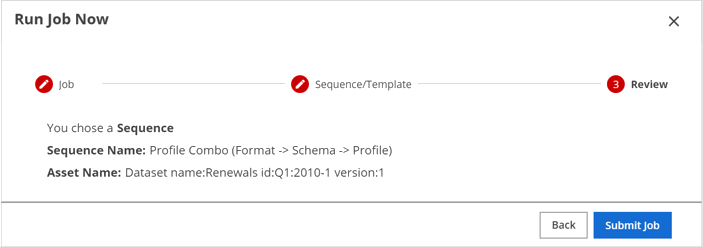
Review the job sequence you just selected, and click Submit Job.
Results
Monitoring job status
You can see job status for the jobs you executed on the Jobs tab of the User Profile page:
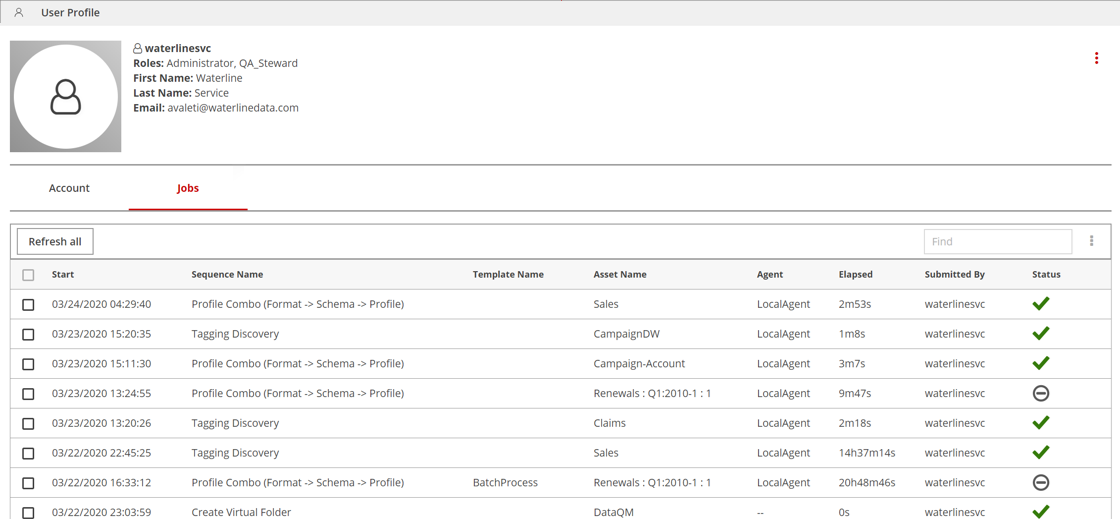
The Jobs tab lists job submission details. You can sort the job status by clicking any table column header except Asset Name. Note that only template jobs include entries for Template Name.
For each job, one of following job status icons display in the Status column:
| Icon | Meaning |

| Submitted/Initialized: Not yet started |

| In-progress: Currently processing |

| Success: 100% complete with no errors |

| Success with warnings: Possible errors |
| Cancelling/Cancelled: User cancelled jobs |

| Skipped: Job may not match the resources |

| Failed: Not processed due to error |

| Incomplete: includes error Numbers indicate (total file skips + incompletes / total files) |
You can display the latest status of any job by clicking the Refresh all button to reload the Jobs pane without having to refresh the browser.
Monitor job status
Procedure
On the main Lumada Data Catalog menu bar, click the User icon and select Profile settings.
On the User Profile page, click the Jobs tab.
The Job activity grid appears.(Optional) If needed, you can refresh the status display by clicking Refresh all.
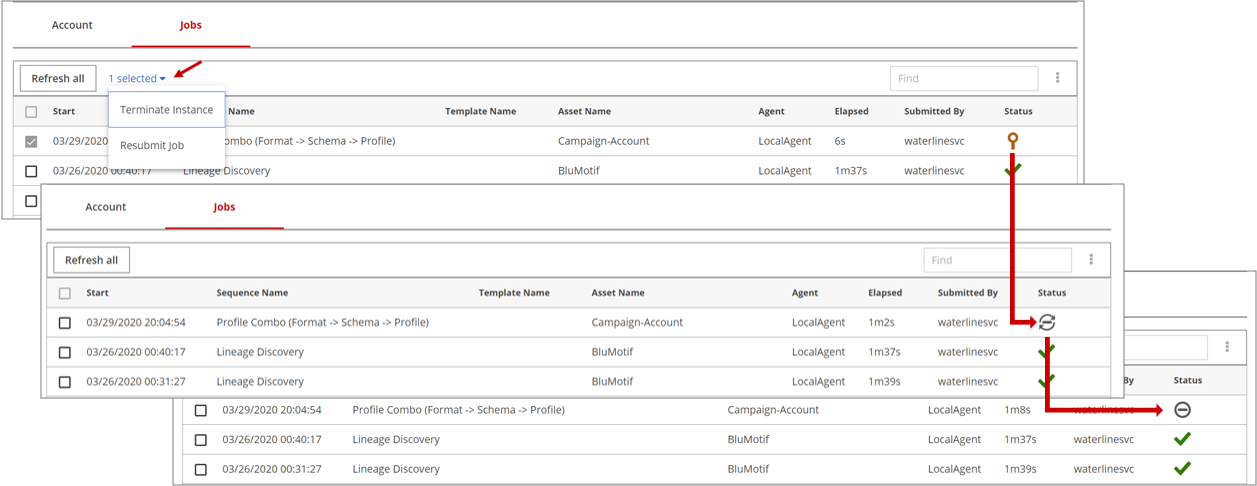
(Optional) If needed, you can resubmit a job:
Select the check box next to the job.
A selected link appears.Click .
Terminate a job
Follow the steps below to terminate a job.
Procedure
On the main Lumada Data Catalog menu bar, click the User icon and select Profile settings.
On the User Profile page, click the Jobs tab.
Select the check box for the job you want to terminate.
A selected link displays next to the Refresh all button.Click the link and select Terminate Instance.
Click Refresh all to update the job status.
Results
View job information
When you click the row of a particular job, a Job Info pane appears on the right side detailing the execution information.
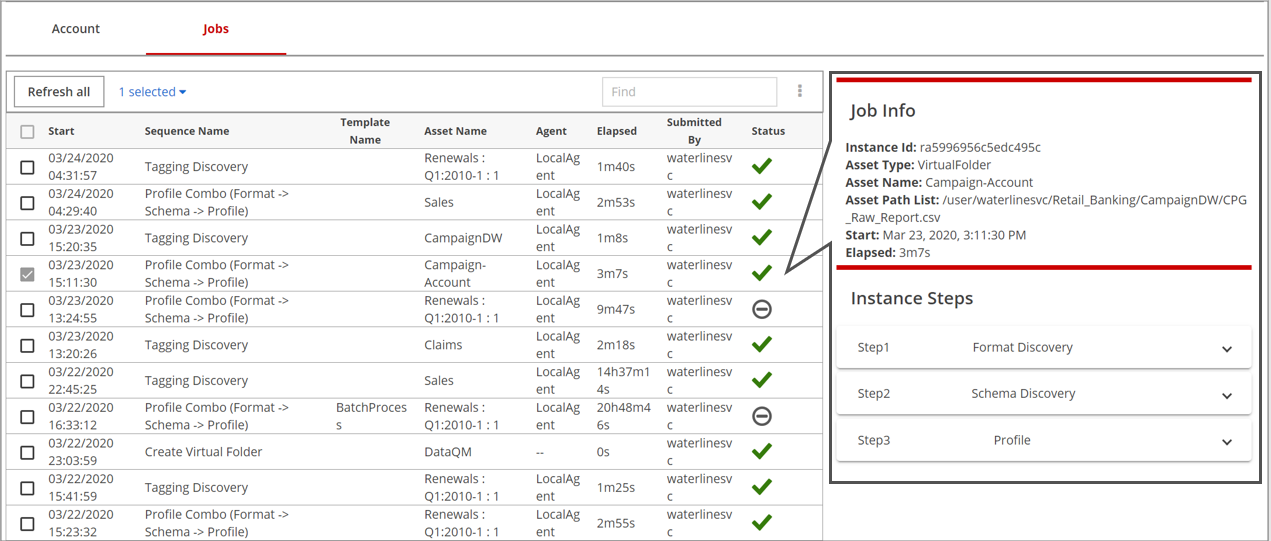
In the example above, the sequence is Profile Combo, which has three instance steps listed in the Job Info pane in the order they execute: format discovery, schema discovery, and profile.
To view the individual sequence details, you can click the down arrows in the Job Info pane.
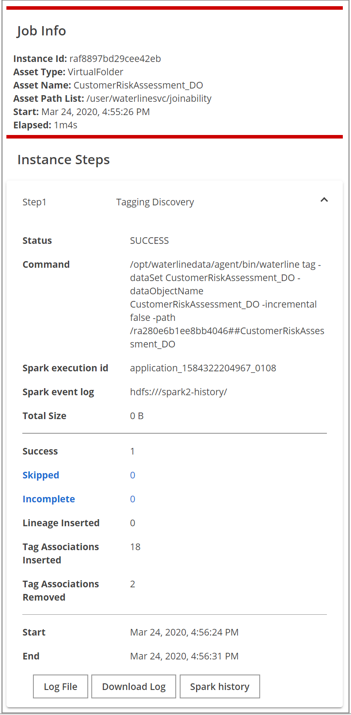
The Job Info pane provides the execution details of the sequence, as described in the table below:
| Fields | Description |
| Status | Lists the status of the sequence in run time, as follows:
|
| Command | Lists the command executed, including the optional parameters used, if any. |
| Total Size | Size of the data asset that was processed. |
| Success | The number of resources within the data asset that were processed successfully. A negative value indicates INITIAL/IN PROGRESS status. This value is only updated after job execution. |
| Skipped | The number of resources within the data asset that Data Catalog skipped, either because of a corrupt resource or an unsupported format. |
| Incomplete | The number of resources within the data asset that could not finish discovery due to issues. |
| Start | The recorded start time. |
| End | The recorded end time. |
If the Skipped or Incomplete counts are '1' or more, you can click them for details about the skipped or incomplete resources. These lists are also shown in paginated form to improve the response time for large numbers of skipped or incomplete resources.
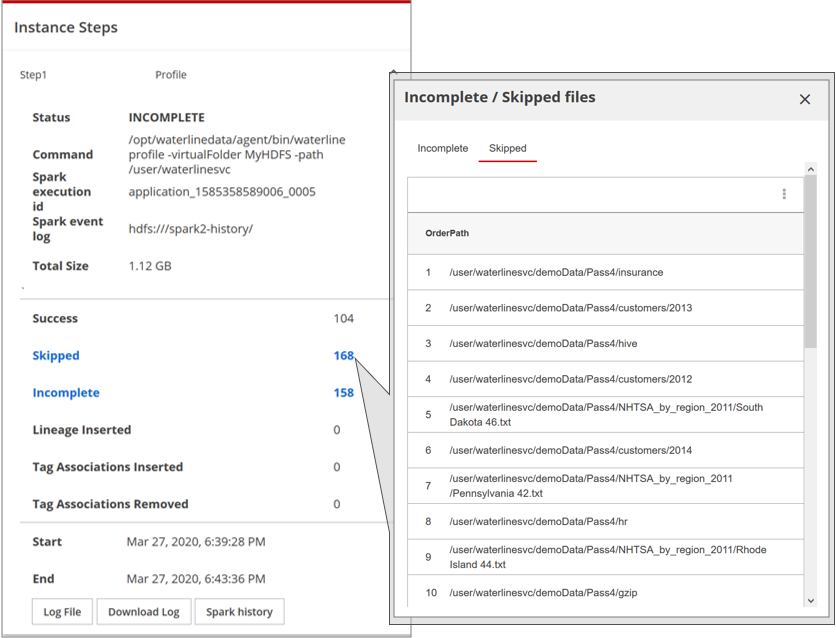
Read job info
Procedure
On the main Lumada Data Catalog menu bar, click the User icon and select Profile settings.
On the User Profile page, click the Jobs tab.
To select a job, click the job row.
NoteIf you click the check box on a job row, the Job Info pane does not open.
The Job Info pane opens on the right side, listing the details for that job instance.To view more details about the individual instance, click the down arrow to expand the section.