Installing Lumada Data Catalog on GCP Dataproc

You can install Lumada Data Catalog on Google Cloud Platform™ (GCP) Dataproc to access GCP™ data.
Deployment architecture
As a best practice, you should install Data Catalog in the following typical deployment architecture for GCP Dataproc.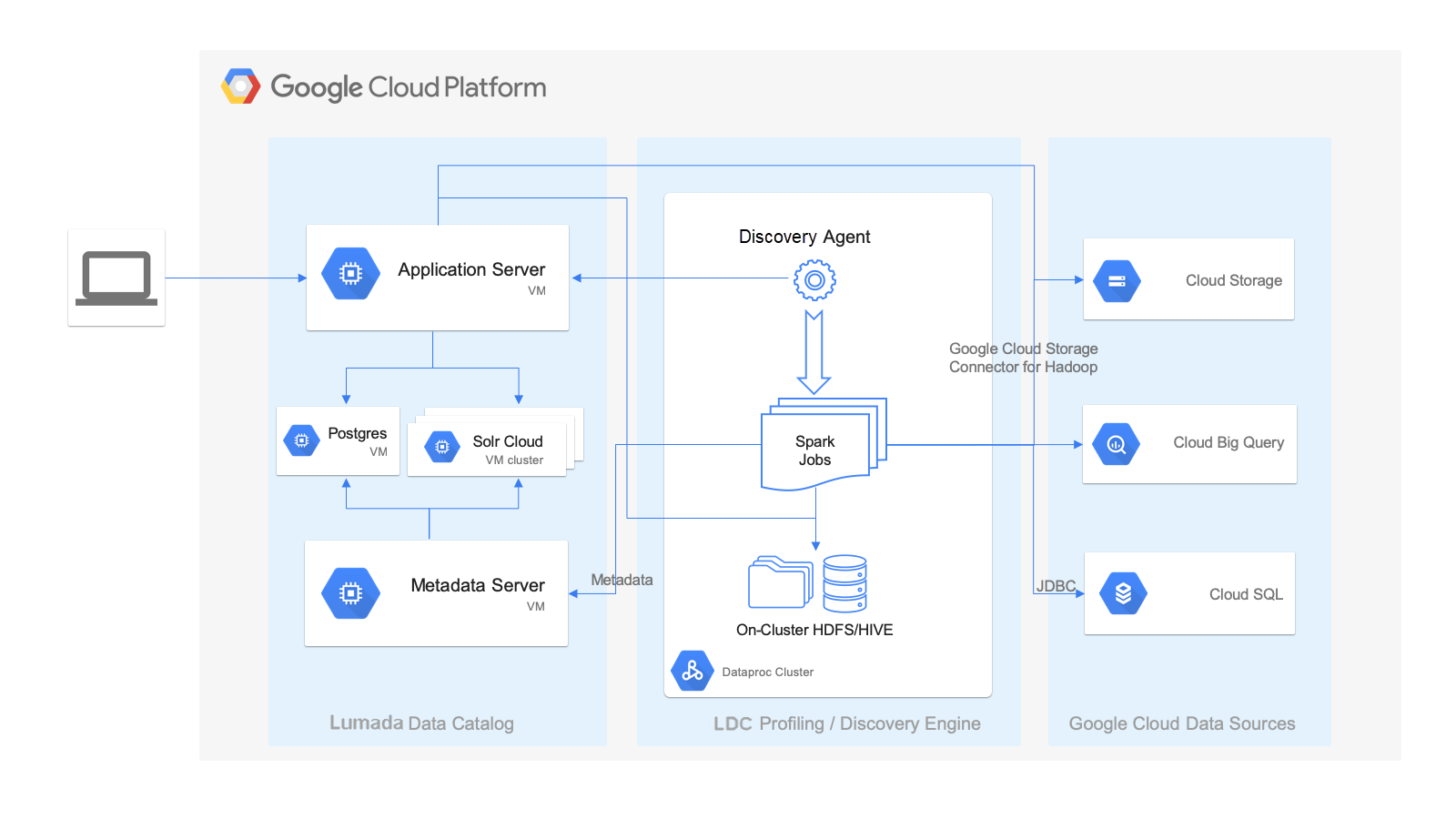
This deployment architecture contains the following key features of the Data Catalog installation within this environment:
- Data Catalog hosts the Lumada Data Catalog Application Server, Lumada Data Catalog Metadata Server, Solr, and Postgres components in a dedicated set of virtual machines (VMs). For sizing, see Minimum node requirements). End users connect to the LDC Application Server endpoint to access Data Catalog.
- An edge node of the Dataproc cluster hosts the Lumada Data Catalog Agent, which is responsible for data discovery using Spark jobs and publishing the metadata back to the centralized catalog using the LDC Metadata Server endpoint.
- Both the LDC Application Server and the Discovery (LDC Agent) components connect to various data sources in the Google cloud environment.
Networking and performance considerations
As you plan to install Lumada Data Catalog, remember the following networking and performance considerations:
- The Dataproc cluster must be in a region closest to where the data is located. For example, if your storage bucket is in the us-west-2 region, the Dataproc cluster should be in the same region for high bandwidth and low latency access to the data. While it is possible to have cross region or zone access to data, performance will be severely affected.
- All components of the centralized Data Catalog must be co-located in the same network subnet. The LDC Application Server and LDC Metadata Server need low latency access to Solr and Postgres.
- If all your data is in a single region or zone, then all the Data Catalog components must be co-located in the same region or zone for best performance. You can deploy the Data Catalog components in a different region or zone than the Dataproc cluster if you have multiple Dataproc clusters in different regions.
Before you begin
Before you begin installing Data Catalog on GCP Dataproc, you must create GCP resources and install Solr and Postgres:
Create GCP resources
Procedure
Under IAM, create a service principal user named
ldcuserto act on behalf of Data Catalog. See Configure the Data Catalog service user.Grant the
ldcuseruser access to your data.Create a key in JSON format and download it for later use.
Create VMs to host the LDC Application Server and the LDC Metadata Server. For specifications and sizing, see Minimum node requirements.
Create a Dataproc cluster using Cloud Console or CLI. See Minimum node requirements.
Create or designate a folder in any cloud storage bucket to store Data Catalog fingerprints (large properties) and grant read, write, and execute access to the service principal.
Downloading and installing Solr
Download and install Solr by performing the Solr installation directions detailed under Installing standalone Solr.
Downloading and installing Postgres
You can use any PostgresSQL instance available in the same network subnet or region. The convenience package installs the recommended 11.9 version. The following options are possible:
- Postgres convenience package (simplest)
- Fully managed Google Cloud SQL for PostgreSQL.
- Yum, Ubuntu or Debian repositories.
Installing Data Catalog
To install Data Catalog on GCP Dataproc, you must install the following components:
Install the LDC Application Server
Perform the steps in Install the Lumada Data Catalog Application Server and below:
Procedure
Obtain the access keys for the Google Cloud Storage (GS://) service account from the IAM section on Google Cloud Console.
Place them on the LDC Application Server VM (for example, under Data Catalog's /conf directory).
Create the /opt/ldc/app-server/conf/core-site.xml file or edit an existing file with the following content as shown below:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.AbstractFileSystem.gs.impl</name> <value>com.google.cloud.hadoop.fs.gcs.GoogleHadoopFS</value> <description>The AbstractFileSystem for gs: uris.</description> </property> <property> <name>fs.gs.project.id</name> <value></value> <description> Optional. Google Cloud Project ID with access to GCS buckets. Required only for list buckets and create bucket operations. </description> </property> <property> <name>google.cloud.auth.service.account.enable</name> <value>true</value> <description> Whether to use a service account for GCS authorization. Setting this property to `false` will disable use of service accounts for authentication. </description> </property> <property> <name>google.cloud.auth.service.account.json.keyfile</name> <value>/path/to/keyfile</value> <description> The JSON key file of the service account used for GCS access when google.cloud.auth.service.account.enable is true. </description> </property> </configuration>Restart the LDC Application Server using the following command:
/opt/ldc/app-server/bin/app-server restart
Installing the LDC Metadata Server
Install the LDC Metadata Server by performing the general installation instructions for the Install the Lumada Data Catalog Metadata Server.
Install the LDC Agent
Procedure
Follow the general installation instructions for LDC Install Lumada Data Catalog Agents.
Copy the following JAR files:
mv /opt/ldc/agent/lib/dependencies/curator-*.jar /tmpmv /opt/ldc/agent/lib/dependencies/guava-19.0.jar /tmpDownload the following JAR files:
wget https://repo1.maven.org/maven2/com/google/guava/guava/28.1-jre/guava-28.1-jre.jar -P /opt/ldc/agent/lib/dependencies/wget https://repo1.maven.org/maven2/org/apache/curator/curator-client/4.2.0/curator-client-4.2.0.jar -P /opt/ldc/agent/lib/dependencies/wget https://repo1.maven.org/maven2/org/apache/curator/curator-framework/4.2.0/curator-framework-4.2.0.jar -P /opt/ldc/agent/lib/dependencies/wget https://repo1.maven.org/maven2/org/apache/curator/curator-recipes/4.2.0/curator-recipes-4.2.0.jar -P /opt/ldc/agent/lib/dependencies/wget https://repo1.maven.org/maven2/com/google/guava/failureaccess/1.0.1/failureaccess-1.0.1.jar -P /opt/ldc/agent/lib/dependencies/Configure the
core-site.xmlfile properties for the LDC Agent.
Results