Product overview
The Lumada Data Catalog software builds a metadata catalog from data assets residing in tools such as HDFS, Hive, MySQL, Oracle, Redshift, S3, and Teradata. It profiles the data assets to produce field-level data quality statistics and to identify representative data so users can efficiently analyze the content and quality of the data.
Data Catalog's interactive user interface provides a customized user experience for the business role of every user, promoting rich content authoring and resource knowledge.
Business Glossary
Data Catalog gives users access to the file and field-level metadata available for the entire catalog of data assets. In addition, for the assets that each user has authorization to view, Data Catalog displays a rich view of data-based details such as minimum, maximum, and most frequent values. Data Catalog users can add their own information to the catalog in the form of descriptions, custom properties, and custom metadata designed for their organization. With the proper permissions, users can add workflows to business glossaries to require that business terms are added to, updated in, or removed from a glossary only after a review process.
Business Terms
Data Catalog provides an interface for users to tag data with information about its business value. It distributes these tags or terms to similar data across the cluster, producing a powerful index for business language searches. It enables business users to find the right data quickly and to understand the meaning and quality of the data at a glance. Users can define relationships between business terms to provide clarity on related data. For example, data tagged with the term National ID can be set as a synonym of a US Social Security Number (SSN) term. Users can also search for business terms using a global keyword search.
Lineage
Data Catalog displays lineage relationships among resources using imported metadata. In addition, Data Catalog can infer lineage relationships from the metadata collected in discovery profiling.
User roles
Roles assigned to Data Catalog users let administrators exercise role-based functional and access control for those users, such as who can create business terms and who can approve or reject the metadata suggested by Data Catalog discovery operations. In addition, you can use roles to establish access control over Data Catalog resources at the data source level. Roles also incorporate a set of predefined access levels that define which features of the catalog are available to different users.
Access control
User profiles, roles, and access restrictions combine to deny or grant metadata access to users.
Data Catalog features a distributed architecture, where the processing engine is replaced by processing agents that can run on multiple remote clusters while the application server and the metadata repository reside in a centralized location. This single unified catalog is fed from multiple distributed data sources, including multiple Hadoop clusters and relational databases. The metadata collected from processing functions is stored in a MongoDB repository, which typically resides with the application server in a centralized location.
The following diagram provides an overview of Data Catalog's architectural components across the distributed application.
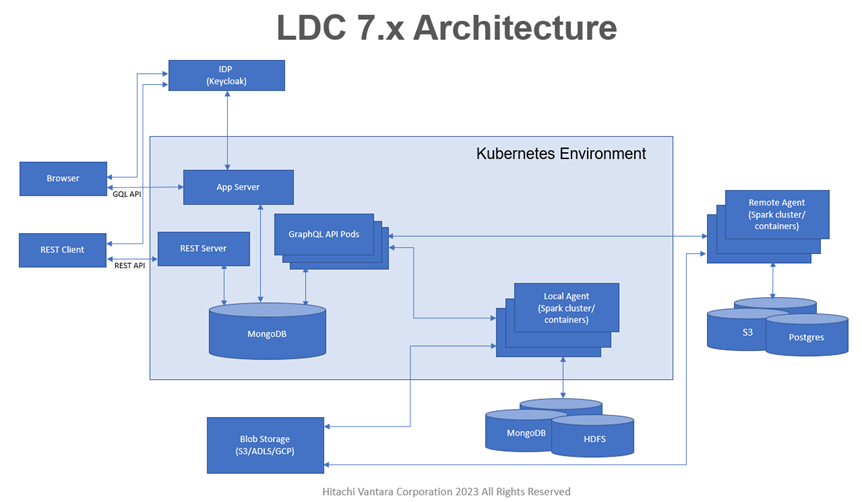
Data Catalog includes the following main components:
Application server
This server hosts the user interface that interacts with Data Catalog to browse the data, initiate jobs and perform business analytics on the processed data.
REST server
A REST server supports the Data Catalog REST APIs.
Agents
Agents are responsible for initiating, executing, and monitoring jobs that communicate with the data sources and process the data and create fingerprints.
Repository
The metadata storage for Data Catalog.
Data Catalog runs profiling jobs against HDFS and Hive data using Spark. The application code is transferred to each cluster node so it can be executed against the data that resides on that node. The results are accumulated in MongoDB or, in the case of deep profiling, in HDFS files. Data Catalog runs Spark jobs against the resulting metadata to suggest business terms for association.
It is important to understand that Data Catalog jobs are standard Spark jobs: the expertise your organization already has for tuning cluster operations applies to running and tuning Data Catalog jobs.
Because these jobs read all the data in assets included in the catalog, the user running the jobs needs to have read access to the data. Make sure to configure the Data Catalog service user with security in mind to ensure this broad access is properly controlled.
Data Catalog profiles data in an HDFS cluster, including HDFS files and Hive tables. In addition, Data Catalog profiles data in relational databases accessible through JDBC. It collects file and field-level data quality metrics, data statistics, and sample values. The catalog includes rich metadata for delimited files, JSON, ORC, Avro, XML, and Parquet and from files compressed with Hadoop supported compression algorithms such as gzip and Snappy.
The first part of the process is identifying the data sources you want to include in your catalog. Then Data Catalog's profiling engine reads the data sources and populates the catalog with metadata about the resources, such as databases, tables, folders, and files, in each data source.
XML
Data Catalog processes XML files that are constructed with a single root element and any number of repeating row elements. Administrators can specify the root and row elements if Data Catalog does not identify the correct elements.
Delimited text files
Data Catalog format discovery determines how data is organized in a file. For a text file to be profiled as data, each row is assumed to be a line of data. If there are lines in the file that are not data (such as when no delimiter is found), Data Catalog does not profile the file. For example, if there are titles, codes, or descriptions at the top or bottom of a text file, Data Catalog categorizes the file as plain text and does not profile it.
Unstructured files
Data Catalog can perform scanning, profiling, and business term tagging for unstructured files in a number of file types including Microsoft Excel and PowerPoint, and Apache OpenOffice formats. Data Catalog can also detect the language of supported unstructured data types.
Data Catalog can include Hive tables in the catalog. This level of interaction with Hive requires some manual configuration and privileges.
Hive authorization
Profiling Hive tables requires that the Data Catalog service user has read access to the Hive database and table. Browsing Hive tables requires that the active user is authorized to access the database and table and the Data Catalog service user has read access to the backing file. Creating Hive tables requires that the active user can create tables in at least one Hive database and has write access to the folder where the source files reside.
Hive authorization on Kerberized cluster
During profiling, Data Catalog interacts with Hive through the metastore. In a Kerberized environment, typically the only user allowed to access Hive data through the metastore is the Hive superuser. To perform this operation, Data Catalog needs the following configurations:
- The Hive access URL must include the Hive superuser principal name.
- The Data Catalog service user must be configured as a proxy user in Hadoop so it can perform profiling operations as the Hive superuser.
Profiling tables and their backing files
When Data Catalog profiles Hive tables, it uses the Hive metadata to determine the backing directory for each table and includes that directory and constituent files, whether or not those files have been profiled. It also includes a lineage relationship between the Hive table and these backing files. By default, it does not profile the backing HDFS files. If you choose to independently profile the backing files, it is possible that Data Catalog will show different views for the same data based on the input formats and parsing used for the HDFS file itself and for the Hive table. For example, the Hive table may have different column names, a subset of columns or rows, and may use a different delimiter to determine the fields within each row of data.
Data Catalog can include data from relational data sources in the catalog. Administrators can connect through JDBC to Aurora, MongoDB, MSSQL Server, MySQL, Oracle, Redshift, SAP-HANA, Snowflake, or Teradata databases. After the data source or logical table is created, it can be processed and viewed as any other database or Hive table.
Profiling against these data sources involves a full pass through the tables, so there is no option to only profile new or updated resources.
While the Data Catalog does not ingest data directly from SQL functions or stored procedures, it does have adapters to import SQL from Hive through Apache Atlas.