Browsing Data Catalog assets

In Lumada Data Catalog you can create several virtual data units that make it easier for you to manage the underlying data in your data lake.
Virtual folders
A virtual folder is a group of resources with the same data source type. Because data resources can be part of multiple virtual folders, virtual folders can have overlapping sets of data resources.
Collections
A collection is a group of files with the same format and schema that Data Catalog recognizes, arranges hierarchically, and categorizes during profiling.
Datasets
A dataset is a user-defined collection of resources with the same schema that may reside in different folders in your data lake.
Data objects
Data objects are virtual resources you create by defining a set of join conditions between resources.
Use this article to learn how non-admin users can access and manage these data units based on their access level. For administration level management, see the Manage.
Browsing virtual folders
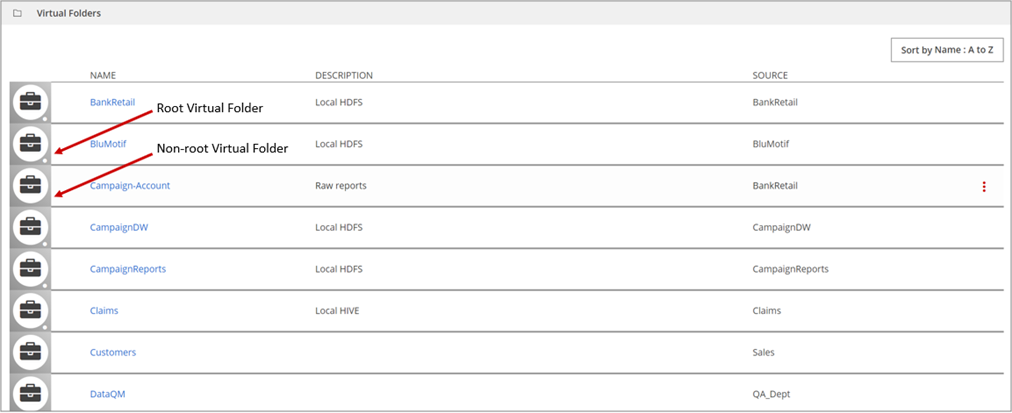
When you create a data source, Data Catalog also creates its corresponding top level virtual folder, which is referred to as the root virtual folder. This virtual folder includes all the resources that are part of the data source connection that you added.
The Data Catalog file browsing view provides tools for navigating the logical folders designated at your access level, as well as for exploring the structure and content of the files or tables.
| Icon | Meaning |
 | A non-root virtual folder. |
 | A dot at the bottom right indicates a root virtual folder. |
As a best practice, include the data source type in the virtual folder description. At this level, the description may be the only way to communicate the data source type (Hive/HDFS/JDBC).
Export your findings to a CSV file
Perform the following steps to export your findings to a CSV file.
Procedure
Click Export as CSV or Export Table as CSV to start generating the export data.
The Export CSV Settings dialog box displays.Select which properties to export for each resource. Click Select All to include all the properties listed.
Click Export to generate the data.
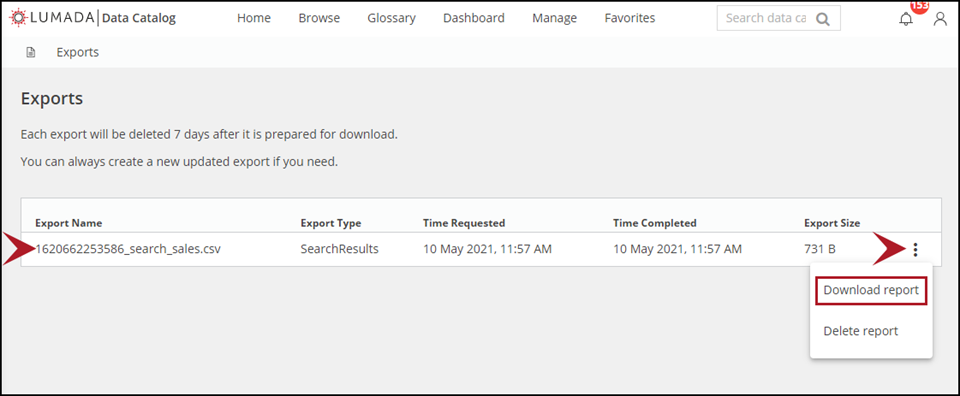
After the CSV data values are successfully generated, a confirmation message appears in the header with an exports link.If you are ready to download the generated information at this point, click exports in the header message.
The Exports page opens. This page provides a summary of your exported reports, including the report name, the report type (from where is was generated), the generation interval, and the report size. Any report listed here is automatically deleted within seven days from the time the report is generated.NoteIf you want to wait until later to download the generated CSV data, you can access the Exports page through the Exports option in your User Profile menu.From the reports table, click More actions, and then select Download report.
 The generated CSV file is downloaded to the location specified for the
Path to exports configuration property during your
installation of Data Catalog. See Managing configurations if you need to reconfigure the Path
to exports property to a different location.
The generated CSV file is downloaded to the location specified for the
Path to exports configuration property during your
installation of Data Catalog. See Managing configurations if you need to reconfigure the Path
to exports property to a different location.(Optional) To delete a report, click More actions, and then select Delete report.
Results
Repository-only browsing
You can browse data resources that have already been created in the Data Catalog repository, which is called repository-only browsing. For many users, this practice makes browsing more responsive because it eliminates the need to create time-consuming connections to remote data sources. When browsing the repository, the resource type, any tags, and available field counts are displayed. You can apply filters and export this information. See Export your findings to a CSV file.
Because repository-only browsing along with caching can provide stale information about the data resources in a data sources, use the Refresh button to refresh the list of data resources from a source when new resources have been added to or removed from the data source.
Hive-JDBC table browsing
If you drill down one level from the Home page, a virtual folder with a HIVE or JDBC source may look like the following:
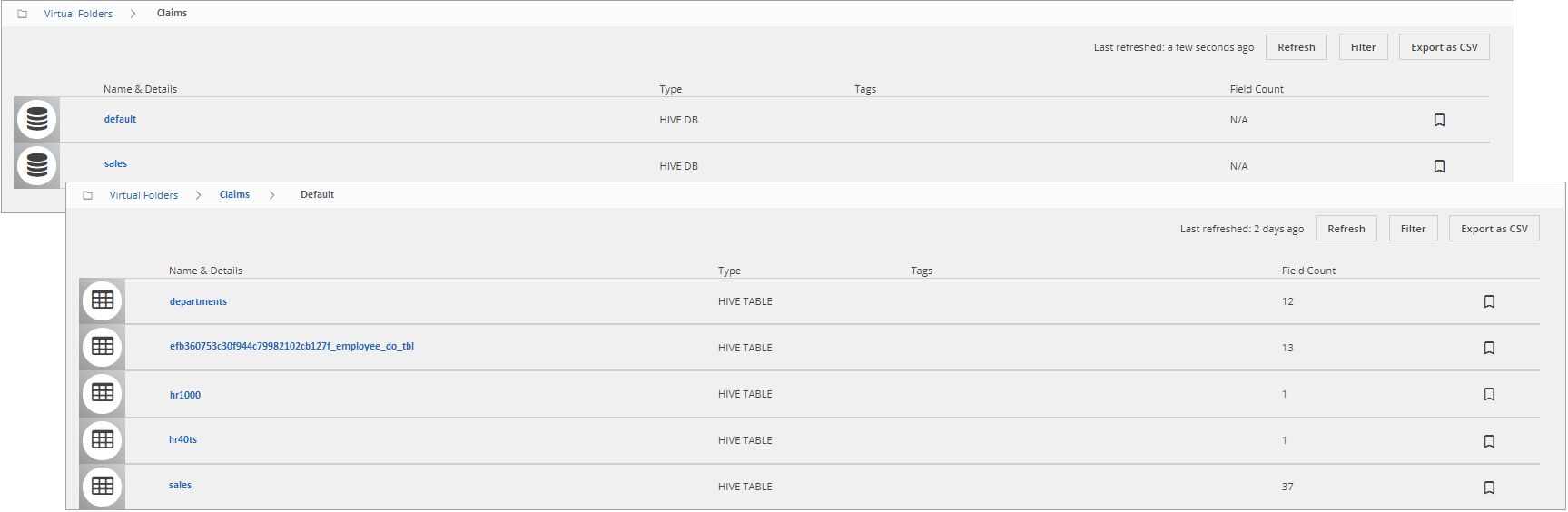
In this example, the icons indicate the following conditions:
| Icon | Meaning |
 | Database |
 | Table |
 | A HIVE or JDBC view |
HDFS file browsing
If you drill down one level from the Home page, a virtual folder with HDFS or S3 source may look like the following:

In this example, the icons indicate the following conditions:
| Icon | Meaning |
 | Folder/Directory |
 | File |
Browsing collections
In Data Catalog you can view a set of data that extends across multiple files as a single resource, or in a collection.
When you add files to one of the directories identified as part of the collection, Data Catalog needs to run schema and profile discovery to reflect the newly added data in the collection.
When a folder becomes a collection, the files inside the folder no longer appear individually in search results. Instead, search results show a single representation of all the files. The collection can be made up of files in a single folder or files in many folders all under a single top-level folder.
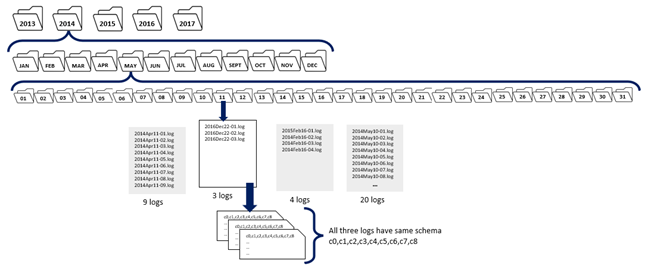
Data Catalog can discover sets of data for collections based on these criteria:
- At least three files exist in a directory or in each subdirectory (the number of files is controlled by a Data Catalog configuration setting, please see Install and the Manage).
- The files have the same file type.
- The files have the same schema.
Collections are indicated with the collection icon: 
To view the list of files in the collection, click the More actions menu (icon) and select the View as list option. The individual files are members of the collection.
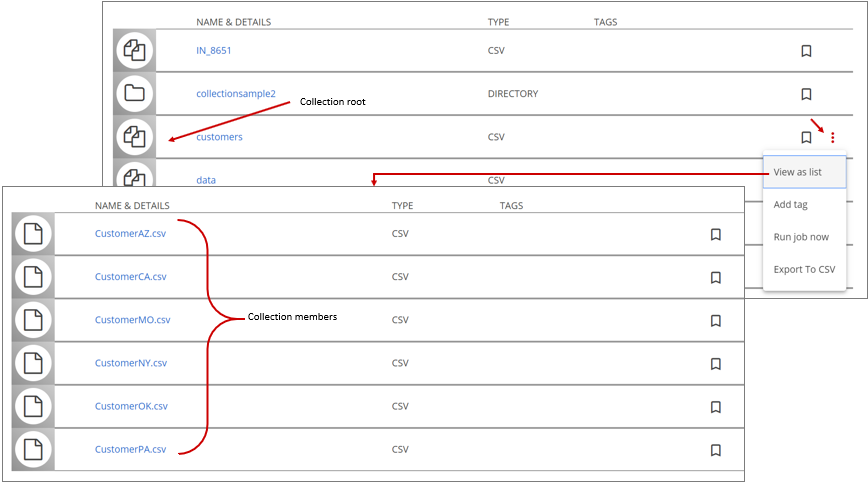
Typically, Data Catalog identifies multi-level collections in the collection discovery process.
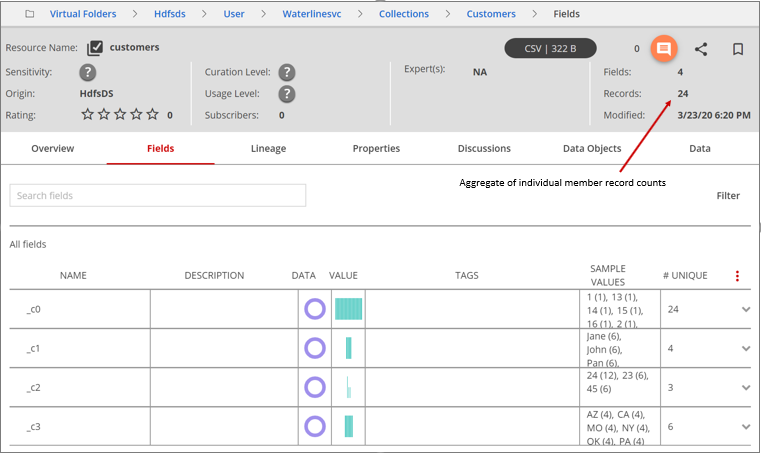
The single resource view of a collection is similar to any other resource in the Data Catalog with a few exceptions noted below:
- The total number of records shown for a collection is an aggregate of the number of records of the individual member resources of the collection.
- The field tags can be applied only at the collection level. Once a resource is identified as a collection member, its fields cannot be tagged separately and the members do not individually participate in the tag discovery. This condition also applies if a collection member is a member of a dataset.
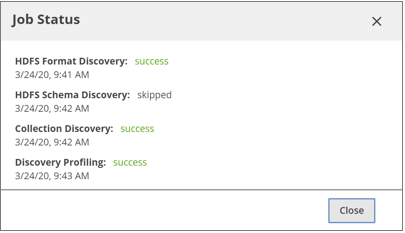
Note that the Job Status dialog box lists Collection Discovery as a separate job entry. Data Catalog runs collection discovery internally after identifying a set of resources as a collection at the HDFS schema discovery stage.
Browsing datasets
A dataset is a user-defined collection, created by grouping resources with the same schema that may reside in different virtual folders in your data lake. The individual resources are member resources.
Click to view a summary of the data in the member resources.
In the Datasets window, you can view the dataset name, ID, and schema version along with a description of each resource. Together, the dataset name, dataset ID, and schema version form the unique identifiers of the dataset. To drill down, select a resource to open the Fields page.
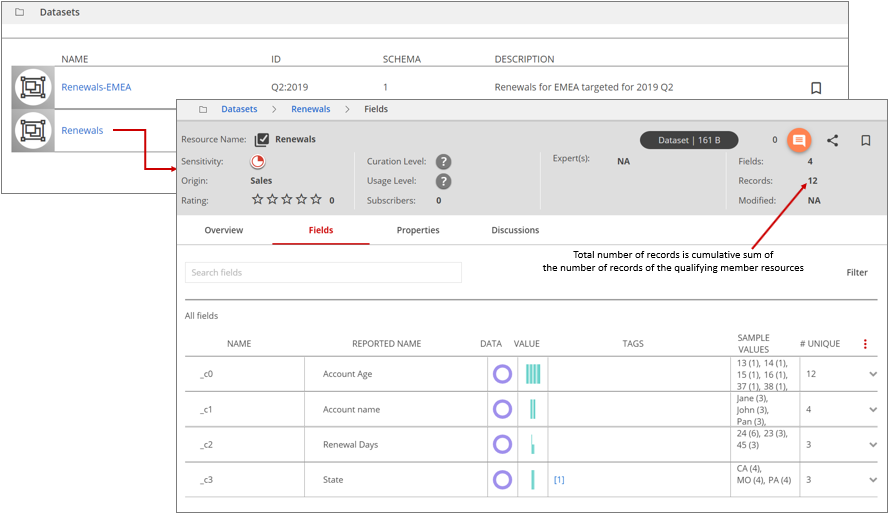
On the right side of the header, you can view the pertinent details for the resource.
File size
For a dataset, indicates the sum of the file sizes of the included member resources.
Status
For a dataset, indicates if the dataset is profiled.
Fields
Indicates the number of fields in the discovered schema, taken from the reference resource or member resource with the oldest timestamp.
Records
Indicates the total number of records. This total is a cumulative sum of the number of records of the qualifying member resources.
Origin(s)
On the left side of the header, you can view the source virtual folder for the dataset.
Under All fields, you can view the member details of the resource:
NAME
is the name of the fields as they appear in the discovered schema of the reference resource.
REPORTED NAME
is the name specified for the fields in the Reported Schema for the dataset.
NoteReported Schema is currently used only for display purposes. Data Catalog does not perform schema comparison between discovered and reported schemas at this time.DATA, VALUE, TAGS, SAMPLE VALUES, #UNIQUE, #ROWS
are cumulative values of the respective member resources fields.
Browsing dataset member resources
Much like the collections resource, you can view the member resources of datasets. Click the Action menu (icon) and then click View as list.
You can access the Action menu (icon) from either the list view or the dataset SRV (Single Resource View).
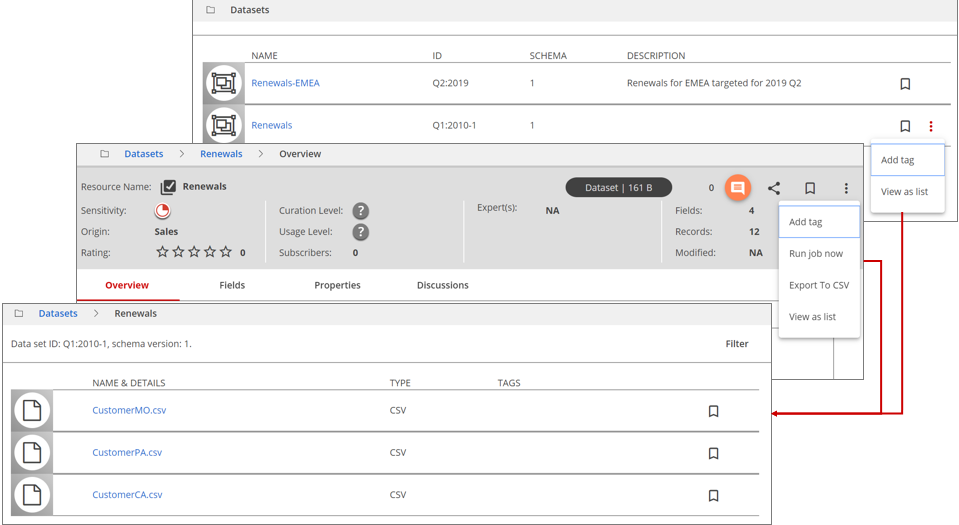
Click the member resource to drill down to the individual page's single file view.
Dataset access control
You can delegate dataset management to custom roles, which will have control over dataset name, description, schema versions, reported schema, and path specifications.
While only an admin user can create a dataset, a non-admin user with a custom role can manage the following dataset properties:
- Name
- Description
- Path specification
- Reported schema
A non-admin user with a custom role can also perform dataset tasks such as:
- Add/remove resource
- Add tag
- View as list
Browsing Data Objects
Data objects are virtual resources created by defining a set of join conditions between resources. For example, you may have access to multiple resources, such as one that tabulates the employee contact information, one that tabulates employee skills, and another that tabulates employee assignments for a particular project. If you want to gather contact information for all employees assigned to a project and their skills set, then you can use the Data Objects menu to build a data object by defining join conditions between these resources.
You can direct these join conditions in two ways:
- As suggested by Data Catalog, inferred from tag associations.
- With user-defined joins (single or composite).
You can then profile, tag, search, and browse the new data object like any other resource in the Data Catalog. For a more visual interpretation, you can click Graph View to view the data object as a map, graphing the relationships between all the resources participating in the data object.
With the Data Catalog's interactive Data Objects interface, you can browse the possible join paths and profile the data object to assess its correctness and relevance.
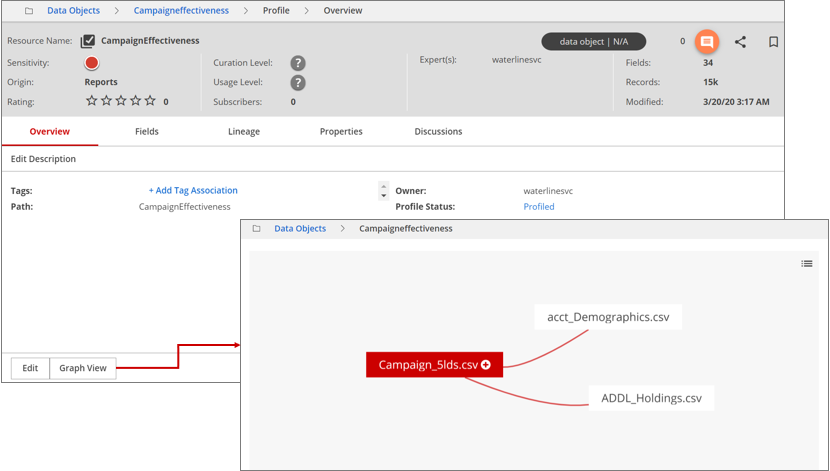
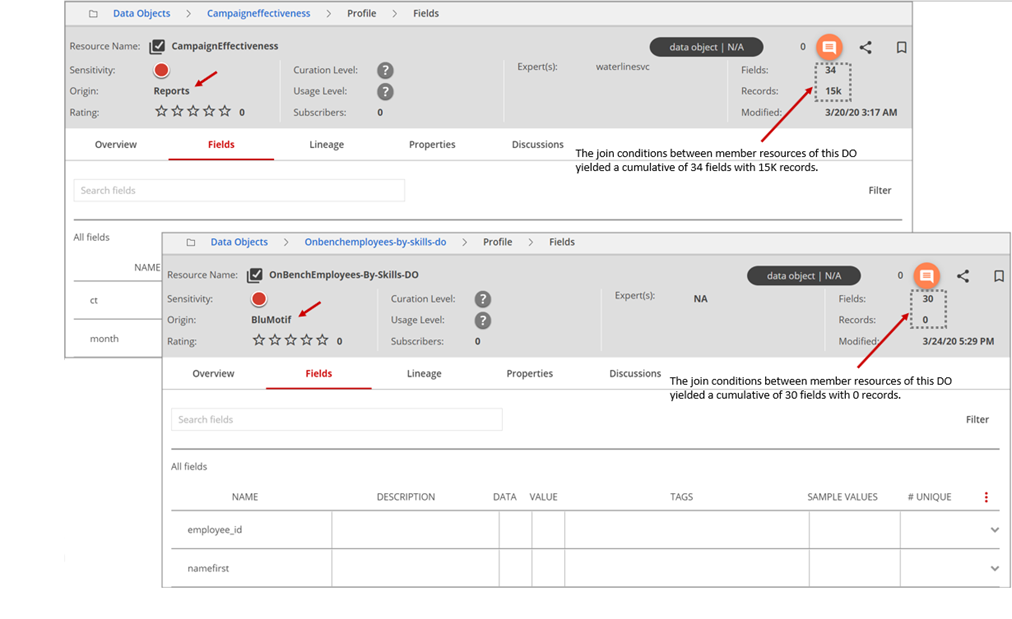
A data object's metadata profile combines the data profiles of the participating resources, reflecting success or fail of the join conditions involved in its creation. In the example below, the CampaignEffectiveness resource shows that the join conditions between member resources of the data object yielded a cumulative of 34 fields with 15,000 records. The OnBenchEmployees-By-Skills resource shows that the join conditions between member resources of the data object yielded a cumulative of 30 fields with 0 records.