Installing Lumada Data Catalog on Azure HDInsight

You can install Lumada Data Catalog on Microsoft® Azure™ HDInsight™ to access your Azure data. This type of installation is supported for HDInsight versions 3.4, 3.5, and 3.6.
Deployment architecture
As a best practice, you should install Lumada Data Catalog in the following typical deployment architecture for Azure HDInsight.
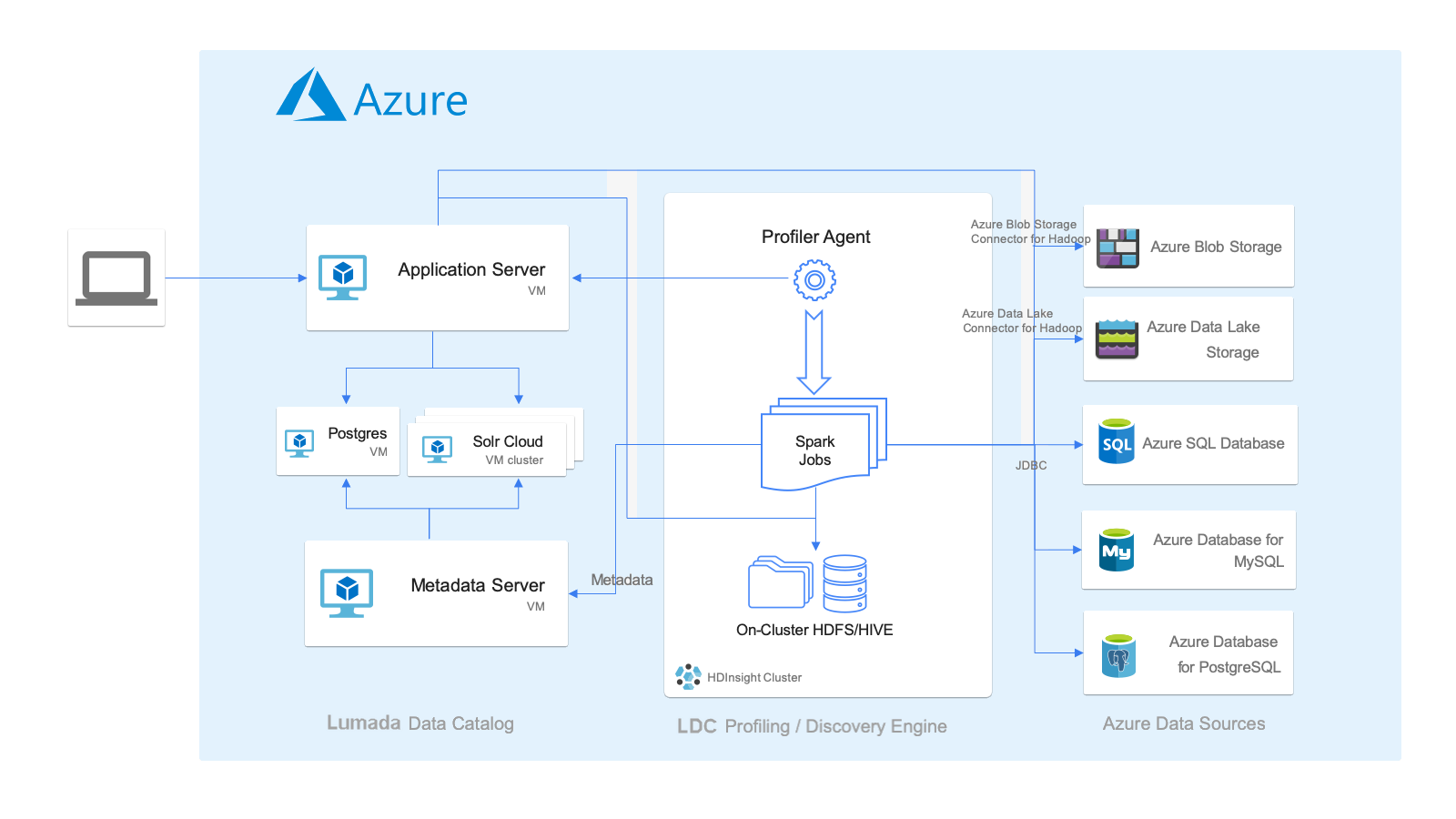
This deployment architecture contains the following key aspects of the Data Catalog installation within this environment:
- Data Catalog hosts the Lumada Data Catalog Application Server, Lumada Data Catalog Metadata Server, Solr, and Postgres components in a dedicated set of virtual machines (VMs). For sizing, see Minimum node requirements). End users connect to the LDC Application Server endpoint to access Data Catalog.
- An edge node of the HDInsight cluster hosts the Lumada Data Catalog Agent, which is responsible for data discovery using Spark jobs and publishing the metadata back to the centralized catalog, using the LDC Metadata Server endpoint.
- Both the LDC Application Server and the Discovery (LDC Agent) components connect to various data sources in the Azure cloud environment.
Networking and performance considerations
As you plan to install Lumada Data Catalog, remember the following networking and performance considerations:
- The HDInsight Cluster must be in a region closest to where the data is located. For example, if your Azure Storage Container is in the us-west-2 region, the HDInsight Cluster should be in the same region for high bandwidth and low latency access to the data. While it is possible to have cross region or zone access to data, performance will be severely affected.
- All components of the centralized Data Catalog must be co-located in the same network subnet. The Lumada Data Catalog Application Server and Lumada Data Catalog Metadata Server need low latency access to Solr and Postgres.
- If all your data is in a single region or zone, all the Data Catalog components must be co-located in the same region or zone for best performance. You can deploy the Data Catalog components in a different region or zone from the HDInsight cluster if you have multiple HDInsight clusters in different regions.
Before you begin
Before you begin installing Lumada Data Catalog on Azure HDInsight, you must create Azure resources and install Solr and Postgres.
Create Azure resources
Procedure
Create a service user named
ldcuserto act on behalf of Lumada Data Catalog. See Configure the Data Catalog service user for more information.Grant the
ldcuseruser access to your data.Create virtual machines (VMs) to host the Lumada Data Catalog Application Server and the Lumada Data Catalog Metadata Server. See Minimum node requirements.
Create an HDInsight cluster using Azure Portal or Azure CLI. For specifications and sizing, see Minimum node requirements.
Create or designate a folder in any blob or data lake storage container to store Data Catalog fingerprints (large properties) and grant read, write, and execute access to the
ldcuseruser.
Downloading and installing Solr
Download and install Solr by performing the Solr installation instructions detailed in Installing Solr.
Downloading and installing Postgres
You can use any PostgresSQL instance available in the same network subnet or region. The following options are available:
- Fully managed Azure Database for PostgreSQL.
- Yum, Ubuntu, or Debian repositories.
Installing Data Catalog on HDInsight
To install Lumada Data Catalog on Azure HDInsight, you must install the following components:
Install the LDC Application Server
To connect to specific data sources, you need to download or copy additional JAR files and configure specified core-site.xml properties. Follow the general installation instructions for the Install the Lumada Data Catalog Application Server installation, selecting the applicable procedure for the Azure storage type you are using:
- Complete the Linux section of the installation.
- Download or copy additional JAR files and configure properties in the
core-site.xml file in the following topics:
- Update the Hive server.
- Select the procedure you need for your requirements:
- Start the browser-based installation.
Instead of editing the file directly, you should make any changes to the core-site.xml file through Ambari's Hadoop configuration.
Update the Hive server
Perform the following steps to update your Hive server guava JAR version:
Procedure
Update the guava JAR version under
/usr/hdp/2.6.5.xxxx-xx/hive/lib/.Restart Hive services.
Install Data Catalog with Azure blob storage
Procedure
Obtain the access keys for a particular storage account from the storage account page on Azure Portal.
Obtain the relevant JAR files.
If the Lumada Data Catalog Application Server is running on an edge node, soft link the JARs from an existing location within the cluster:
ln -s /usr/hdp/2.6.5.3015-8/hadoop/hadoop-azure-2.7.3.2.6.5.3015-8.jar app-server/ext/.ln -s /usr/hdp/2.6.5.3015-8/hadoop/lib/azure-storage-7.0.0.jar app-server/ext/.ln -s /usr/hdp/2.6.5.3015-8/hadoop/lib/jetty-util-6.1.26.hwx.jar app-server/ext/.If the LDC Application Server is running on a standalone VM, use the wget command to download these JARs:
wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-azure/2.9.2/hadoop-azure-2.9.2.jar -P /opt/ldc/app-server/extwget https://repo1.maven.org/maven2/com/microsoft/azure/azure-storage/8.4.0/azure-storage-8.4.0.jar -P /opt/ldc/app-server/extCreate a core-site.xml file or update an existing file with the following content as shown below:
NoteInstead of directly editing the file, you should make any changes to the core-site.xml file through Ambari's Hadoop configuration.<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.azure.account.key.wlddemodata.blob.core.windows.net</name> <value>fcbC6r7tc6NEtvD8xrIlrWF6Vg9fbGKpWtq82pIGTwr4KL70Dw2bra4GYB04oZ4JNOd1Wv0GRQ+cJA7Yws223A==</value> </property> </configuration>Restart the LDC Application Server using the following command:
/opt/ldc/app-server/bin/app-server restart
Install Data Catalog with Azure Data Lake storage
Procedure
Obtain the values for
fs.adl.oauth2.refresh.url,fs.adl.oauth2.client.id, andfs.adl.oauth2.credentialfrom the "App registrations" section of Azure Portal.Download the JAR files:
wget https://repo1.maven.org/maven2/com/microsoft/azure/azure-data-lake-store-sdk/2.2.3/azure-data-lake-store-sdk-2.2.3.jar -P /opt/ldc/app-server/extwget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-azure-datalake/2.9.2/hadoop-azure-datalake-2.9.2.jar -P /opt/ldc/app-server/extCreate a core-site.xml file or update an existing file with the following content as shown below:
NoteInstead of directly editing the file, you should make any changes to the core-site.xml file through Ambari's Hadoop configuration.<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.adl.oauth2.access.token.provider.type</name> <value>ClientCredential</value> </property> <property> <name>fs.adl.oauth2.refresh.url</name> <value>https://login.microsoftonline.com/e5b7f5fb-bc52-6f89-a9c0-8cea54efd353/oauth2/token</value> </property> <property> <name>fs.adl.oauth2.client.id</name> <value>ae1b6a50-df15-40d4-b743-0be4e1bb3c00</value> </property> <property> <name>fs.adl.oauth2.credential</name> <value>2dahEXI.hgnckvFr2yoPpVFRf7?DG9-+</value> </property> </configuration>After making these changes, restart the LDC Application Server:
/opt/ldc/app-server/bin/app-server restart
Install Data Catalog with Azure Data Lake Storage Gen2
Perform the following steps to install Lumada Data Catalog on Azure HDInsight with Azure Data Lake Storage Gen2:
Procedure
Obtain the account keys from the Access keys section of the storage account on Azure Portal.
Replace Hadoop 2 JAR files with Hadoop 3 JAR files:
mv /opt/ldc/app-server/ext/hadoop /opt/ldc/app-server/ext/hadoop2 mkdir /opt/ldc/app-server/ext/hadoop wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-annotations/3.2.1/hadoop-annotations-3.2.1.jar -P /opt/ldc/app-server/ext/hadoop wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-auth/3.2.1/hadoop-auth-3.2.1.jar -P /opt/ldc/app-server/ext/hadoop wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-common/3.2.1/hadoop-common-3.2.1.jar -P /opt/ldc/app-server/ext/hadoop wget https://repo1.maven.org/maven2/org/wildfly/openssl/wildfly-openssl/1.0.7.Final/wildfly-openssl-1.0.7.Final.jar -P /opt/ldc/app-server/ext wget https://repo1.maven.org/maven2/org/apache/commons/commons-configuration2/2.6/commons-configuration2-2.6.jar -P /opt/ldc/app-server/ext
Create a core-site.xml file or update an existing file with the following content as shown below:
NoteInstead of directly editing the file, you should make any changes to the core-site.xml file through Ambari's Hadoop configuration.<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.azure.account.key.wlddemodatagen2.dfs.core.windows.net</name> <value>avd88wg3UbyxangrPZFM9fQPIpypLxTGNNJQ7Ux+NYCwPRxlJ8UhPVDEfFLbvoECHypwiFj2zZisUTwRt+rAsw==</value> </property> </configuration>After making these changes, restart the LDC Application Server:
/opt/ldc/app-server/bin/app-server restart
Installing the LDC Metadata Server
Install the Lumada Data Catalog Metadata Server by performing the general installation instructions for the Install the Lumada Data Catalog Metadata Server.
Installing the LDC Agent
Perform the general installation instructions for Install Lumada Data Catalog Agents.
To connect to specific data sources, you need to download and copy additional JAR files and configure specified core-site.xml properties for the LDC Agent. Because the LDC Agent resides on the HDI cluster, you can add the path to the cluster's JAR files and core-site.xml file to the LDC Agent's CLASSPATH variable.